
Pythonライブラリ(ファイルのデータ抽出):PyMuPDF

1.概要
各ファイルからデータ抽出するライブラリ”PyMuPDF”を紹介します。
PyMuPDFは、C言語で開発された高性能なPDFレンダリングエンジンであるMuPDFを基盤にして構築されたPythonライブラリです。
PDFだけでなく、画像ファイルやXPS、CBZ(コミック形式)など多彩なファイル形式を扱うことができ、以下のような機能が充実しています。
ドキュメントの読み込み・レンダリング
テキスト抽出・検索
画像の抽出・挿入
注釈(Annotations)の操作
その他の編集機能

1-1.PyMuPDFの派生パッケージ
PyMuPDF はPDF (およびその他の)のドキュメントのデータ抽出、分析、変換、操作が可能です。PyMuPDF には機能に応じて複数のモデルがあります。
PyMuPDF :通常版
PyMuPDF4LLM:LLM(大規模言語モデル)やRAG(Retrieval-Augmented Generation)向けに、抽出データをMarkdownやLlamaIndex形式で出力する機能を持つ拡張版
PyMuPDF Pro:商用向けの拡張ライブラリで、Officeファイル(doc/docx、xls/xlsx、ppt/pptx、hwp/hwpx など)にも対応。テーブル抽出や文書変換などが可能。
Enables Office document handling, including doc, docx, hwp, hwpx, ppt, pptx, xls, xlsx, and others.
Supports text and table extraction, document conversion and more.
Includes the commercial version of PyMuPDF4LLM.
1-2.ライブラリの比較
PythonでPDFを扱う他のライブラリは下記の通りです。
pdfrw:Python library and utility that reads and writes PDF files
PyPDF2:pure-python PDF library capable of splitting, merging, cropping, and transforming the pages of PDF files
PikePDF:C++ ライブラリ QPDF に基づいた Python パッケージで、 PDFrw に類似している
PDFMiner:text extraction tool for PDF documents
pdfplumber:Plumb a PDF for detailed information about each text character, rectangle, and line.
unstructured:ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more.
XPDF:複数の機能を備えたコマンドラインユーティリティ
PDF2JPG:PDF ページを JPG 画像にレンダリングすることに特化した Python パッケージ
一部のライブラリにおける機能比較表$${^{※}}$$は下記の通りです。PyMuPDFはレンダリングや注釈付け、低レベルなPDF操作にも強い特徴があります。
※あくまでもPyMuPDF視点のため、実際の要件に応じて他ツールと使い分けが必要

1-3.ライセンス
PyMuPDFとMuPDFは、AGPL(Affero GNU General Public License) と 商用ライセンスのデュアルライセンス形態をとっています。
AGPL: 非商用利用などで、ソースコードを開示できる場合にそのまま使用可
商用ライセンス:ソースコード非開示・商用利用などのために Artifex Software Inc. と契約を行う。

2.環境構築
2-1.インストール
最も手軽な方法は pip を使うインストールです。公式Docsでは仮想環境内での実施を推奨しています(私はそのまま実施しました)。
今回はPyMuPDFとPyMuPDF4LLMをインストールしました。
[Terminal]
pip install PyMuPDF
pip install pymupdf4llmPyMuPDF4LLMにおいて後述するLlamaindexを使用する場合は合わせてpip llama_indexのインストールが必要です。
[Terminal]
pip install llama_index2-2.サンプルファイルの取得
動作テスト用ファイルを準備しました。
PyMuPDFは複数ファイルに対応できるため、複数種のファイルを"data"フォルダ内に保存しました。またPyMuPDFで作成するファイル用に"output"フォルダを作成しておきました。

PDF(.pdf)
WORD(.doc, .docx)
横断型基幹科学技術研究団体連合:sample2020.docx
EXCEL(.xls, .xlsx)
グリーン・トランスフォーメーション技術区分表(GXTI):GXTI(GX技術区分表)(特許検索式含むエクセル版)(エクセル:85KB)
POWERPOINT(.ppt, .pptx)
CSV(.csv)
J-PlatPatから地熱発電の特許検索(取得方法は”Pythonでやってみた14:特許情報の可視化”参照)
4.QuickStart1:PyMuPDF
まずは公式Docsから簡易に実装し、アウトプットを確認していきます
初めにライブラリをインポートしますが記法は下記2種類あります。公式では特に推奨はされていないためpymupdfを使用しました。
import pymupdf
import fitz
【参考:fitzという名前の歴史】
下記の通り

【参考:ファイルパス抽出用の自作クラス作成】
保存したファイルが選択しやすいようクラスを作成しました。”ファイルの保存ディレクトリ”と”ファイル名”を指定することでファイルPath一覧を取得できます(ファイル名はDocstringに記載)。
[IN]
import os, glob
import pymupdf
class FileSelector:
'''
ファイルの種類からglobでファイルを選択する。
Filetypeの種類は以下から選択
WORD:doc, docs
EXCEL:xls, xlsx, xlsm
POWERPOINT:ppt, pptx
PDF:pdf
CSV:csv
'''
def __init__(self, dirname:str):
self.dirname = dirname
self.filetype = ['WORD', 'EXCEL', 'POWERPOINT', 'PDF', 'CSV']
#格納用リスト
self.list_WORD = []
self.list_EXCEL = []
self.list_POWERPOINT = []
self.list_PDF = []
self.list_CSV = []
def update_files(self):
self.list_WORD = glob.glob(os.path.join(self.dirname, '*.doc')) + glob.glob(os.path.join(self.dirname, '*.docx'))
self.list_EXCEL = glob.glob(os.path.join(self.dirname, '*.xls')) + glob.glob(os.path.join(self.dirname, '*.xlsx')) + glob.glob(os.path.join(self.dirname, '*.xlsm'))
self.list_POWERPOINT = glob.glob(os.path.join(self.dirname, '*.ppt')) + glob.glob(os.path.join(self.dirname, '*.pptx'))
