
Pythonでやってみた17:車両緒言の比較表

1.概要
車を①複数車種、②自分が欲しい情報のみ抽出、③別情報(コスト、乗り心地)の追加ができるアプリを見つけきれなかったため、簡易の比較用スクリプトを作成しました。
2.設計思想
スクリプトの設計思想を説明します。
2-1.車両緒言(基本データ)
基本データ(排気量、重量、トルクなど)は各社ページから取得することもできますが、用語の統一性がなくスクレイピング方法も変わるため非常に手間です。そこで①簡単に情報がとれ、②統一感があり、③情報量が多い サイトであるグーネットを利用します。
型式まで選択すると緒言表が得られるためこちらを利用しました。
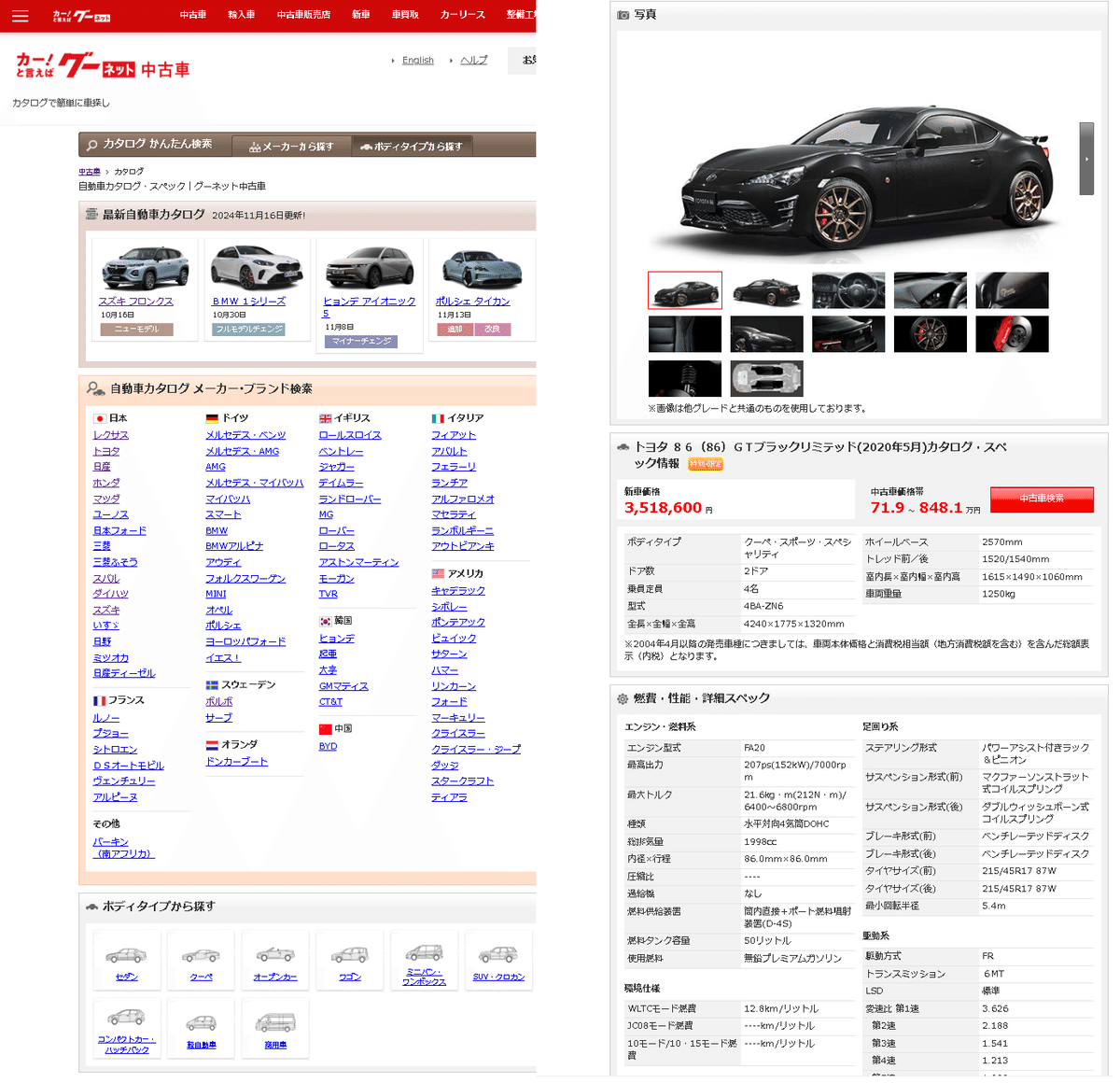
2-2.追加データ
車両緒言に無く、追加したい情報として下記のようなものがあります。
コスト
乗り心地
リードタイム(納期)
最終的にはテーブル形式で表を作成します。追加する項目を加味して、これらの項目を含めたExcelを手動で入力したいと思います。
2-3.前処理の有無
最終的なアウトプットとしては比較表を作成していきたいと思います。比較表にするには文字列情報は全て数値(int, floatなど)に変換が必要なため、欲しい情報は前処理を入れます。
3.事前準備:Excel入力
スクリプト作成前に必要な情報をExcelに入力していきます。
ファイルのイメージは下記の通りです。
ファイル名:desc_data.xlsx
列(Column):車両名(※Pandas用のため適当な名前でOK)
行(Index):自分が追加したい情報(※スクリプトに合わせて命名)
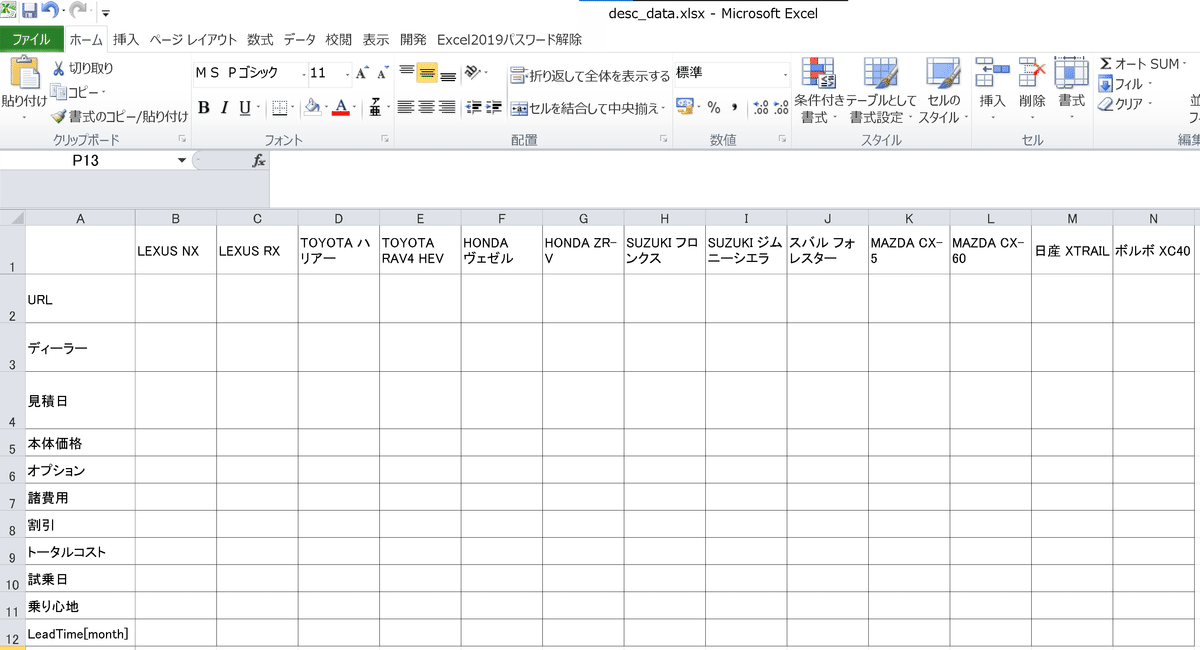
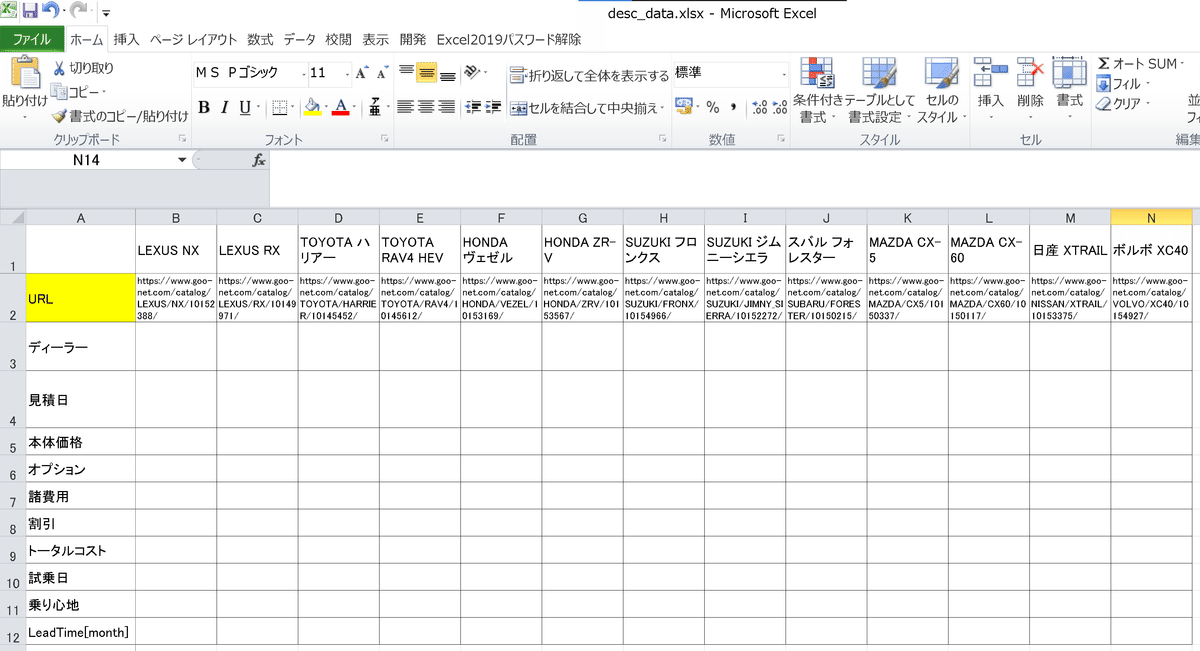
3-1.URLの追加
先ほどの「グーネットカタログ」から比較したい車の型式まで選択し、そのページのURLを下図のように入力します。
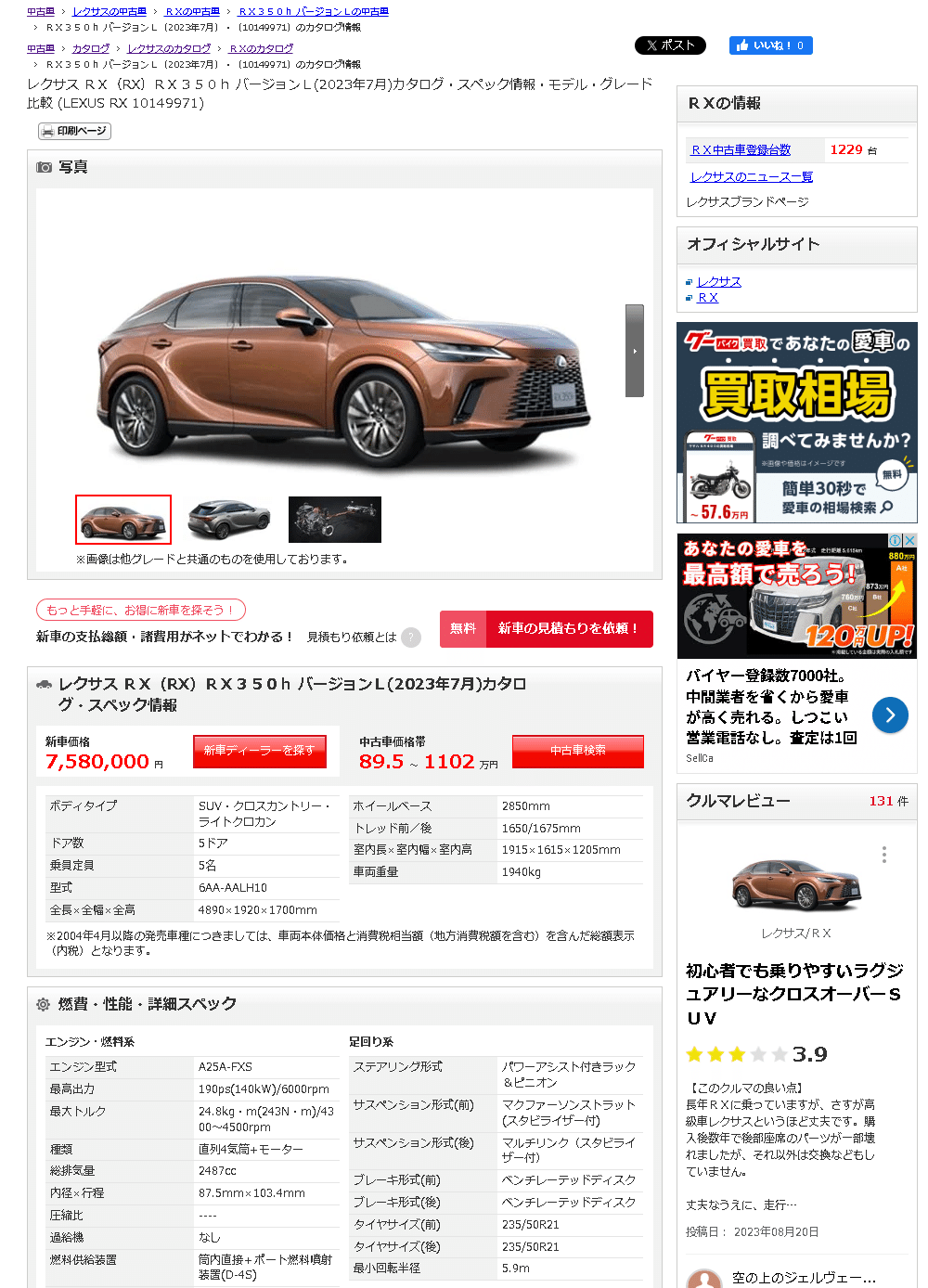
参考までに「レクサスRX350h バージョンL」のURLおよびページは下記の通りです。
3-2.他情報の追加
車両緒言にはないが比較したい情報を追加していきます。
下表の黄色塗りつぶしを手入力していきます。追加したいデータや不要なデータがある場合は、別途スクリプトの方を修正すれば調整可能です。
なお情報が無い(見積もり無し、未試乗)ものは0やN/Aを入力しました。
※今回は新車購入のため価格を手入力していますが、グーネットで購入するなら価格もスクレイピング可能です。

【質的データ:順序尺度】
私の中で重要な要因として乗り心地がありますが、これは質的データの順序尺度になります。順序尺度はデータにつけた数字の大小を示します。しかし、数字の間の差は一定ではないので比較時には注意(過大・過小評価が起こりえる)が必要です。
4.スクリプトの説明
完成版スクリプトは下記の通りです。詳細は各節で実施します。
[IN]
import pandas as pd
import numpy as np
import os, glob, datetime, re, time, itertools, json, logging, gc
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
#データ保存用Dir作成
if not os.path.exists('Output'):
os.makedirs('Output')
#緒言表の読み込み
df_desc = pd.read_excel('desc_data.xlsx', index_col=0)
names_car = list(df_desc.columns) #車両の名称(カラム)
urls = list(df_desc.loc['URL']) #車両のURL
#緒言表作成用の辞書作成
urls_dict = {}
