
トランスフォーマーの自己アテンションの理解①トークン数値化の歴史

本シリーズの記事リスト
第一弾 トークン数値化の歴史
第二弾 再帰による文脈伝搬
第三弾 レコメンダーと内積
第四弾 位置エンコーディング
第五弾 エンコーダ・デコーダ
第六弾 クエリとキーとバリュー
第七弾 エンコーダ・ブロックの詳細
第八弾 デコーダ・ブロックの詳細
2017年に、Googleの研究者であるAshish Vaswaniらのチームが発表したトランスフォーマー (Transformer)のアーキテクチャは、近年におけるディープラーニングの進展に大きく貢献しました。GPT3やBERTなどの巨大な言語モデル(LLMs, Large Language Models)の土台にもなっています。
特に自己アテンションと呼ばれる仕組みが重要です。どのようなシーケンス(順番に並んでいるもの)でも応用が効くため、最近では言語モデルだけでなく、画像処理や画像生成の分野にも広く応用されています。とは言っても、もともとトランスフォーマーは機械翻訳のモデルとして登場したので、その文脈で話を進めます。その方が歴史を辿りやすいのが理由です。
この記事ではあまり数式を使わずに、トランスフォーマー以前の言語モデルの歴史を遡ります。そこに見られるのは言語の数値化が進化する過程です。なぜなら、単語や文脈をうまく数値化すれば機械学習で利用することができるからです。
歴史を振り返りながら、文章の数値化、トークンの分散表現、文脈の数値化を順番に辿っていきます。
では、始めましょう。
文章の数値化
まずは文章を数値化する努力を見ていきます。機械学習は突き詰めると数学なので、数値化しないことには何も始まりません。
BoW
Wikipediaによると、1950年代にはBag of Words(BoW)と呼ばれる手法による文章の分類などが研究されていました。
BoWとは単純にいうと、文章の特徴をその文章の中にある単語の出現数で定義するものです。正確にいうと、単語というより、形態素(最小の意味単位)を数えます。
例えば、以下の文章があったとします。
「カエルが飛ぶ、犬が飛ぶ」句点は無視するとして、この文章を以下のように分解します。
['カエル', 'が', '飛ぶ', '犬', 'が', '飛ぶ']分解された要素が現れる回数を数えて、この文章を数値化すると、
{'カエル':1, 'が':2, '飛ぶ':2, '犬':1 }といった感じになります。これがBag of Words(言葉の袋)に相当します。
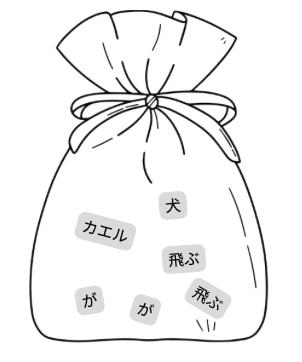
BoWは言葉の出現頻度を利用して文章の特徴を掴むことにより分類ができるという仕組みです。例えば、スポーツ関係の言語要素が多い記事はスポーツ・ニュースだろうといったイメージです。
しかし、BoWには弱点があります。それは、文章における要素の出現順序を全く考慮していない点です。つまり、言葉の前後がわからないので、文脈や要素感の関係を扱うことがほぼできません。
この記事が気に入ったらチップで応援してみませんか?