
情報理論:エントロピー

それは混沌、不確実性、それとも驚きか?
「エントロピー」と聞くと分かりにくそうだ。しかも、いろんな形容詞が伴ってくる:無秩序、不明瞭、想定外、予測不能。でも、そんなに難しくはない。一つずつクリアに説明していく。
ちなみに、ここでいうエントロピーは情報理論からのもので、熱力学のエントロピーの影響を受けた概念ではあるが、少なくとも最初は無関係で別物だと考えた方が良い。
情報エントロピーを発明したのは誰?
1948年に、クロード・シャノン(Claude Shannon)が情報エントロピーの概念を論文「A Mathematical Theory of Communication」において導入した。

彼は情報を失うことなくメッセージ(データ)を効率よく伝達する方法を模索していた。

メッセージをたくさん送っているときに、メッセージの平均の長さが短いほど効率が良い。よって送り側がメッセージの内容を圧縮して送る方法を構想した。しかし同時に、受け取った側で情報が完全に復元できる必要があるとした。

エントロピーはメッセージを伝達する際に可逆圧縮(ロスレス圧縮)できる理論上可能な最も小さい平均長と定義された。そして、その計算方法が論文で公開された。これは限られた通信帯を効率よく生かすために重要なことだった。
といっても、ピンとこないかもしれない。以下に、具体例を通して効率が良いとはどういうことなのかを追って説明する。
効率的可逆圧縮
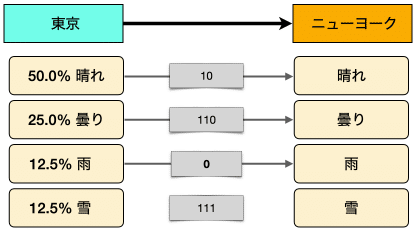
仮に、東京からニューヨークにメッセージを送りたいとする。内容は東京の今日の天気だ。

「今日の東京の天気は晴れです。」とテキストを送る。
これは効率的か?
そのような質問は状況設定による。
ここでは、東京にいる送り主とニューヨークにいる受取手は両者とも東京の今日の天気の情報を通信しているのを了解しているものとしよう。よって、「今日の東京の天気は」と伝える必要はない。
さらに、「晴です」か「晴れではない」と伝えるだけとする。

だいぶ短くなった。「晴れです」じゃなくて「晴」で十分だろうって?
「晴れではない」じゃなくて「NOT晴れ」の方がより短いとか。いろいろとアイデアは浮かぶ。
いや、もっと短くできる。イエスかノーの二社択一、つまりバイナリなのだから1ビットで十分だ。
1ビットで0か1を送れば足りる。

これ以上は短くできない。
でも可逆だろうか?もとの意味を復元できるのか?
送り主と受取手で合意したプロトコルに従っているのでこれで可逆になっている。ニューヨークでは東京が「晴れ」か「NOT晴れ」であるかがわかるし、それで全ての情報になっている。
しかし、天気には「曇り」とか「雨」とかある。1ビットだけでは不十分ではないか?

2ビットではどうか?
これで全部表現できる。2ビットあれば足りる。

でも、なんかおかしい。
「曇り」も「雨」も「NOT晴れ」の部類だ。「NOT晴れ」は必要ない。

これで無駄が省けたようだ。
いや、待てよ。「晴れ」に対して0を2つ使う必要はなさそうだ。
0から始まったら、すぐに「晴れ」と解釈できる。1から始まるのは「曇り」の10か「雨」の11。
00を0にすれば1ビット節約できる。

また、うまい具合に復元もできる。最初に送られるビットが0なら「晴れ」で1なら「NOT晴れ」。1のばあいは、次のビットが「曇り」か「雨」の情報になっている。
でも、東京では雪が降るぞ。「雪」はどうする?
このままだと、「雪」が伝えられない。三つ目のビットが必要だ。

気づいたかもしれないが「雨」を11から110にした。「雪」が111なので「雨」が11のままだと曖昧になる。
最初のビットが1、次のビットが1、その後何も来なかったら、伝達が遅れているのか、「雨」の意味なのかわからない。
「雨」を110にすればこの問題が解決できる。
まとめると、最初のビットが「晴れ」か「NOT晴れ」の情報、次のビットが「曇り」か「その他」、3番目のビットが「雨」か「雪」かを教えてくれる。
では、連続したメッセージを解読してみよう。
010110111010110111は「はれ、曇り、雨、雪」だ。
110010111110010111は「雨、晴れ、曇り、雪」だ。
曖昧さが全くない。情報は可逆圧縮されており効率的でもある。
もちろん、東京の天気はこれだけではない。でも、面倒臭いのでこのくらいにしておこう。
効率的可逆圧縮について言いたいことは伝わったと信じる。
これでおしまい?
もちろんそんなわけはない。まだ、エントロピーにカスリもしていない。
エントロピーは理論上可能な最小の平均メッセージの長さだと定義されている。
でも、上記の圧縮方法で本当にそうなっているのか。
そもそも、そんな平均の長さをどう計算するのか?
平均圧縮データ長
上述の圧縮方法で東京からニューヨークへ定期的にメッセージを送っており、データが保存されているとする。
これによってメッセージのタイプごとに割合を計算でき、確率分布がわかる。

