
【データの集め方講座】Jリーグの日程を取得する-Python×Selenium-

はじめに
ごあいさつ
ご高覧いただきありがとうございます.
ソフトウェアエンジニアのKitaharaです.
Jリーグ見ていますか?
Jリーグとは日本のプロサッカーリーグなのですが, 現在第2節です
今年はどこが優勝するのか楽しみですね!
というわけで, 本日はJリーグ の試合データの収集方法を解説します!
そもそもJリーグって
Jリーグを知らない方向けにJリーグの補足情報について書いていきます.
日本プロサッカーリーグ(にほんプロサッカーリーグ、英: Japan Professional Football League)は、日本のプロサッカーリーグ。略称はJリーグ[注釈 1](ジェイリーグ、英: J.LEAGUE)。
特徴としてはクラブ名称に企業名が入っていないことで原則として名前を地域名称と愛称としています. 今季のJ1リーグ(一番上位のリーグ)の名称を下記に記しますが, 確かにクラブ名称が載っていないことが分かります.
['北海道コンサドーレ札幌',
'鹿島アントラーズ',
'浦和レッズ',
'柏レイソル',
'FC東京',
'川崎フロンターレ',
'横浜F・マリノス',
'湘南ベルマーレ',
'清水エスパルス',
'ジュビロ磐田',
'名古屋グランパス',
'京都サンガF.C.',
'ガンバ大阪',
'セレッソ大阪',
'ヴィッセル神戸',
'サンフレッチェ広島',
'アビスパ福岡',
'サガン鳥栖']Jリーグの試合データをどのように取得するか
Jリーグには公式のWebサイトがありますのでクローリングして集めます.
具体的には
リンク先の [試合日程] と書かれているaタグのhref要素をリスト化
それぞれのリンク先から試合情報を集める
csvファイルにして保存
という手順でデータを収集します.
Seleniumが初めてという方へ
Seleniumはローカルで使うと大変なのですが, Google Colabを使うと簡単に環境構築することができます.
Google Colabを使った環境構築方法とSeleniumの基本操作方法の記事を過去に執筆しておりますので必要に応じてご参照ください.
使うものの説明
Python(3.7.12)
プログラミング言語のひとつです.
型宣言等が無く, 初心者にも扱いやすい言語だと言われています
近年Deep Learningのライブラリが豊富であることから注目を集めている人気の言語です
Selenium
Webブラウザの操作を自動で行うためのフレームワークです
もともとはWebアプリケーションのテスト等で使うことを目的に開発されましたが, 現在ではWebスクレイピング(Webサイトからデータを取得すること)を目的に利用されることも多いです
Google Coraboratory
Googleが提供するPythonの実行環境
主要なライブラリがインストールされている状態で使うことができる
Chromeでアクセスするだけで利用することができる
環境構築が不要
無料で使うことができる
SeleniumでWebScraping
データの取得
Seleniumでデータを取得してみましょう.
コードの下に解説を書きましたので適宜ご参照ください.
INPUT
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import datetime
options = webdriver.ChromeOptions()
options.add_argument('--headless') # headlessモードを使用する
options.add_argument('--no-sandbox') # sandboxモードを解除する(クラッシュの回避)
options.add_argument('--disable-dev-shm-usage') # /dev/shmパーティションの使用を禁止にする(クラッシュの回避)
options.add_argument('--disable-extensions') # 拡張機能を無効にする
driver = webdriver.Chrome('chromedriver', options=options) # Driverを起動
driver.get('https://www.jleague.jp/special/schedule/2022/spring/') # データを取得
time.sleep(1)
# CSS セレクターを用いてクラスがrecipe-titlelinkのaタグを取得
# seleniumのversionが3以下だとfind_elements_by_css_selector(selector)なので注意
selector = 'table.infoTable tbody tr td a'
web_elms = driver.find_elements(by=By.CSS_SELECTOR, value=selector)
target_links = [link.get_attribute('href') for link in web_elms]
all_game_data = []
for iter in range(len(web_elms)):
driver.get(target_links[iter])
time.sleep(1)
date_selector = 'h4.leftRedTit'
date_elms = driver.find_elements(by=By.CSS_SELECTOR, value=date_selector)
left_selector = 'table.gameTable tbody tr td.leftside a'
left_team_elms = driver.find_elements(by=By.CSS_SELECTOR, value=left_selector)
right_selector = 'table.gameTable tbody tr td.rightside a'
right_team_elms = driver.find_elements(by=By.CSS_SELECTOR, value=right_selector)
game_data = [[ date_elms[i].text[:-3], left_team_elms[i].text, right_team_elms[i].text ] for i in range(len(date_elms))]
all_game_data.append(game_data)
time.sleep(1)
driver.close()OUTPUT
# NOTHINGコードの解説
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import datetime
options = webdriver.ChromeOptions()
options.add_argument('--headless') # headlessモードを使用する
options.add_argument('--no-sandbox') # sandboxモードを解除する(クラッシュの回避)
options.add_argument('--disable-dev-shm-usage') # /dev/shmパーティションの使用を禁止にする(クラッシュの回避)
options.add_argument('--disable-extensions') # 拡張機能を無効にする
driver = webdriver.Chrome('chromedriver', options=options) # Driverを起動この部分では必要なモジュールとseleniumで使う設定をしています.
opsionsというwebdriver.ChromeOptionsクラスのインスタンスに対してadd_argumentメソッドで設定を追加していきます.
その後にdriverというwebdriver.Chromeクラスのインスタンスを作成しています. ここまででwebスクレイピングする準備が整いました.
driver = webdriver.Chrome('chromedriver', options=options) # Driverを起動
driver.get('https://www.jleague.jp/special/schedule/2022/spring/') # データを取得
time.sleep(1)
# CSS セレクターを用いてクラスがrecipe-titlelinkのaタグを取得
# seleniumのversionが3以下だとfind_elements_by_css_selector(selector)なので注意
selector = 'table.infoTable tbody tr td a'
web_elms = driver.find_elements(by=By.CSS_SELECTOR, value=selector)
target_links = [link.get_attribute('href') for link in web_elms]driver.get('URL')で下記のページにGETリクエストを送ります.
その後, [試合日程] と書かれている要素をcss selectorで指定して, 取得します.
具体的にはdriver.find_elements(by=CSS?SELECTOR, value='selector of target element')を使用します.