self.list_PDF = glob.glob(os.path.join(self.dirname, '*.pdf'))
self.list_CSV = glob.glob(os.path.join(self.dirname, '*.csv'))
def __call__(self, filetype:str):
self.update_files() #ファイルリストの更新
#ファイルリストの取得
if filetype == 'WORD':
return self.list_WORD
elif filetype == 'EXCEL':
return self.list_EXCEL
elif filetype == 'POWERPOINT' or filetype == 'PP':
return self.list_POWERPOINT
elif filetype == 'PDF':
return self.list_PDF
elif filetype == 'CSV':
return self.list_CSV
else:
raise ValueError(f'ファイルタイプは{self.filetype}のいずれかを選択してください。')
fileseletor = FileSelector(dirname='data')
paths_WORD = fileseletor('WORD')
paths_PDF = fileseletor('PDF')
paths_EXCEL = fileseletor('EXCEL')
paths_PP = fileseletor('PP')
paths_CSV = fileseletor('CSV')
print(f'ファイル数:WORD={len(paths_WORD)}, PDF={len(paths_PDF)}, EXCEL={len(paths_EXCEL)}, POWERPOINT={len(paths_PP)}, CSV={len(paths_CSV)}')[OUT]
ファイル数:WORD=1, PDF=3, EXCEL=2, POWERPOINT=1, CSV=14-1.テキスト抽出(PDF)
PDFファイルからget_text()でテキストデータを抽出できます。結果は十分に情報を取得できていると思います。
[API]
get_text(option, *, clip=None, flags=None,
textpage=None, sort=False, delimiters=None)実装フローは下記の通りです。
PDFのパス取得
PyMuPDFでドキュメントを開く:pymupdf.open()
出力にはテキストやページ情報を含む
ページごとに情報を含むためfor文などで各ページの情報抽出可
Pythonのopen()でバイナリ書き込みを用意し、PyMuPDFで取得したデータをfor文で各ページごとに処理
各ページの終わりで、別途改ページを手動で追加
[IN]
#PDFファイルのパス
path_pdf = paths_PDF[0]
print(f'ファイル名:{os.path.basename(path_pdf)}')
#ドキュメントを開く
doc_pdf = pymupdf.open(path_pdf)
print(type(doc_pdf)) #ドキュメントの型を表示
print('ページ数:', len(doc_pdf)) #ドキュメントのページ数を表示
#ファイルを開く
out = open('output/output.txt', 'wb') #空のファイルを開く(wb:書き込み+バイナリモード)
#ページごとにテキストを取得
for page in doc_pdf:
text = page.get_text().encode('utf-8') #テキストをbytes型で取得
out.write(text) #テキストを書き込む
out.write(bytes((12,))) #改ページ
out.close()[OUT]
ファイル名:2024_basicpolicies_ja.pdf
<class 'pymupdf.Document'>
ページ数: 57
別のPDFファイルでも試してみました。下記では1ページ目のみ抽出し、Byte型ではなくテキストで直接取得しました。
結果としてテキストの順番がPPの表示と異なっています。おそらくPPで作成したためオブジェクト順に抽出していると想定されます。
[IN]
#PDFファイルのパス
path_pdf = paths_PDF[-1]
print(f'ファイル名:{os.path.basename(path_pdf)}')
doc_pdf = pymupdf.open(path_pdf) #ドキュメントを開く
page = doc_pdf[0] #1ページ目を取得
text = page.get_text()
print(text)[OUT]
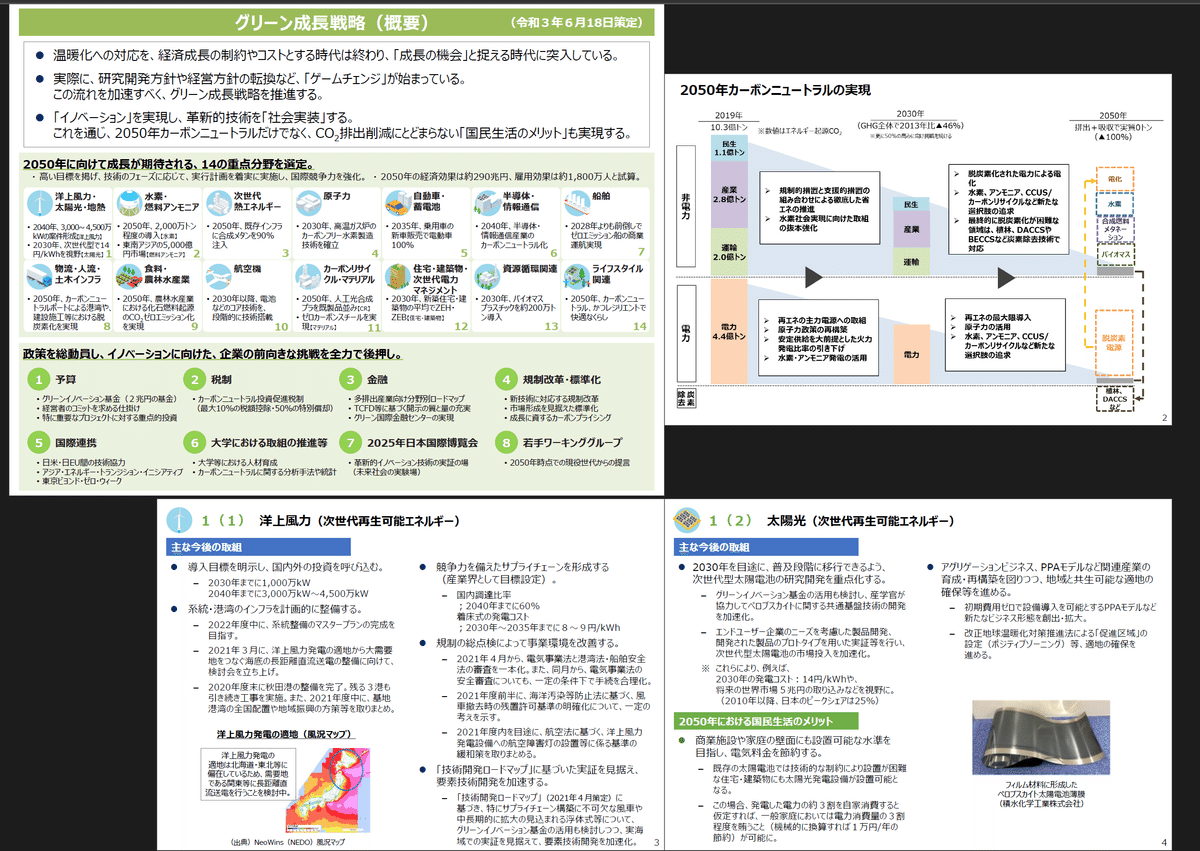
ファイル名:green_koho_r2.pdf
• グリーンイノベーション基金(2兆円の基金)
• 経営者のコミットを求める仕掛け
• 特に重要なプロジェクトに対する重点的投資
政策を総動員し、イノベーションに向けた、企業の前向きな挑戦を全力で後押し。
グリーン成長戦略(概要)
温暖化への対応を、経済成長の制約やコストとする時代は終わり、「成長の機会」と捉える時代に突入している。
実際に、研究開発方針や経営方針の転換など、「ゲームチェンジ」が始まっている。
この流れを加速すべく、グリーン成長戦略を推進する。
「イノベーション」を実現し、革新的技術を「社会実装」する。
これを通じ、2050年カーボンニュートラルだけでなく、CO2排出削減にとどまらない「国民生活のメリット」も実現する。
予算
税制
金融
規制改革・標準化
国際連携
1
2
洋上風力・
太陽光・地熱
3
4
5
水素・
燃料アンモニア
次世代
熱エネルギー
原子力
自動車・
蓄電池
半導体・
情報通信
船舶
食料・
農林水産業
航空機
カーボンリサイ
クル・マテリアル
資源循環関連
物流・人流・
土木インフラ
2
3
4
~~以下省略~~
4-2.画像抽出(PDF)
get_images()によりPDFの全ページから画像抽出が可能です。
[API]
get_images(full=False)実装フローは下記の通りです。
画像保存用の準備
親フォルダはImageとし、その中にファイル名のフォルダを作る
ファイル名のフォルダ内に取得した画像をpage_画像数で保存
PyMuPDFでドキュメントを開く:pymupdf.open()
出力にはテキストやページ情報を含む
ページごとに情報を含むためfor文などで各ページの情報抽出可
for 文で各ページを処理
スライスでページ情報を取得し、get_images()で画像データ抽出
画像データがある場合は追加処理
画像のXREF(クロスリファレンス)を取得
Pixmapを作成し、これを保存
データ保存
1で準備したフォルダ、ファイル名を使用して保存
[IN]
#ファイルPath+データ保存の準備
path_pdf = paths_PDF[-1] #PDFファイルのパス
_filename = os.path.basename(path_pdf)
filename = _filename.split('.')[0] #画像保存用
#画像保存用フォルダ作成
dirname_Image = 'Image'
if not os.path.exists(dirname_Image):
os.makedirs(dirname_Image)
#ドキュメントを開く
doc_pdf = pymupdf.open(path_pdf)
print(f'ファイル:{_filename} ページ数:{len(doc_pdf)}')
for num_page in range(len(doc_pdf)):
page = doc_pdf[num_page]
image_list = page.get_images()
#ページ内に画像がある場合
if image_list:
print(f'ページ:{num_page+1} 画像数:{len(image_list)}')
else:
print(f'ページ:{num_page+1} 画像なし')
#Image_listから画像を取得
for img_idx, img in enumerate(image_list, start=1):
xref = img[0] #画像のXREF(クロスリファレンス)を取得
pix = pymupdf.Pixmap(doc_pdf, xref) #Pixmapを作成
if pix.n - pix.alpha >3: #色情報がCMYK(4成分)の場合はRGBに変換
pix = pymupdf.Pixmap(pymupdf.csRGB, pix)
#画像の保存
if not os.path.exists(f'{dirname_Image}/{filename}'):
os.makedirs(f'{dirname_Image}/{filename}')
path_name = f'{dirname_Image}/{filename}/page{num_page+1}_img{img_idx}.png' #PNG形式で保存
pix.save(path_name)
pix = None #解放[OUT]
ファイル:green_koho_r2.pdf ページ数:29
ページ:1 画像数:14
ページ:2 画像数:1
ページ:3 画像数:2
ページ:4 画像数:2
ページ:5 画像数:3
ページ:6 画像数:1
ページ:7 画像数:1
ページ:8 画像数:1
ページ:9 画像数:11
ページ:10 画像数:1
ページ:11 画像数:2
ページ:12 画像数:5
ページ:13 画像数:1
ページ:14 画像数:2
ページ:15 画像数:1
ページ:16 画像数:1
ページ:17 画像数:1
ページ:18 画像数:3
ページ:19 画像数:11
ページ:20 画像数:2
ページ:21 画像数:1
ページ:22 画像なし
ページ:23 画像なし
ページ:24 画像なし
ページ:25 画像なし
ページ:26 画像数:1
ページ:27 画像なし
ページ:28 画像数:1
ページ:29 画像なし
結果は下記の通りであり綺麗に画像データ取れていると思います。
1Pageは各分野の画像14枚が正しく取得
2Pageは、データ自体が画像だったためそのまま取得
3Pageは左上の小さな風車と風況マップの2つを取得
他ページも同様です
【参考:ページ情報の確認】
動作を確認するために、2ページ目(画像が1枚のページ)で出力を確認しました。詳細はAPI参照のこと。
[IN]
page2 = doc_pdf[1] #2ページ目を取得
print(f'{page2}')
print(len(page2.get_images()))
image_list = page2.get_images()
print(image_list)
xref = image_list[0][0] #画像のXREF(クロスリファレンス)を取得
print(f'XREF:{xref}')
pix = pymupdf.Pixmap(doc_pdf, xref) #Pixmapを作成
print(pix)[OUT]
page 1 of data\green_koho_r2.pdf
1
[(4, 3, 1577, 991, 8, 'DeviceRGB', '', 'Image14', 'FlateDecode')]
XREF:4
Pixmap(DeviceRGB, (0, 0, 1577, 991), 1)【参考:XREF、Pixmapとは】
XREF(クロスリファレンステーブル)とは文章内のオブジェクトに簡単にアクセスできるによう参照場所のデータを保持したテーブルです。
Pixmap(ピクスマップ)とは、絵や文字などの図形をオブジェクトとして扱うための構造体です。
4-3.ベクトルグラフィック抽出(PDF)
下記により、ページ上で見つかったすべてのベクター図形のパスの辞書が返されます。
[API]
get_drawings(extended=False)[IN]
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf = paths_PDF[0] #PDFファイルのパス
#抽出処理
doc_pdf = pymupdf.open(path_pdf)
page = doc_pdf[0] #1ページ目を取得
paths = page.get_drawings() #描画情報を取得
print(f'描画情報数:{len(paths)}')
print(paths[0]) #描画情報の例
paths[OUT]
描画情報数:1
{'items': [('c', Point(379.92498779296875, 250.30010986328125), Point(376.2659912109375, 250.30010986328125), Point(373.29998779296875, 247.3341064453125), Point(373.29998779296875, 243.67510986328125)), ('l', Point(373.29998779296875, 243.67510986328125), Point(373.29998779296875, 217.17510986328125)), ('c', Point(373.29998779296875, 217.17510986328125), Point(373.29998779296875, 213.51611328125), Point(376.2659912109375, 210.55010986328125), Point(379.92498779296875, 210.55010986328125)), ('c', Point(499.8249816894531, 210.55010986328125), Point(503.4839782714844, 210.55010986328125), Point(506.4499816894531, 213.51611328125), Point(506.4499816894531, 217.17510986328125)), ('l', Point(506.4499816894531, 217.17510986328125), Point(506.4499816894531, 243.67510986328125)), ('c', Point(506.4499816894531, 243.67510986328125), Point(506.4499816894531, 247.3341064453125), Point(503.4839782714844, 250.30010986328125), Point(499.8249816894531, 250.30010986328125))], 'type': 's', 'stroke_opacity': 1.0, 'color': (0.0, 0.0, 0.0), 'width': 0.75, 'lineCap': (0, 0, 0), 'lineJoin': 1.0, 'closePath': False, 'dashes': '[] 0', 'rect': Rect(373.29998779296875, 210.55010986328125, 506.4499816894531, 250.30010986328125), 'layer': '', 'seqno': 24, 'fill': None, 'fill_opacity': None, 'even_odd': None}
[{'items': [('c',
Point(379.92498779296875, 250.30010986328125),
Point(376.2659912109375, 250.30010986328125),
Point(373.29998779296875, 247.3341064453125),