この情報をもとに東京からニューヨークへ送られる平均のビット数を計算する。
(0.6 x 1 bit) + (0.38 x 2 bits) + (0.01 x 3 bits) + (0.01 x 3 bits) = 1.42 bits
つまり、上述の圧縮方法だと、平均で1.42ビット使用することになる。要するに、平均を計算するにはメッセージのタイプごとの割合である確率分布がわかれば良い。
例として、東京でもっと「雨」が降った場合を考える。当然、平均の圧縮データ長であるビット数は変わってくる。

(0.1 x 1 bit) + (0.1 x 2 bits) + (0.4 x 3 bits) + (0.4 x 3 bits) = 2.7 bits
この例では、平均で2.7ビット使用することがわかった。「雨」や「雪」のメッセージは「晴れ」や「曇り」と比べてビット数が多いので平均的にメッセージがより長くなっている。
だったら、「雨」や「雪」に対してより少ないビット数を配分したらどうか。

こうするとメッセージの平均長が1.8ビットになる。だいぶ短くなった。
確率分布に合わせて圧縮の仕方を変えることで平均長をより短くできる。
ただし、圧縮の仕方を変えたことで、最初のビットは「晴れ」か「NOT晴れ」の情報といった意味が失われる。
実は、エントロピーを考えるときは、このような意味や復元方法の容易さなどは気にしない。あくまでも、できる限り平均が最小になることだけを考える。
よって実際の圧縮では理論的な最小値を達成するような圧縮方法は使われないかもしれない。復元する容易さや速さを優先して圧縮の効率を少し悪くすることも考えられる。
しかし、エントロピーが理論的な最小値を与えることには変わりはない。また、様々な理論の構築でエントロピーが役に立つので理解することはとても重要だ。
さて、今度はその最小値をどのように達成するのかを見ていく。
最小平均圧縮データ長
次のようなメッセージのタイプの確率分布が分かっているとして、最小平均圧縮データ長をどうやって計算するのか?

例えば、「雨」の圧縮に何ビット使うのが最も最適なのか?
仮に、1ビットを「雨」の圧縮に割り当ててみる。つまり、0なら「雨」とする。この場合、他のタイプには2ビット以上が必要となる。曖昧さを無くすためだ。
もちろん、これは最適ではない。なぜなら「晴れ」や「曇り」の方が「雨」より多く生じるからだ。1ビットを割り当てるなら、より頻度の高いメッセージのタイプにするべきだ。
では、「晴れ」に1ビット、「雨」に2ビットを割り当ててみよう。

さっきよりはマシだが、同じ問題がある。「曇り」の方が「雨」よりも頻度が高いのに3ビットも使っているからだ。
「雨」の方を3ビットにして、「曇り」を2ビットにしてみよう。

実は、これが最小の平均圧縮サイズになる。これ以上は小さくできない。
「雨」に4ビット使ったりすると、ビット数の浪費になり無駄だ。だから3ビットで良い。これ以上変える必要はない。
でも、このようなやり方だと試行錯誤が多くて手間がかかる。
確率分布が与えられたら、理論的最小圧縮データ長をサクッと計算したい。
つまり、確率分布からエントロピーを直接計算したい。
エントロピーの計算方法
以下のように8つのメッセージのタイプがあり、それぞれ同確率(⅛ = 12.5%)で生じるとする。
曖昧さがない圧縮方法で最小なものはどうなるか。