for car, url in zip(names_car, urls):
urls_dict[car] = url
#Gooネットの車両情報を取得
def get_carInfo(url, carName=None):
tables = pd.read_html(url) #URLからテーブルを取得
df = tables[0] #テーブルの1つ目を取得※結合量
for idx, table in enumerate(tables[:-2]):
if table.shape[1] == 2: #2列のテーブルを取得
df = pd.concat([df, table], axis=0)
columns = ['項目', '{}'.format(carName)] #カラム名を変更
df.columns = columns
return df
#DataFrameの結合
for idx, (carName, url) in enumerate(urls_dict.items()):
df = get_carInfo(url, carName)
if idx == 0:
df_all = df
print(f'Car:{carName}, 情報量:{df.shape}')
else:
df_all = pd.merge(df_all, df, on='項目', how='outer')
print(f'Car:{carName}, 情報量:{df.shape}')
#重複データが含まれるため、削除
df_all = df_all.drop_duplicates()
df_all = df_all.reset_index(drop=True)
print(f'情報量:{df_all.shape}')
display(df_all.head(15))
#手入力データを追加
columns_adddata = ['本体価格', 'オプション', '諸費用', '割引', 'トータルコスト', '乗り心地', 'LeadTime[month]']
df_add = df_desc.loc[columns_adddata]
df_add['項目'] = df_add.index
df_add = df_add.reset_index(drop=True)
#データ結合
df_concat = pd.concat([df_all, df_add], axis=0)
df_concat.reset_index(drop=True, inplace=True)
df_concat
#比較図:縦線グラフ
def clean_text(text):
text = re.sub('名', '', text) #名を削除
text = re.sub('ドア', '', text) #ドアを削除
text = re.sub('kg', '', text) #kgを削除
text = re.sub('cc', '', text) #ccを削除
text = re.sub('mm', '', text) #mmを削除
text = re.sub('リットル', '', text) #リットルを削除
text = re.sub('km/リットル', '', text) #km/リットルを削除
text = re.sub('km/', '', text) #km/を削除
#寸法データが無い場合の処理:0を追加
text = re.sub('----', '0', text) #×を0に変換
return text
def split_and_adddata(df, columnName:str):
df = df.T #一旦転置
columns = columnName.split('×') #掛け算の文字で分割
for idx, column in enumerate(columns):
df[column] = df[columnName].str.split('×').str[idx].astype(float)