Point(373.29998779296875, 243.67510986328125)),
('l',
Point(373.29998779296875, 243.67510986328125),
Point(373.29998779296875, 217.17510986328125)),
('c',
Point(373.29998779296875, 217.17510986328125),
Point(373.29998779296875, 213.51611328125),
Point(376.2659912109375, 210.55010986328125),
Point(379.92498779296875, 210.55010986328125)),
('c',
Point(499.8249816894531, 210.55010986328125),
Point(503.4839782714844, 210.55010986328125),
Point(506.4499816894531, 213.51611328125),
Point(506.4499816894531, 217.17510986328125)),
('l',
Point(506.4499816894531, 217.17510986328125),
Point(506.4499816894531, 243.67510986328125)),
('c',
Point(506.4499816894531, 243.67510986328125),
Point(506.4499816894531, 247.3341064453125),
Point(503.4839782714844, 250.30010986328125),
Point(499.8249816894531, 250.30010986328125))],
'type': 's',
'stroke_opacity': 1.0,
'color': (0.0, 0.0, 0.0),
'width': 0.75,
'lineCap': (0, 0, 0),
'lineJoin': 1.0,
'closePath': False,
'dashes': '[] 0',
'rect': Rect(373.29998779296875, 210.55010986328125, 506.4499816894531, 250.30010986328125),
'layer': '',
'seqno': 24,
'fill': None,
'fill_opacity': None,
'even_odd': None}]4-5.PDF操作
PyMuPDFでは様々なPDF操作が可能であり、例は下記の通りです。本節で一部の処理を紹介します。
4-5-1.PDFファイルの結合
PyMuPDFではinsert_file()でPDFの結合も可能です。
[API]
insert_file(infile, from_page=-1, to_page=-1, start_at=-1,
rotate=-1, links=True, annots=True, show_progress=0, final=1)縦向きと横向きのファイルを結合してもページの向きは維持したまま結合可能です。
[IN]
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf_1 = paths_PDF[0] #PDFファイルのパス
path_pdf_2 = paths_PDF[1] #PDFファイルのパス
doc_pdf_1 = pymupdf.open(path_pdf_1) #PDFファイルを開く
doc_pdf_2 = pymupdf.open(path_pdf_2) #PDFファイルを開く
doc_pdf_1.insert_pdf(doc_pdf_2) #PDFファイルを結合
doc_pdf_1.save('output/output.pdf') #結合したPDFファイルを保存[OUT]
-
4-5-2.ウォータマーク追加
PDFにウォータマークを追加するにはPage.insert_image()を使用します。
[API]
insert_image(rect, *, alpha=-1, filename=None, height=0,
keep_proportion=True, mask=None, oc=0, overlay=True,
pixmap=None, rotate=0, stream=None, width=0, xref=0)結果の通り、本処理は基本的には各PDFページの底辺に画像を追加するだけです。綺麗に張り付けるには透明度とアスペクト比の調整が必要です。
[IN]
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf = paths_PDF[0] #PDFファイルのパス
path_img = 'konan.JPG' #猫の画像ファイル
doc = pymupdf.open(path_pdf) #PDFファイルを開く
for page_idx in range(len(doc)):
page = doc[page_idx] #ページを取得
#ページの境界に合わせて画像を挿入
page.insert_image(page.bound(),
filename=path_img,
overlay=False)
doc.save('output/output.pdf') #保存[OUT]
【参考:透かし画像の作成】
画像に透かしを入れるならPillowが便利と思います。insert_image()のAPIにalpha(透明度?)の引数がありますが非推奨です。
実装手順としては下記の通りです。
Pillowを用いて透かし画像をバイナリで作成
Pillowで画像を開き、RGBAモードに変換
Pillowのputalphaで透過調整
ioでバイナリIOを作成し、そこに画像データを書き込み
前回同様に画像を読み込み、ドキュメントを開き、各ページ処理
page.insert_image()にバイナリデータを与える。
バイナリデータはfilename引数ではなくstream 引数(メモリ内の画像)を使用
位置を指定したい場合は追加でrect引数を指定
[IN]
from PIL import Image
import io
def create_WaterMark(img_path:str, alpha:int=128):
im = Image.open(img_path) #画像を開く
im_RGBA = im.convert('RGBA') #RGBAモードに変換
im_RGBA.putalpha(alpha) #透過度を設定
#バイナリIOを作成
bio = io.BytesIO() #バイナリIOを作成
im_RGBA.save(bio, format='PNG') #PNG形式で保存
bio.seek(0) #先頭に移動
return bio.getvalue() #バイナリデータを取得
path_img = 'konan.JPG' #猫の画像ファイル
img_bytes = create_WaterMark(path_img, alpha=128) #透過度128の画像を作成
doc = pymupdf.open(path_pdf) #PDFファイルを開く
for page_idx in range(len(doc)):
page = doc[page_idx] #ページを取得
#ページの境界に合わせて画像を挿入
page.insert_image(page.bound(),
stream=img_bytes, #メモリ内の画像
overlay=False,
)
doc.save('output/output.pdf') #保存[OUT]
- 
4-5-3.画像追加
PDFファイルに画像追加(例:ロゴ)する場合は前項のウォーターフォールと同様にPage.insert_image()と合わせてRectを使用します。