8個の異なる値を指定するには何ビット必要か。
1ビットは0か1、つまり二つの値を指定できる。
0, 12ビットにするとそれが2倍になる。つまり、2×2 = 4個の値を指定できる。
00, 01, 10, 113ビットあれば、2x2x2 = 8個の値を指定できる。
000, 001, 010, 011, 100, 101, 110, 111それ以上のビットを使うのは無駄なので、3ビットを使って以下のように割り当てる。
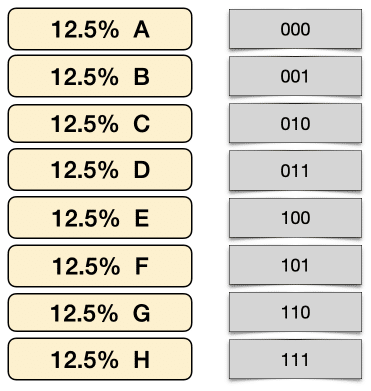
これ以上ビットを減らせない。曖昧なケースが出てくるからだ。上図を見てビットを減らせるかどうか挑戦して欲しい。
一般に、N個の値を表現するには以下に計算されるビット数が必要となる。
$$
\log_2 N
$$
そして、これ以上は無駄になるので必要ない。
例えば、上述したように8個の値なら、3ビットが必要と計算できる。
$$
\log_2 8 = \log_2 2^3 = 3 \ \text{bits}
$$
確率を使って式を変形すると、
$$
\log_2 8 = −\log_2 \frac{1}{8}
$$
となる。言い換えると、⅛の確率で生じるメッセージは3ビット必要である。
より一般に、$${\frac{1}{N}}$$の確率で生じるメッセージに必要なビット数は以下のように計算できる。
$$
\log_2 N = −\log_2 \frac{1}{N} = −\log_2 P
$$
ここでP = 1/N と置いた。
つまり、必要なビット数は、確率の対数をとってマイナスにしたものになっている。
確率が大きい(頻度が高い)ものほどビット数が小さくなることを理解してほしい。
また、この計算方法なら試行錯誤する必要がない。
この必要最小限のビット数である、$${−\log_2 P}$$を情報量と呼ぶ。
こうして計算した情報量と確率を使って平均値を計算したのがエントロピーになる。
$$
\text{Entropy} = − \sum_i P_i \log_2 P_i
$$
$${P_i}$$としたのは$${i}$$番目のメッセージのタイプが生じる確率を意味する。
エントロピーを説明するテキストの多くは上式をいきなり導入して「ドヤ」的な解説で終わることが多い。
でも、ここまで読まれた方は、その意味がわかるはずだ。この単純さと美しさをゆっくりと味わってほしい。
もちろん、種も仕掛けもない。魔法でもない。
単に、平均が最小になるように確率(頻度)の高いメッセージのタイプをより少ないビットで圧縮してその平均を計算しただけのことだ。だから理論上最小の平均サイズになる。
「お疲れ様でした」と言いたいところだが、最後にもう一回だけ例を見て理解を固めよう。

上記の確率分布に対して、必要最低ビット数は以下のように計算されている。

そして、エントロピーは、
(0.5 x 1 bit) + (0.25 x 2 bits) + (0.125 x 3 bits) + (0.125 x 3 bits) = 1.75 bits
となる。
エントロピーに喩えが多い理由
エントロピーの説明を定性的に、無秩序、不確実性、驚き、想定外、予測不能、情報量などと例えることがよくある。
エントロピーが高いとは、平均のメッセージのサイズが大きいことを意味する。
つまり、メッセージにたくさんのタイプがあり、ビット数をより多く必要とすることになる。たくさんのことがランダムに起きれば毎回異なるメッセージを受けるのと同様なので無秩序、不確実性、予測不能などの形容がなされる。
そんな中に滅多に生じないメッセージやイベントがあれば、驚きをもたらす。夏に雪が降るとか、1000年に一度の地震とか。
稀な情報はより多くのビット数で記述されるので情報量が多いとも言える。また、普段よく起こることは少ないビット数で記述されるので情報が少ないことになる。定性的にも、稀な情報にはより多くの意味が込められていると考えることもできる。
違う見方をすると、稀な情報を受け取ると、その他の多くの情報の可能性が取り除かれるとも考えられる。つまり、晴れが99%の国で、大雨が降ると99%の可能性が取り除かれ、残り1%内の出来事に絞られる。大雨という状況に限定される。
エントロピーが大きいほど特別な情報を持ったイベントが生じやすい。エントロピーが小さいほど平凡な情報しか得られない。毎日「晴れ」しかない地域ではエントロピーがゼロになる。
情報に変化がないので伝えることがないからだ。
$$
P_{晴れ} = 1.0 \ \rightarrow \ −\log_2 P_{晴れ} = 0
$$
以上で、情報エントロピーの解説は終わる。
エントロピーに対するあなたの理解度の分布でエントロピーを計算したら0になることを祈る。
もちろん良い意味で。
関連記事
この記事が気に入ったらチップで応援してみませんか?