df = df.drop(columnName, axis=1)
df = df.T
return df
def extract_torque(df, columName:str='最大トルク'):
df = df.T #一旦転置
df[columName] = df[columName].str.extract('(\d+\.\d+)').astype(float)
df = df.T
return df
#グラフの描画
columns_plot = ['ドア数', '乗員定員', '全長×全幅×全高', 'ホイールベース','室内長×室内幅×室内高', '車両重量','最大トルク', '総排気量',
'燃料タンク容量', 'WLTCモード燃費']
df_plot = df_concat[df_concat['項目'].isin(columns_plot)]
df_plot.set_index('項目', inplace=True)
#関数を適用
df_plot = df_plot.applymap(clean_text)
#全長×全幅×全高の行をデータを分割し、新たな行を追加
df_plot = split_and_adddata(df_plot, '全長×全幅×全高')
df_plot = split_and_adddata(df_plot, '室内長×室内幅×室内高')
#トルクのデータを抽出※文字列は 24.8・m(243N・m)/4300〜4500rpm
df_plot = extract_torque(df_plot)
df_plot = df_plot.astype(float)
#グラフの描画
fig, axs = plt.subplots(1, 3, figsize=(14, 8))
ax1, ax2, ax3 = axs
#数値が100以下, 100~3,000, 3,000以上で分ける
df_plot1 = df_plot[df_plot <= 100].dropna()
df_plot2 = df_plot[(df_plot > 100) & (df_plot < 3000)].dropna()
df_plot3 = df_plot[df_plot > 3000].dropna()
#グラフの描画
df_plot1.plot(kind='barh', ax=ax1, title='自動車緒言表1')
df_plot2.plot(kind='barh', ax=ax2, title='自動車緒言表2', legend=False)
df_plot3.plot(kind='barh', ax=ax3, title='自動車緒言表3')
#棒グラフの表示順を逆転(凡例に合わせる)
ax1.invert_yaxis()
ax2.invert_yaxis()
ax3.invert_yaxis()
#数値ラベルを表示
for ax in axs:
for p in ax.patches:
ax.annotate(f'{p.get_width():.0f}', (p.get_width(), p.get_y() + p.get_height() / 2), ha='center', va='center', size=6)
plt.tight_layout()
ax1.legend(loc='upper right'), ax1.grid(axis='x')
ax2.grid(axis='x')
ax3.legend(loc='upper right'), ax3.grid(axis='x')
plt.savefig('Output/自動車緒言表.png')
plt.show()
#手動追加情報を可視化
index_cost = ['本体価格', 'オプション', '諸費用', 'トータルコスト'] #割引は見えにくいため除外
index_misc = ['乗り心地', 'LeadTime[month]']