サイズと位置を決めることでロゴや押印のように画像を張り付けることが出来ました。
[IN]
#ファイルの準備
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf = paths_PDF[0] #PDFファイルのパス
path_img = 'konan.JPG' #猫の画像ファイル
doc = pymupdf.open(path_pdf) #PDFファイルを開く
for page_idx in range(len(doc)):
page = doc[page_idx] #ページを取得
#ドキュメントの左上にロゴに様に画像を挿入
page.insert_image(pymupdf.Rect(0,0,200,200),
filename=path_img)
doc.save('output/output.pdf') #保存[OUT]
ー
4-5-4.テーブル/リンク抽出
PDFからのデータ抽出は下記の通りです。
表の抽出:Page.find_tables(),
リンクの抽出:Page.first_link()
[API]
find_tables(clip=None, strategy=None, vertical_strategy=None,
horizontal_strategy=None, vertical_lines=None, horizontal_lines=None,
snap_tolerance=None, snap_x_tolerance=None, snap_y_tolerance=None,
join_tolerance=None, join_x_tolerance=None, join_y_tolerance=None,
edge_min_length=3, min_words_vertical=3, min_words_horizontal=1,
intersection_tolerance=None, intersection_x_tolerance=None,
intersection_y_tolerance=None, text_tolerance=None,
text_x_tolerance=None, text_y_tolerance=None, add_lines=None)[API]
class Link結果は下記の通りです。
[IN]
from pprint import pprint
#ファイルの準備
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf = paths_PDF[0] #PDFファイルのパス
doc = pymupdf.open(path_pdf) #PDFファイルを開く
for page_idx, page in enumerate(doc):
print(f'{"#"*30}{page_idx+1}ページ{"#"*30}')
tabs = page.find_tables() #表を検出
print(f'表数:{len(tabs.tables)}')
link = page.first_link #リンク情報を取得
#テーブル表示
if tabs.tables:
pprint(tabs[0].extract()) #表のデータを表示
#リンク情報表示
while link:
link = link.next
if link:
print(link)[OUT]
##############################1ページ##############################
表数:0
##############################2ページ##############################
表数:0
##############################3ページ##############################
表数:0
##############################4ページ##############################
表数:0
##############################5ページ##############################
表数:0
##############################6ページ##############################
表数:0
##############################7ページ##############################
表数:0
link on page 6 of data\2024_basicpolicies_ja.pdf
##############################8ページ##############################
表数:0
##############################9ページ##############################
表数:0
##############################10ページ##############################
表数:0
##############################11ページ##############################
表数:0
link on page 10 of data\2024_basicpolicies_ja.pdf
link on page 10 of data\2024_basicpolicies_ja.pdf
link on page 10 of data\2024_basicpolicies_ja.pdf
link on page 10 of data\2024_basicpolicies_ja.pdf
##############################12ページ##############################
表数:0
##############################13ページ##############################
表数:0
link on page 12 of data\2024_basicpolicies_ja.pdf
link on page 12 of data\2024_basicpolicies_ja.pdf
link on page 12 of data\2024_basicpolicies_ja.pdf
link on page 12 of data\2024_basicpolicies_ja.pdf
link on page 12 of data\2024_basicpolicies_ja.pdf
~~以下省略~~上記では表が無かったため、別のファイルで実施しました。テーブルも抽出できていそうです。
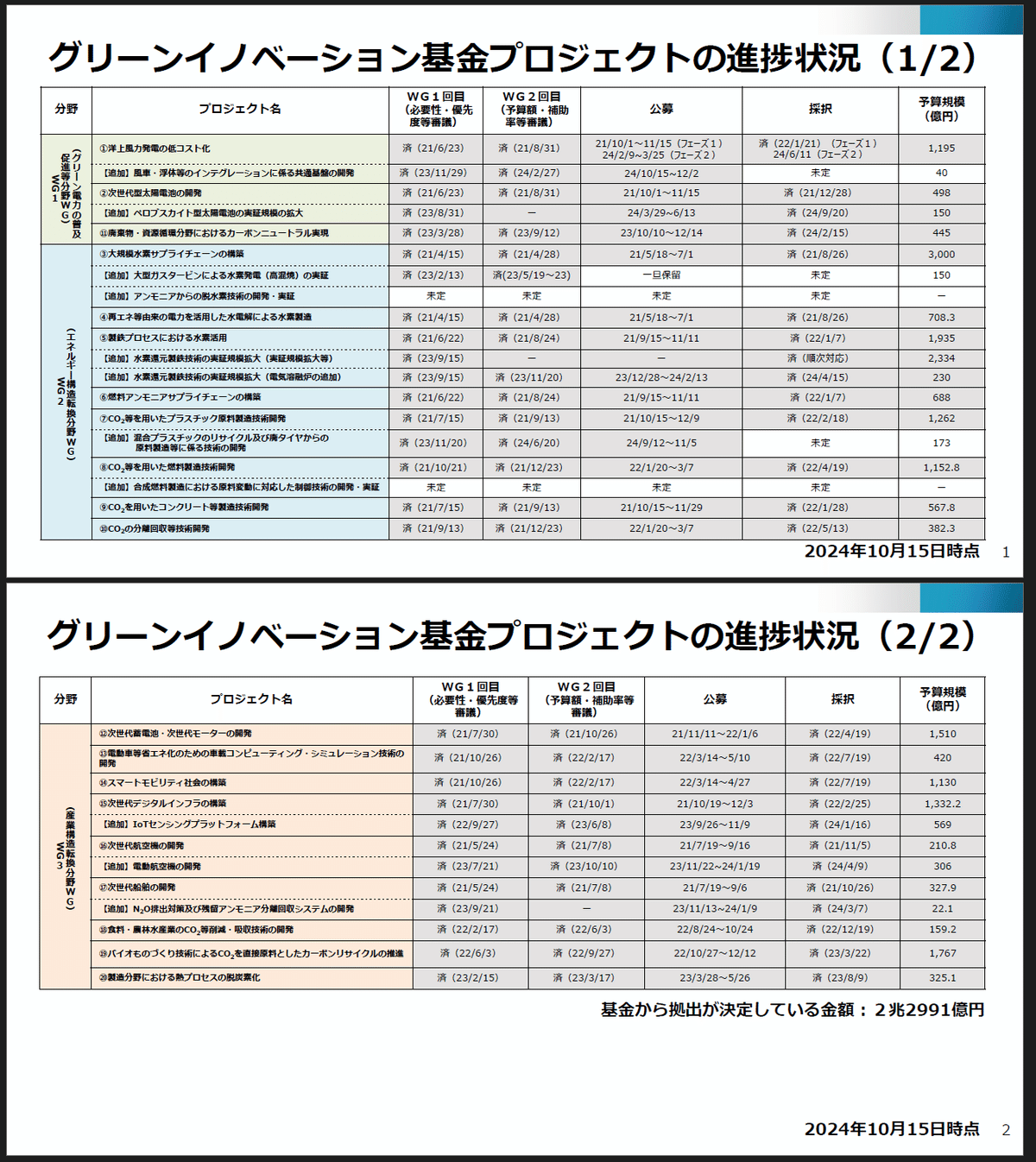
[IN]
from pprint import pprint
#ファイルの準備
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf = paths_PDF[1] #PDFファイルのパス
doc = pymupdf.open(path_pdf) #PDFファイルを開く
for page_idx, page in enumerate(doc):
print(f'{"#"*30}{page_idx+1}ページ{"#"*30}')
tabs = page.find_tables() #表を検出
print(f'表数:{len(tabs.tables)}')
link = page.first_link #リンク情報を取得
#テーブル表示
if tabs.tables:
pprint(tabs[0].extract()) #表のデータを表示
#リンク情報表示
while link:
link = link.next
if link:
print(link)[OUT]
##############################1ページ##############################