==================================================
CSS selectorが分からないという方 => CSS selectorの解説付き記事
==================================================
その結果がweb_elemsという変数に格納されます.
ただ, 各要素のhref要素が必要なのでforで回し, get_attribute('href')でリンクのリストを作ります.
all_game_data = []
for iter in range(len(web_elms)):
driver.get(target_links[iter])
time.sleep(1)
date_selector = 'h4.leftRedTit'
date_elms = driver.find_elements(by=By.CSS_SELECTOR, value=date_selector)
left_selector = 'table.gameTable tbody tr td.leftside a'
left_team_elms = driver.find_elements(by=By.CSS_SELECTOR, value=left_selector)
right_selector = 'table.gameTable tbody tr td.rightside a'
right_team_elms = driver.find_elements(by=By.CSS_SELECTOR, value=right_selector)
game_data = [[ date_elms[i].text[:-3], left_team_elms[i].text, right_team_elms[i].text ] for i in range(len(date_elms))]
all_game_data.append(game_data)
time.sleep(1)
driver.close()試合のデータを各チームごとに取得していきます.
試合データは下記のような「時間」と「左側のチーム」と「右側のチーム」で収集します. (2022年の予定が知りたいため, 第一節, 第二節の結果は無視)

game_data = [[ date_elms[i].text[:-3], left_team_elms[i].text, right_team_elms[i].text ] for i in range(len(date_elms))]難しく見えるリスト内包表記ですが, 下記のコードと同じことをしています.
game_data = []
for i in range(len(date_elms)):
game_data.append([
date_elms[i].text[:-3],
left_team_elms[i].text,
right_team_elms[i].text
])なぜ, このような表記方法をするかというと処理が早くなるからです. (出典: スキルシェアリング.INFO, Pythonリスト内包表記の速度)
また, (読める人にとっては)可読性が向上します.
似たような処理は似たように書くというコーディングのお作法があるのですが, リスト内包表記で一行で書かれた処理は実際for文で書かれた処理より見やすいです.
コードを実行したらデータを取得できているか確認しましょう.
INPUT
all_game_data[2]OUTPUT
[['2022年2月19日', '京都', '浦和'],
['2022年2月23日', '浦和', '神戸'],
['2022年2月26日', '浦和', 'G大阪'],
['2022年3月2日', '川崎F', '浦和'],
['2022年3月6日', '浦和', '湘南'],
['2022年3月13日', '鳥栖', '浦和'],
['2022年3月19日', '浦和', '磐田'],
['2022年4月2日', '札幌', '浦和'],
['2022年4月6日', '浦和', '清水'],
['2022年4月10日', 'FC東京', '浦和'],
['2022年5月8日', '柏', '浦和'],
['2022年5月13日', '浦和', '広島'],
['2022年5月18日', '浦和', '横浜FM'],
['2022年5月21日', '浦和', '鹿島'],
['2022年5月25日', 'C大阪', '浦和'],
['2022年5月28日', '福岡', '浦和'],
['2022年6月18日', '浦和', '名古屋'],
['2022年6月26日', '神戸', '浦和'],
['2022年7月2日', 'G大阪', '浦和'],
['2022年7月6日', '浦和', '京都'],
['2022年7月10日', '浦和', 'FC東京'],
['2022年7月17日', '清水', '浦和'],
['2022年7月30日', '浦和', '川崎F'],