df_cost = df_concat[df_concat['項目'].isin(index_cost)].set_index('項目') #コスト関連を抽出
df_misc = df_concat[df_concat['項目'].isin(index_misc)].set_index('項目') #その他を抽出
fig, axs = plt.subplots(1, 2, figsize=(14, 6))
ax1, ax2 = axs
df_cost.plot(kind='barh', ax=ax1, title='コスト関連')
df_misc.plot(kind='barh', ax=ax2, title='その他')
#棒グラフの表示順を逆転(凡例に合わせる)
ax1.invert_yaxis()
ax2.invert_yaxis()
#数値ラベルを表示
for ax in axs:
for p in ax.patches:
ax.annotate(f'{p.get_width():.0f}', (p.get_width()*1.05, p.get_y() + p.get_height() / 2), ha='center', va='center', size=7)
ax1.legend(), ax1.grid(axis='x')
ax2.legend(), ax2.grid(axis='x')
plt.tight_layout()
plt.savefig('Output/追加情報.png')
plt.show()
df_concat.to_excel('Output/自動車緒言表.xlsx')4-1.データ読み込み
ライブラリを読み込み、3章で作成したデータ表(desc_data.xlsx)を読み込みます。表のカラムと入力したURLから車両名:URLの辞書を作成しました。
[IN]
import pandas as pd
import numpy as np
import os, glob, datetime, re, time, itertools, json, logging, gc
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
#データ保存用Dir作成
if not os.path.exists('Output'):
os.makedirs('Output')
#緒言表の読み込み
df_desc = pd.read_excel('desc_data.xlsx', index_col=0)
names_car = list(df_desc.columns) #車両の名称(カラム)
urls = list(df_desc.loc['URL']) #車両のURL
#緒言表作成用の辞書作成
urls_dict = {}
for car, url in zip(names_car, urls):
urls_dict[car] = url
urls_dict[OUT]
{'LEXUS NX': 'https://www.goo-net.com/catalog/LEXUS/NX/10152388/',
'LEXUS RX': 'https://www.goo-net.com/catalog/LEXUS/RX/10149971/',
'TOYOTA ハリアー': 'https://www.goo-net.com/catalog/TOYOTA/HARRIER/10145452/',
'TOYOTA RAV4 HEV': 'https://www.goo-net.com/catalog/TOYOTA/RAV4/10145612/',
'HONDA\u3000ヴェゼル': 'https://www.goo-net.com/catalog/HONDA/VEZEL/10153169/',
'HONDA ZR-V': 'https://www.goo-net.com/catalog/HONDA/ZRV/10153567/',
'SUZUKI フロンクス': 'https://www.goo-net.com/catalog/SUZUKI/FRONX/10154966/',