表数:1
[['分野',
'プロジェクト名',
'WG1回目\n(必要性・優先\n度等審議)',
'WG2回目\n(予算額・補助\n率等審議)',
'公募',
'採択',
'予算規模\n(億円)'],
['(\n促グ\n進リ\n等ー WG\n分ン\n1野電\nW力\nGの\n)普\n及',
'①洋上風力発電の低コスト化',
'済(21/6/23)',
'済(21/8/31)',
'21/10/1~11/15(フェーズ1)\n24/2/9~3/25(フェーズ2)',
'済(22/1/21)(フェーズ1)\n24/6/11(フェーズ2)',
'1,195'],
[None,
'【追加】風車・浮体等のインテグレーションに係る共通基盤の開発',
'済(23/11/29)',
'済(24/2/27)',
'24/10/15~12/2',
'未定',
'40'],
[None,
'②次世代型太陽電池の開発',
'済(21/6/23)',
'済(21/8/31)',
'21/10/1~11/15',
'済(21/12/28)',
'498'],
[None,
'【追加】ペロブスカイト型太陽電池の実証規模の拡大',
'済(23/8/31)',
'ー',
'24/3/29~6/13',
'済(24/9/20)',
'150'],
[None,
'⑪廃棄物・資源循環分野におけるカーボンニュートラル実現',
'済(23/3/28)',
'済(23/9/12)',
'23/10/10~12/14',
'済(24/2/15)',
'445'],
['(\nエ\nネ\nル\nギ\nー\nWG\n構\n造\n2転\n換\n分\n野\nW\nG\n)',
'③大規模水素サプライチェーンの構築',
'済(21/4/15)',
'済(21/4/28)',
'21/5/18~7/1',
'済(21/8/26)',
'3,000'],
[None,
'【追加】大型ガスタービンによる水素発電(高混焼)の実証',
'済(23/2/13)',
'済(23/5/19~23)',
'一旦保留',
'未定',
'150'],
[None, '【追加】アンモニアからの脱水素技術の開発・実証', '未定', '未定', '未定', '未定', 'ー'],
[None,
'④再エネ等由来の電力を活用した水電解による水素製造',
'済(21/4/15)',
'済(21/4/28)',
'21/5/18~7/1',
'済(21/8/26)',
'708.3'],
[None,
'⑤製鉄プロセスにおける水素活用',
'済(21/6/22)',
'済(21/8/24)',
'21/9/15~11/11',
'済(22/1/7)',
'1,935'],
[None,
'【追加】水素還元製鉄技術の実証規模拡大(実証規模拡大等)',
'済(23/9/15)',
'ー',
'ー',
'済(順次対応)',
'2,334'],
[None,
'【追加】水素還元製鉄技術の実証規模拡大(電気溶融炉の追加)',
'済(23/9/15)',
'済(23/11/20)',
'23/12/28~24/2/13',
'済(24/4/15)',
'230'],
[None,
'⑥燃料アンモニアサプライチェーンの構築',
'済(21/6/22)',
'済(21/8/24)',
'21/9/15~11/11',
'済(22/1/7)',
'688'],
[None,
'⑦CO 等を用いたプラスチック原料製造技術開発\n2',
'済(21/7/15)',
'済(21/9/13)',
'21/10/15~12/9',
'済(22/2/18)',
'1,262'],
[None,
'【追加】混合プラスチックのリサイクル及び廃タイヤからの\n原料製造等に係る技術の開発',
'済(23/11/20)',
'済(24/6/20)',
'24/9/12~11/5',
'未定',
'173'],
[None,
'⑧CO 等を用いた燃料製造技術開発\n2',
'済(21/10/21)',
'済(21/12/23)',
'22/1/20~3/7',
'済(22/4/19)',
'1,152.8'],
[None, '【追加】合成燃料製造における原料変動に対応した制御技術の開発・実証', '未定', '未定', '未定', '未定', 'ー'],
[None,
'⑨CO を用いたコンクリート等製造技術開発\n2',
'済(21/7/15)',
'済(21/9/13)',
'21/10/15~11/29',
'済(22/1/28)',
'567.8'],
[None,
'⑩CO の分離回収等技術開発\n2',
'済(21/9/13)',
'済(21/12/23)',
'22/1/20~3/7',
'済(22/5/13)',
'382.3']]
##############################2ページ##############################
表数:1
[['分野',
'プロジェクト名',
'WG1回目\n(必要性・優先度等\n審議)',
'WG2回目\n(予算額・補助率等\n審議)',
'公募',
'採択',
'予算規模\n(億円)'],
['(\n産\n業\n構\n造 WG\n転\n3換\n分\n野\nW\nG\n)',
'⑫次世代蓄電池・次世代モーターの開発',
'済(21/7/30)',
'済(21/10/26)',
'21/11/11~22/1/6',
'済(22/4/19)',
'1,510'],
[None,
'⑬電動車等省エネ化のための車載コンピューティング・シミュレーション技術の\n開発',
'済(21/10/26)',
'済(22/2/17)',
'22/3/14~5/10',
'済(22/7/19)',
'420'],
[None,
'⑭スマートモビリティ社会の構築',
'済(21/10/26)',
'済(22/2/17)',
'22/3/14~4/27',
'済(22/7/19)',
'1,130'],
[None,
'⑮次世代デジタルインフラの構築',
'済(21/7/30)',
'済(21/10/1)',
'21/10/19~12/3',
'済(22/2/25)',
'1,332.2'],
[None,
'【追加】IoTセンシングプラットフォーム構築',
'済(22/9/27)',
'済(23/6/8)',
'23/9/26~11/9',
'済(24/1/16)',
'569'],
[None,
'⑯次世代航空機の開発',
'済(21/5/24)',
'済(21/7/8)',
'21/7/19~9/16',
'済(21/11/5)',
'210.8'],
[None,
'【追加】電動航空機の開発',
'済(23/7/21)',
'済(23/10/10)',
'23/11/22~24/1/19',
'済(24/4/9)',
'306'],
[None,
'⑰次世代船舶の開発',
'済(21/5/24)',
'済(21/7/8)',
'21/7/19~9/6',
'済(21/10/26)',
'327.9'],
[None,
'【追加】N O排出対策及び残留アンモニア分離回収システムの開発\n2',
'済(23/9/21)',
'ー',
'23/11/13~24/1/9',
'済(24/3/7)',
'22.1'],
[None,
'⑱食料・農林水産業のCO 等削減・吸収技術の開発\n2',
'済(22/2/17)',
'済(22/6/3)',
'22/8/24~10/24',
'済(22/12/19)',
'159.2'],
[None,
'⑲バイオものづくり技術によるCO を直接原料としたカーボンリサイクルの推進\n2',
'済(22/6/3)',
'済(22/9/27)',
'22/10/27~12/12',
'済(23/3/22)',
'1,767'],
[None,
'⑳製造分野における熱プロセスの脱炭素化',
'済(23/2/15)',
'済(23/3/17)',
'23/3/28~5/26',
'済(23/8/9)',
'325.1']]4-6.その他