['2022年8月6日', '名古屋', '浦和'],
['2022年8月13日', '磐田', '浦和'],
['2022年9月3日', '鹿島', '浦和'],
['2022年9月10日', '浦和', '柏'],
['2022年9月14日', '浦和', 'C大阪'],
['2022年9月17日', '湘南', '浦和'],
['2022年10月1日', '広島', '浦和'],
['2022年10月8日', '浦和', '鳥栖'],
['2022年10月12日', '浦和', '札幌'],
['2022年10月29日', '横浜FM', '浦和'],
['2022年11月5日', '浦和', '福岡']]データの保存
問題なく取得できていましたらファイル名に付けるためのチーム名のデータを取得してしまいましょう. 方法は先程と同じです.
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import datetime
options = webdriver.ChromeOptions()
options.add_argument('--headless') # headlessモードを使用する
options.add_argument('--no-sandbox') # sandboxモードを解除する(クラッシュの回避)
options.add_argument('--disable-dev-shm-usage') # /dev/shmパーティションの使用を禁止にする(クラッシュの回避)
options.add_argument('--disable-extensions') # 拡張機能を無効にする
driver = webdriver.Chrome('chromedriver', options=options) # Driverを起動
driver.get('https://www.jleague.jp/special/schedule/2022/spring/') # データを取得
time.sleep(1)
# CSS セレクターを用いてクラスがrecipe-titlelinkのaタグを取得
# seleniumのversionが3以下だとfind_elements_by_css_selector(selector)なので注意
selector = 'table.infoTable tbody tr th'
web_elms = driver.find_elements(by=By.CSS_SELECTOR, value=selector)
team_list = [team.text for team in web_elms]チームリストには違うデータも入っていたのでその部分を削除します.
team_list
team_list = team_list[:18]team_listは以下の様になっていれば大丈夫です.
['北海道コンサドーレ札幌',
'鹿島アントラーズ',
'浦和レッズ',
'柏レイソル',
'FC東京',
'川崎フロンターレ',
'横浜F・マリノス',
'湘南ベルマーレ',
'清水エスパルス',
'ジュビロ磐田',
'名古屋グランパス',
'京都サンガF.C.',
'ガンバ大阪',
'セレッソ大阪',
'ヴィッセル神戸',
'サンフレッチェ広島',
'アビスパ福岡',
'サガン鳥栖']さていよいよ大詰めです.
データを格納するファイルを作成しましょう.
INPUT
!mkdir JLeague # Linuxのディレクトリを作成するコマンドOUTPUT
# NOTHINGファイルを作ったらデータをcsv形式にして格納します.
今回はGoogle Colabで最初からPandasがあるのでPandasを使用します.
INPUT
import pandas as pd
for i in range(18):
df = pd.DataFrame(all_game_data[i], columns=['date', 'team1','team2'])
df.to_csv('./JLeague/'+team_list[i]+'.csv', index=False)OUTPUT
# NOTHING最終的にこのようになれば問題ありません
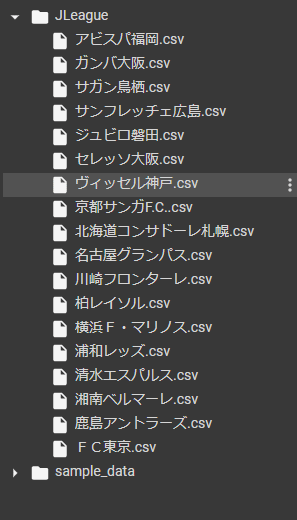
全てダウンロードすると時間がかかるのでディレクトリごとDriveに移動すると楽に保存できます. 下記の一番右のボタンを押してgoogle Driveをマウントします

あとはJLeagueディレクトリをドラッグしてdriveのMyDrive内にいれれば完成です! お疲れさまでした!

おわりに
今回はPythonとSeleniumを使ってJリーグの試合日程を収集する方法を解説しました! 参考になったという方はぜひハートボタンを押していってください!
モチベーションが上がります!
記事内で不明な点等ございましたら気軽にご連絡ください.
Twitter: @kitahara_dev
email: kitahara.main1@gmail.com