'SUZUKI ジムニーシエラ': 'https://www.goo-net.com/catalog/SUZUKI/JIMNY_SIERRA/10152272/',
'スバル フォレスター': 'https://www.goo-net.com/catalog/SUBARU/FORESTER/10150215/',
'MAZDA CX-5': 'https://www.goo-net.com/catalog/MAZDA/CX5/10150337/',
'MAZDA CX-60': 'https://www.goo-net.com/catalog/MAZDA/CX60/10150117/',
'日産 XTRAIL': 'https://www.goo-net.com/catalog/NISSAN/XTRAIL/10153375/',
'ボルボ XC40': 'https://www.goo-net.com/catalog/VOLVO/XC40/10154927/'}4-2.車両緒言のDataFrame作成
先程作成した車両名とURLの辞書を用いて情報をスクレイピングし、共通の情報をまとめた表(DataFrame)を作成します。ポイントは下記の通りです。
スクレイピングはPandasの”pd.read_html(<URL>)”を使用
Tableタグがあれば簡単に要素を取得可能
列数が2(項目名と情報)以外のデータには車両緒言はなかったため、列数2以外は削除
各車で情報量(データ形状)が異なるため、結合時は"pd.merge()"で共通の項目名を結合
スクレイピングで得られたテーブルには重複するデータがあるため、最後に重複を削除
[IN]
#Gooネットの車両情報を取得
def get_carInfo(url, carName=None):
tables = pd.read_html(url) #URLからテーブルを取得
df = tables[0] #テーブルの1つ目を取得※結合量
for idx, table in enumerate(tables[:-2]):
if table.shape[1] == 2: #2列のテーブルを取得
df = pd.concat([df, table], axis=0)
columns = ['項目', '{}'.format(carName)] #カラム名を変更
df.columns = columns
return df
#DataFrameの結合
for idx, (carName, url) in enumerate(urls_dict.items()):
df = get_carInfo(url, carName)
if idx == 0:
df_all = df
print(f'Car:{carName}, 情報量:{df.shape}')
else:
df_all = pd.merge(df_all, df, on='項目', how='outer')
print(f'Car:{carName}, 情報量:{df.shape}')
#重複データが含まれるため、削除
df_all = df_all.drop_duplicates()
df_all = df_all.reset_index(drop=True)
print(f'情報量:{df_all.shape}')
display(df_all.head(15))[OUT]
Car:LEXUS NX, 情報量:(83, 2)
Car:LEXUS RX, 情報量:(83, 2)
Car:TOYOTA ハリアー, 情報量:(84, 2)
Car:TOYOTA RAV4 HEV, 情報量:(85, 2)
Car:HONDA ヴェゼル, 情報量:(86, 2)
Car:HONDA ZR-V, 情報量:(86, 2)
Car:SUZUKI フロンクス, 情報量:(89, 2)
Car:SUZUKI ジムニーシエラ, 情報量:(87, 2)