その他の操作(重複含む)はチュートリアル参照のこと。
ドキュメントのクローズ
5.QuickStart2:PyMuPDF4LLM
PyMuPDF を 大規模言語モデル(LLM) フレームワークおよび全体的な RAG(Retrieval-Augmented Generation) ソリューションに統合することで、文書データを提供する最も高速かつ信頼性の高い方法を提供します。
特徴は下記の通りです。
Markdown 形式での抽出や、 LlamaIndex ドキュメント出力もサポート
マルチカラムページのサポート
画像およびベクターグラフィックスの抽出のサポート
ページ分割出力のサポート
LlamaIndexドキュメント としての直接出力のサポート
【参考:RAG(Retrieval Augmented Generation:検索拡張生成)とは】
RAGとは自社に蓄積された大量の業務文書・規定などの社内情報、外部の最新情報を活用する手段として、信頼できるデータを検索して情報を抽出し、それに基づいて大規模言語モデル(LLM)に回答させる方法のことです。


【参考:LlamaIndexとは】
LlamaIndexは大規模言語モデル(LLM) と外部データを接続するためのインターフェースを提供します。LlamaIndex を使うと、自分の持っているデータをLLMに組み込んで、質問があった際はこのデータを参照しつつ返答を返すことができます。
5-1.Markdown形式:抽出
ドキュメント情報をMarkdown形式で抽出するにはto_markdown()を使用します。
[API]
to_markdown(doc: pymupdf.Document | str, *, pages: list | range | None = None,
hdr_info: Any = None, write_images: bool = False,
embed_images: bool = False, dpi: int = 150, image_path='',
image_format='png', image_size_limit=0.05, force_text=True,
margins=(0, 50, 0, 50), page_chunks: bool = False,
page_width: float = 612, page_height: float = None,
table_strategy='lines_strict', graphics_limit: int = None,
ignore_code: bool = False, extract_words: bool = False,
show_progress: bool = True) → str | list[dict]PyMuPDFと比較して下記のような違いが確認できました。
イテラブルではないためfor文が無くても全文を抽出
出力は文字列で抽出
体裁がよりきれい
[IN]
#ファイルの準備
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf = paths_PDF[0] #PDFファイルのパス
import pymupdf4llm
md_text = pymupdf4llm.to_markdown(path_pdf)
print(type(md_text), end='\n\n')
print(md_text)[OUT]
Processing data\2024_basicpolicies_ja.pdf...
[ ] (0/57[ ] ( 1/57[= ] ( 2/5[== ] ( 3/5[== ] ( 4/57[=== ] ( 5/5[==== ] ( 6/5[==== ] ( 7/57[===== ] ( 8/5[====== ] ( 9/57[======= ] (10/[======= ] (11/5[======== ] (12/57[========= ] (13/[========= ] (14/5[========== ] (15/57[=========== ] (16/[=========== ] (17/5[============ ] (18/57[============= ] (19/5[============== ] (20/5[============== ] (21/57[=============== ] (22/5[================ ] (23/5[================ ] (24/57[================= ] (25/5[================== ] (26/5[================== ] (27/57[=================== ] (28/5[==================== ] (29/57[===================== ] (30/[===================== ] (31/5[====================== ] (32/57[======================= ] (33/[======================= ] (34/5[======================== ] (35/57[========================= ] (36/[========================= ] (37/5[========================== ] (38/57[=========================== ] (39/5[============================ ] (40/5[============================ ] (41/57[============================= ] (42/5[============================== ] (43/5[============================== ] (44/57[=============================== ] (45/5[================================ ] (46/5[================================ ] (47/57[================================= ] (48/5[================================== ] (49/57[=================================== ] (50/[=================================== ] (51/5[==================================== ] (52/57[===================================== ] (53/[===================================== ] (54/5[====================================== ] (55/57[======================================= ] (56/57[========================================] (57/57]
<class 'str'>
経済財政運営と改革の基本方針 `2024 について`
令和6年6月 `21 日`
閣 議 決 定
経済財政運営と改革の基本方針 `2024 を別紙のとおり定める。`
-----
# (別紙)
経済財政運営と改革の基本方針 2024
~賃上げと投資がけん引する成長型経済の実現~
令和6年6月 21 日
...
----- PyMuPDFとPyMuPDFLLMで先のPDFの1ページ目を比較しました。ページの抽出はpages引数にページ数をリストで渡します。
結果としてLLMの方が、より体裁が整っていることが確認できます。
[IN]