Car:スバル フォレスター, 情報量:(92, 2)
Car:MAZDA CX-5, 情報量:(89, 2)
Car:MAZDA CX-60, 情報量:(91, 2)
Car:日産 XTRAIL, 情報量:(83, 2)
Car:ボルボ XC40, 情報量:(90, 2)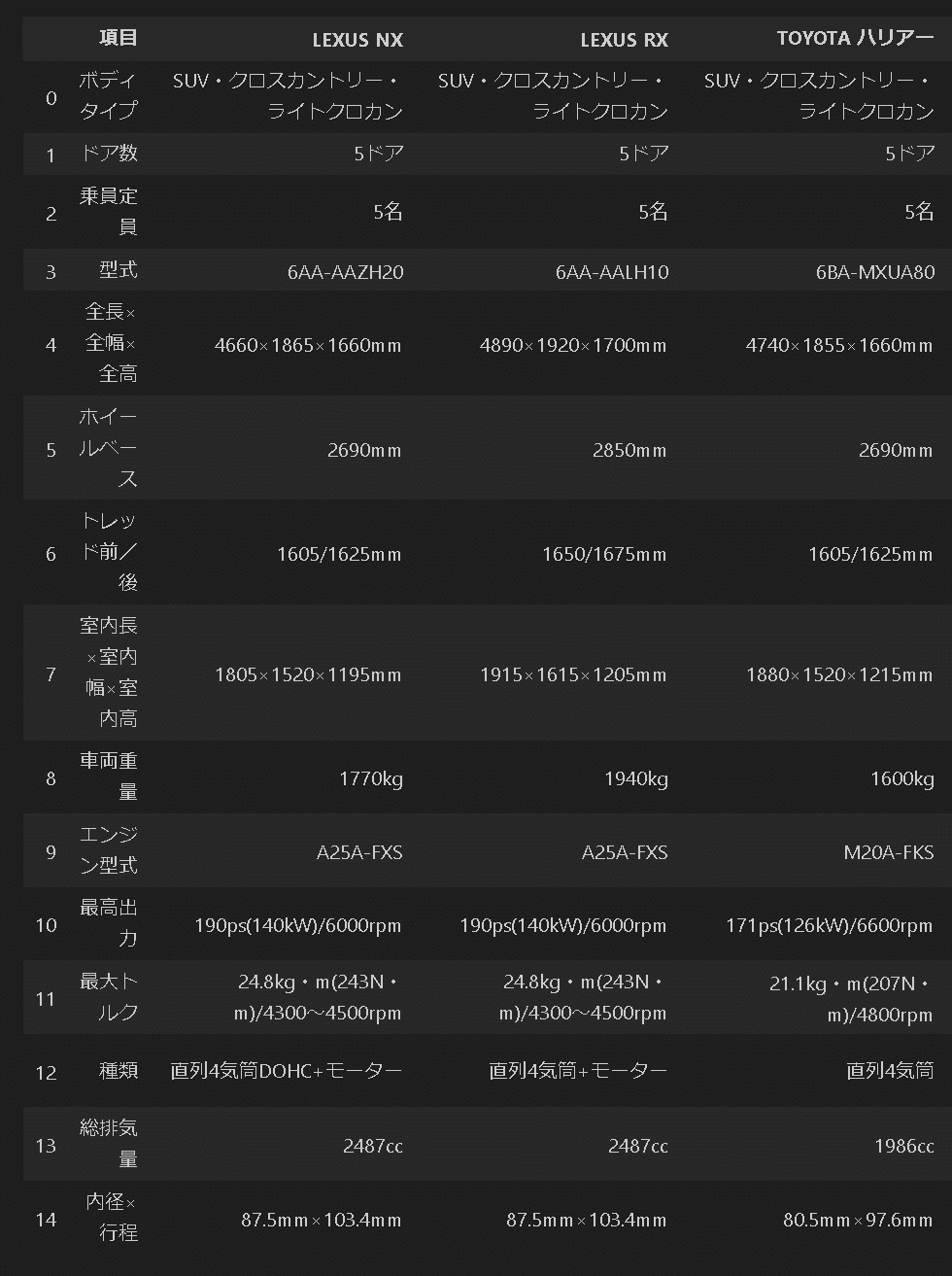
4-3.他情報の追加
得られた車両緒言表に3章で作成したデータ表(desc_data.xlsx)から、自分で入力した情報を追加しました。
追加するデータは”columns_adddata”で選択し、df.locでIndexから抽出しました。
[IN]
#手入力データを追加
columns_adddata = ['本体価格', 'オプション', '諸費用', '割引', 'トータルコスト', '乗り心地', 'LeadTime[month]']
df_add = df_desc.loc[columns_adddata]
df_add['項目'] = df_add.index #項目カラムを追加し、元データに結合させる
df_add = df_add.reset_index(drop=True)
#データ結合
df_concat = pd.concat([df_all, df_add], axis=0)
df_concat.reset_index(drop=True, inplace=True)
df_concat[OUT]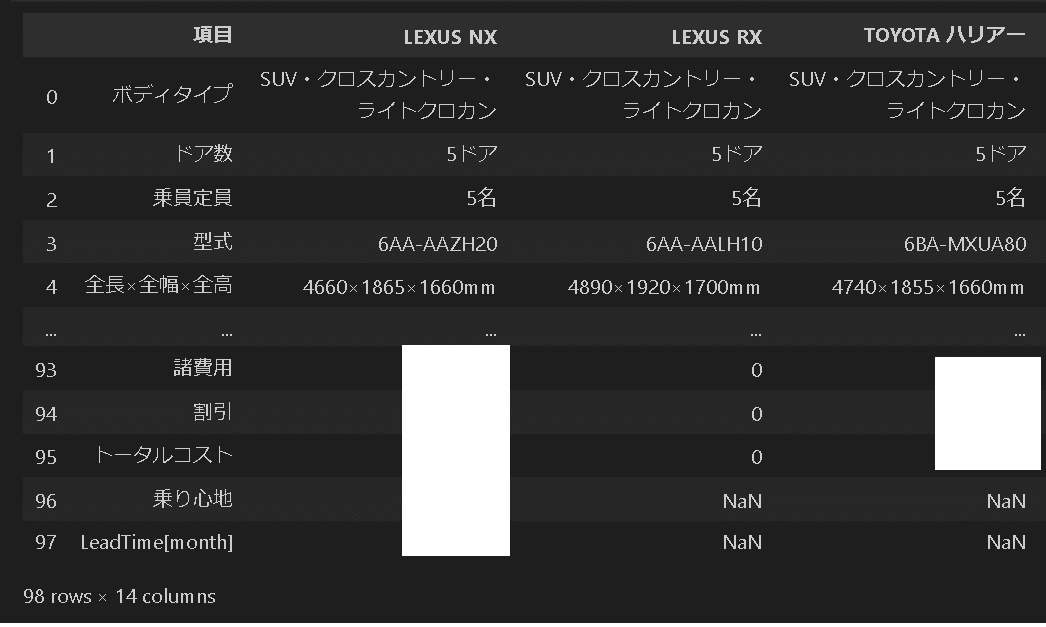
4-4.可視化1:車両緒言
本節からデータを可視化します。得られた車両緒言には文字列(String)になっているデータも多いため、下記の通り数値抽出する関数を作成しました。
単位記載により文字列化しているデータに関しては、全て単位を削除
寸法データが"幅×長さ×高さ"の表現になっているため、”×”で分割して抽出
トルク情報(例:24.8kg・m(243N・m)/4300~4500rpm)は正規表現で抽出
[IN]
#比較図:縦線グラフ
def clean_text(text):
text = re.sub('名', '', text) #名を削除
text = re.sub('ドア', '', text) #ドアを削除
text = re.sub('kg', '', text) #kgを削除
text = re.sub('cc', '', text) #ccを削除
text = re.sub('mm', '', text) #mmを削除
text = re.sub('リットル', '', text) #リットルを削除
text = re.sub('km/リットル', '', text) #km/リットルを削除
text = re.sub('km/', '', text) #km/を削除
#寸法データが無い場合の処理:0を追加
text = re.sub('----', '0', text) #×を0に変換
return text
def split_and_adddata(df, columnName:str):
df = df.T #一旦転置
columns = columnName.split('×') #掛け算の文字で分割
for idx, column in enumerate(columns):
df[column] = df[columnName].str.split('×').str[idx].astype(float)
df = df.drop(columnName, axis=1)
df = df.T
return df
def extract_torque(df, columName:str='最大トルク'):
df = df.T #一旦転置
df[columName] = df[columName].str.extract('(\d+\.\d+)').astype(float) #正規表現:数字.数字を抽出
df = df.T
return df 自分が抽出したいIndexを"columns_plot"に指定し、項目内にisin()でIndex確認後に、上記の数値抽出関数を適用しました。
この時点で全てのデータは数値(Float)に変換されています。
[IN]
#グラフの描画
columns_plot = ['ドア数', '乗員定員', '全長×全幅×全高', 'ホイールベース','室内長×室内幅×室内高', '車両重量','最大トルク', '総排気量',
'燃料タンク容量', 'WLTCモード燃費']
df_plot = df_concat[df_concat['項目'].isin(columns_plot)]
df_plot.set_index('項目', inplace=True)
#関数を適用
df_plot = df_plot.applymap(clean_text)
#全長×全幅×全高の行をデータを分割し、新たな行を追加
df_plot = split_and_adddata(df_plot, '全長×全幅×全高')
df_plot = split_and_adddata(df_plot, '室内長×室内幅×室内高')
#トルクのデータを抽出※文字列は 24.8・m(243N・m)/4300〜4500rpm
df_plot = extract_torque(df_plot)
df_plot = df_plot.astype(float)
df_plot.info()[OUT]
<class 'pandas.core.frame.DataFrame'>
Index: 14 entries, ドア数 to 室内高
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 LEXUS NX 14 non-null float64
1 LEXUS RX 14 non-null float64
2 TOYOTA ハリアー 14 non-null float64
3 TOYOTA RAV4 HEV 14 non-null float64
4 HONDA ヴェゼル 14 non-null float64
5 HONDA ZR-V 14 non-null float64
6 SUZUKI フロンクス 14 non-null float64
7 SUZUKI ジムニーシエラ 14 non-null float64
8 スバル フォレスター 14 non-null float64
9 MAZDA CX-5 14 non-null float64
10 MAZDA CX-60 14 non-null float64
11 日産 XTRAIL 14 non-null float64
12 ボルボ XC40 14 non-null float64
dtypes: float64(13)
memory usage: 2.1+ KB最後に可視化します。見やすくする工夫は下記の通りです。
データの最大値を近づけるため、Pandasのスライス機能を用いて数値の大小で分離
そのままプロットすると並びと凡例が逆になるため”ax.invert_yaxis()”でy軸の表示を逆転
ax.annotate()で数値ラベルを表示
真ん中の凡例は重なって邪魔になるためdf.plot(legend=False)で非表示
[IN]
#グラフの描画
fig, axs = plt.subplots(1, 3, figsize=(14, 8))
ax1, ax2, ax3 = axs
#数値が100以下, 100~3,000, 3,000以上で分ける
df_plot1 = df_plot[df_plot <= 100].dropna()
df_plot2 = df_plot[(df_plot > 100) & (df_plot < 3000)].dropna()
df_plot3 = df_plot[df_plot > 3000].dropna()
#グラフの描画