path_pdf = paths_PDF[0] #PDFファイルのパス
import pymupdf4llm
md_text = pymupdf4llm.to_markdown(path_pdf, pages=[0])
print(md_text)[OUT]
ー
5-2.Markdown形式:保存
データの保存はPathlibを使用して指定されたファイルの内容をバイナリオブジェクトで書き込みます。
下記の通りMarkdownの拡張子でファイル保存ができ、テキストデータも抽出できました。
[IN]
#ファイルの準備
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf = paths_PDF[0] #PDFファイルのパス
import pymupdf4llm
md_text = pymupdf4llm.to_markdown(path_pdf)
import pathlib
pathlib.Path('output/output.md').write_bytes(md_text.encode())[OUT]
5-3.LlamaIndexドキュメントとして抽出
PyMuPDF4LLM は LlamaIndex ドキュメントへの直接変換をサポートしています。
抽出はLlamaMarkdownReader()でインスタンス化し、load_data()です。
[API]
LlamaMarkdownReader(*args, **kwargs)[API]
load_data(file_path: Union[Path, str], extra_info: Optional[Dict] = None,
**load_kwargs: Any) → List[LlamaIndexDocument]実行結果は下記の通りです。処理には時間がかかり約11secでした。
[IN]
#ファイルの準備
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf = paths_PDF[0] #PDFファイルのパス
import pymupdf4llm
llama_reader = pymupdf4llm.LlamaMarkdownReader()
llama_docs = llama_reader.load_data(path_pdf)
print(type(llama_docs))
print(f'LlamaIndexのドキュメント数:{len(llama_docs)}')
print(f'LlamaIndexの最初のドキュメント:{llama_docs[0]}')[OUT]
<class 'list'>
LlamaIndexのドキュメント数:57
LlamaIndexの最初のドキュメント:Doc ID: 74974e32-4574-44c7-963c-db76b05268e0
Text: 経済財政運営と改革の基本方針 `2024 について` 令和6年6月 `21 日` 閣 議 決 定
経済財政運営と改革の基本方針 `2024 を別紙のとおり定める。` -----5-4.画像データ抽出
画像抽出はテキスト抽出と同じくto_markdown()を使用します。
[API]
to_markdown(doc: pymupdf.Document | str, *, pages: list | range | None = None,
hdr_info: Any = None, write_images: bool = False,
embed_images: bool = False, dpi: int = 150, image_path='',
image_format='png', image_size_limit=0.05, force_text=True,
margins=(0, 50, 0, 50), page_chunks: bool = False,
page_width: float = 612, page_height: float = None,
table_strategy='lines_strict', graphics_limit: int = None,
ignore_code: bool = False, extract_words: bool = False,
show_progress: bool = True) → str | list[dict]to_markdown()の引数を設定するとテキストの抽出と同時に画像も抽出します。結果は下記の通りです。
引数に指定したとおり”Image”フォルダ内にpng形式で画像が出力
to_markdown()のため、戻り値はStringのテキストデータ
[IN]
#ファイルの準備
fileseletor = FileSelector(dirname='data') #dataフォルダのファイルリスト取得用
paths_PDF = fileseletor('PDF') #PDFファイルのリスト取得
path_pdf = paths_PDF[-1] #PDFファイルのパス
#画像抽出
import pymupdf
import pymupdf4llm
md_img = pymupdf4llm.to_markdown(doc=path_pdf,
write_images=True, # 画像抽出を有効化
image_path="Image", # 保存先フォルダ名
image_format="png", # or "jpg"
dpi=300, # 画像化の解像度
image_size_limit=0.05, # 小さすぎる画像はスキップ
force_text=True, # 画像上のテキストも取得したい場合は True
show_progress=False # Trueにすると進捗バーを表示
)
print(type(md_img))
print(md_img)[OUT]
<class 'str'>
## 温暖化への対応を、経済成長の制約やコストとする時代は終わり、「成長の機会」と捉える時代に突入している。
実際に、研究開発方針や経営方針の転換など、「ゲームチェンジ」が始まっている。
この流れを加速すべく、グリーン成長戦略を推進する。
「イノベーション」を実現し、革新的技術を「社会実装」する。
これを通じ、2050年カーボンニュートラルだけでなく、CO 排出削減にとどまらない「国民生活のメリット」も実現する。
###### 2
### 政策を総動員し、イノベーションに向けた、企業の前向きな挑戦を全力で後押し。
1 予算 2 税制 3 金融 4 規制改革・標準化
- グリーンイノベーション基金(2兆円の基金)
- 経営者のコミットを求める仕掛け
- 特に重要なプロジェクトに対する重点的投資
### 5 国際連携
...
-----
~以下省略~
6.QuickStart3:PyMuPDF Pro
PyMuPDF Proは商業拡張用でありOfficeのサポート等に使用され、またライセンス版のPyMuPDF4LLMを提供します。
こちらは有償のため参考リンクのみ紹介します。
7.使用方法ガイド
使用方法ガイドは公式Docsがしっかりしているため下記参照。
8.API:クラス
PyMuPDFのクラスのAPIの一覧は下記の通り。詳細は公式Docs参照
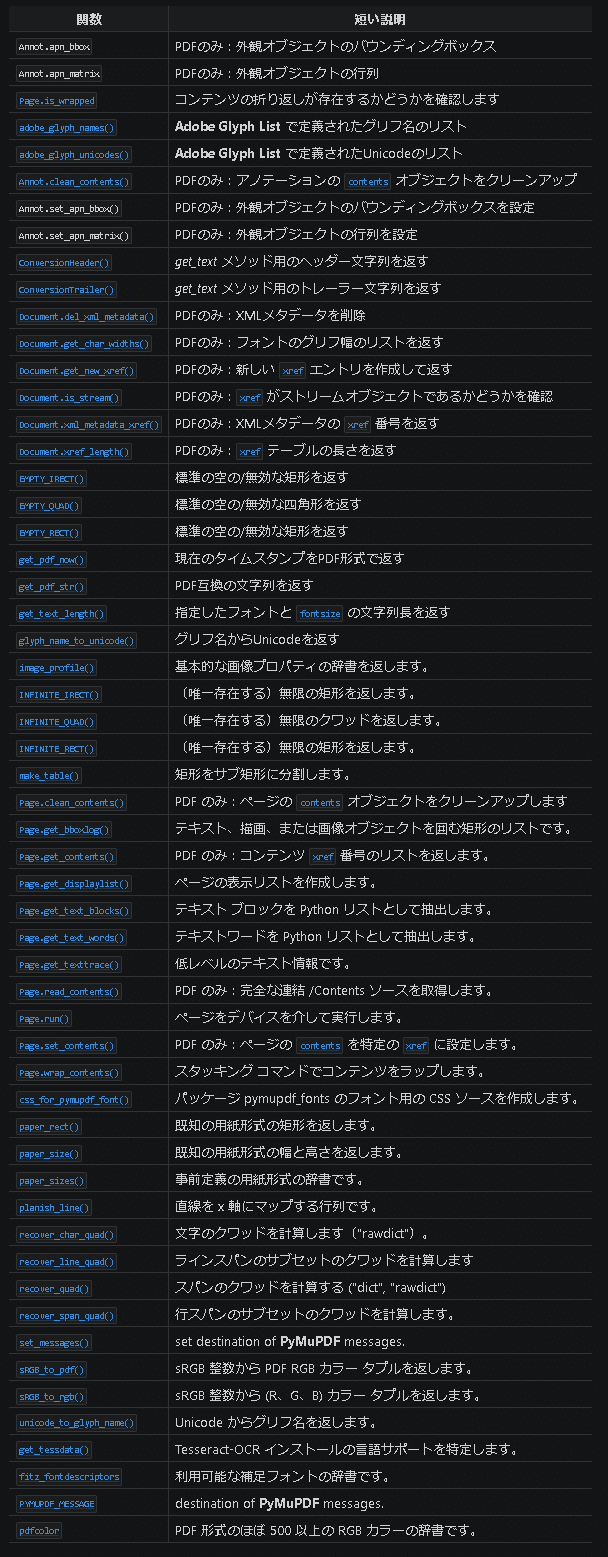
9.API:低レベル関数
低レベル(コンピュータのハードウェアやアーキテクチャに直接アクセス)な技術的詳細に関するさまざまな関数と属性です。低レベルのため、より多くの情報を抽出可能です。
参考資料
公式
https://readthedocs.org/projects/pymupdf/downloads/pdf/latest/
技術ブログ
Python
あとがき
近い将来PDFや他のファイルからテキストや画像データを抽出し、その情報をLLMに突っ込んで、クラウドでもローカルでも処理してくれる時代が近づいてそう。
とにかく特許がめんどくさいので、この手のことを自動化できると本当に負担が数%くらい減りそう。