df_plot1.plot(kind='barh', ax=ax1, title='自動車緒言表1')
df_plot2.plot(kind='barh', ax=ax2, title='自動車緒言表2', legend=False)
df_plot3.plot(kind='barh', ax=ax3, title='自動車緒言表3')
#棒グラフの表示順を逆転(凡例に合わせる)
ax1.invert_yaxis()
ax2.invert_yaxis()
ax3.invert_yaxis()
#数値ラベルを表示
for ax in axs:
for p in ax.patches:
ax.annotate(f'{p.get_width():.0f}', (p.get_width(), p.get_y() + p.get_height() / 2), ha='center', va='center', size=6)
plt.tight_layout()
ax1.legend(loc='upper right'), ax1.grid(axis='x')
ax2.grid(axis='x')
ax3.legend(loc='upper right'), ax3.grid(axis='x')
plt.savefig('Output/自動車緒言表.png')
plt.show()[OUT]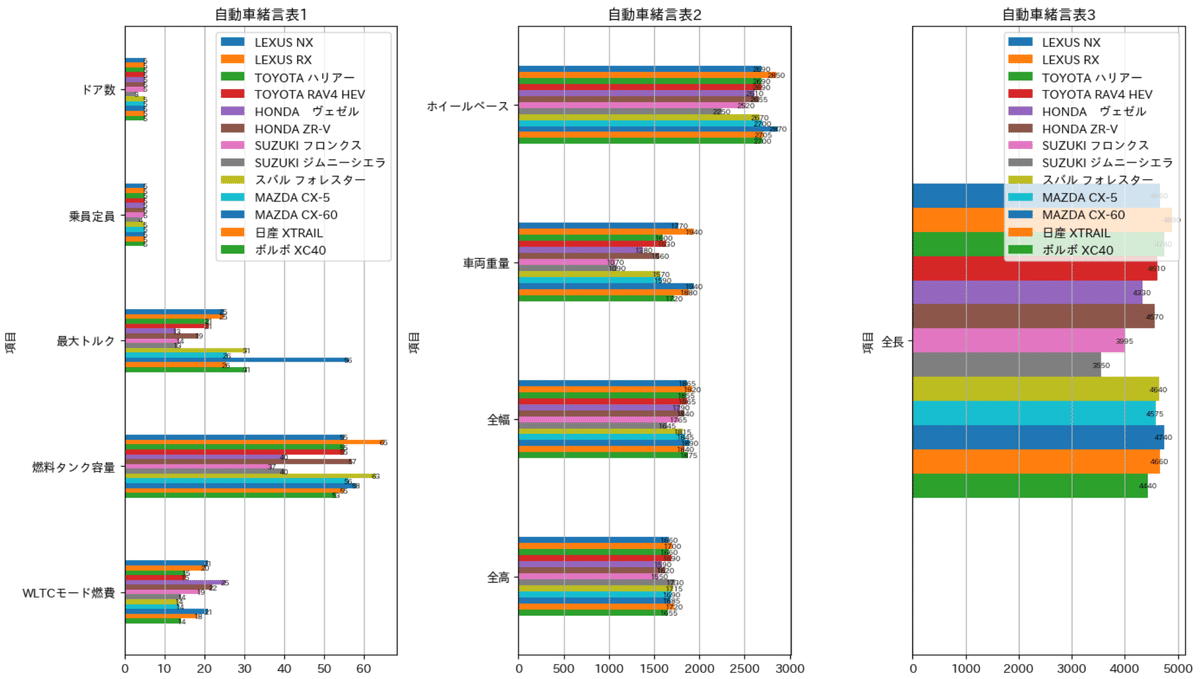
4-5.可視化2:他データ
3章で作成したデータ表(desc_data.xlsx)も表示させます。
設計思想は前節と同じであり、Indexの抽出項目だけリストに選択しました。
結果は一部隠して載せました。
[IN]
#手動追加情報を可視化
index_cost = ['本体価格', 'オプション', '諸費用', 'トータルコスト'] #割引は見えにくいため除外
index_misc = ['乗り心地', 'LeadTime[month]']
df_cost = df_concat[df_concat['項目'].isin(index_cost)].set_index('項目') #コスト関連を抽出
df_misc = df_concat[df_concat['項目'].isin(index_misc)].set_index('項目') #その他を抽出
fig, axs = plt.subplots(1, 2, figsize=(14, 6))
ax1, ax2 = axs
df_cost.plot(kind='barh', ax=ax1, title='コスト関連')
df_misc.plot(kind='barh', ax=ax2, title='その他')
#棒グラフの表示順を逆転(凡例に合わせる)
ax1.invert_yaxis()
ax2.invert_yaxis()
#数値ラベルを表示
for ax in axs:
for p in ax.patches:
ax.annotate(f'{p.get_width():.0f}', (p.get_width()*1.05, p.get_y() + p.get_height() / 2), ha='center', va='center', size=7)
ax1.legend(), ax1.grid(axis='x')
ax2.legend(), ax2.grid(axis='x')
plt.tight_layout()
plt.savefig('Output/追加情報.png')
plt.show()
df_concat.to_excel('Output/自動車緒言表.xlsx')[OUT]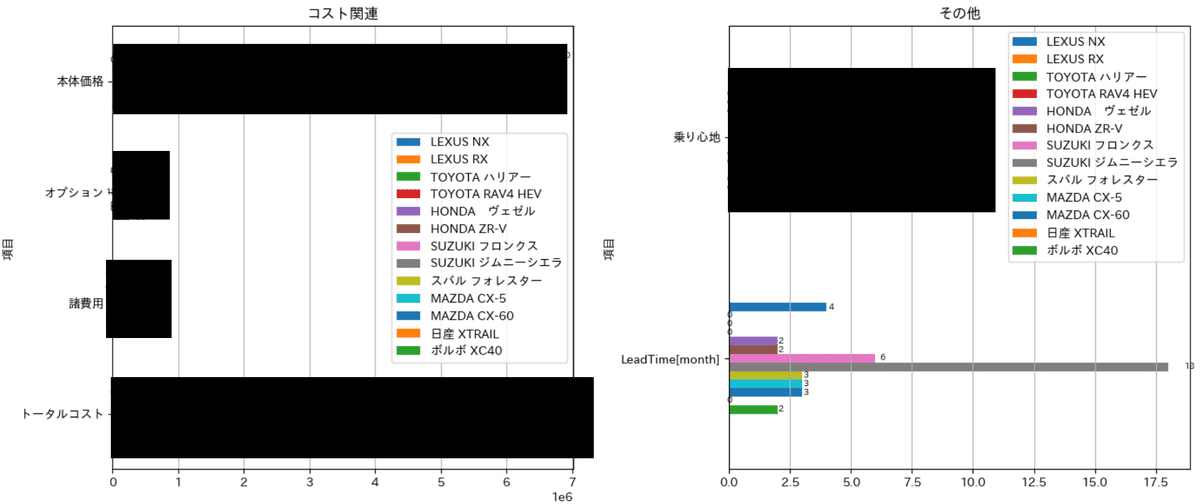
参考資料
あとがき
初めての車選びであり、試乗してみないと定量的な部分(トルク、重量比など)は分からなかったし、定性的な部分(安全装置、シートの硬さなど)も比較しにくかった。
もっと楽でいい感じに作れたらうれしいけど、今回は時間が無いので妥協!