
【動画レポ】BigData-JAWS 勉強会 #23

今日は先日2023年3月15日に開催されたJapan AWS usergroup(JAWS UG)のBigData支部のイベント「BigData-JAWS 勉強会 #23 」の紹介をします。
イベントにも参加(Youtube視聴)したのですが、ところどころちゃんと聞けなかったところもあるのでしっかり復習したいと思います。今回はAWSだけでなくSnowflakeさんも登場するなど楽しみな内容です。
<動画>Youtube
オープニング
オープニングは運営のアイレット大石さん。ここでは初司会らしいです。
まずはAgendaの紹介です。今回は4人のバラエティーに富んだメンバーが登壇します。

EMR Serverless導入してみた
-Sparkによるペタバイト級統合データ分析基盤ETL処理
NTTドコモ 東野さん、松原さん、田中さん
0:04:42~
一番手は今回こういう場は初めてというNTTデータの東野さんからの発表です。
自己紹介
NTTドコモ R&D イノベーション本部サービスイノベーション部所属
データ分析基盤の構築を担当

ビッグデータ統合分析基盤(IDAP)概要
基地局やサービスからデータやログを抽出してGCPのBigData、AWSのRedshiftに集約しサービスやネットワークの分析を行う基盤
・数ペタバイトクラスのビッグデータ
・利用者は社内のサービス分析をされている人を中心に2500人
・一部のデータタイプの分散処理をフルスクラッチで実装

対象システムが限界
・200GB/HのN/W情報のバイナリデータをcsv変換しRedshiftにロード

・処理速度が限界
・オートスケーリングできない
・独自実装なので俗人化しやすくメンテナンスコストが高い
⇒最近GAしたEMR Serverless を見つけた
~Spark、負荷分散、オートスケーリング対応
EMR Serverless導入

構成:対象データが非常に大きい⇒最強の構成にした。
・バージョンは最新のもの
・パラメータは最強


⇒コストが予想以上かかってしまった
チューニング開始
EMR Serverlessのリソース使用量を最適化
vCPU数に比例して割り当てられる最大メモリサイズが変わる
Sparkの処理
・ファイル数が非常に増えているのがポイント

リソース使用量改善
1.処理アルゴリズムの最適化
アルゴリズムが良くなれば性能はよくなる
2.パラメータチューニング(採用)
1回のジョブでどのように処理をするか、
パラメーター/アルゴリズムを変える
3.パーティションチューニング(採用)
1回あたりExecuterがどれくらいさばいていくか
効果がなかったパラメータ
・maxPartitionBytes:理由は不明だが効果がなかった
・g1gc:理由は不明だがむしろ使用リソースが増えてしまう
効果があったパラメータ
・task cpus:ほぼほぼすべて、実は2つのcpuが遊んでいた・・・
1つのジョブで使用するcpuの数

もっとコストを下げる~AWSのサポートから
・メモリが足りなくてCPUが遊んでいる
リパーティション(ファイルの分配しなおし)を入れてみる

300個に分解した処理⇒コスト改善ができた

たどり着いた今のベスト
・タスクのCPU数は2つでよかった
・李パーテーション550に分けたのは効果が高かった
・こういった地道な作業が中心

良かった点
・EMR Serverlessが結構いい感じにスケーリングしてくれた
ファイルの解凍がなければそのままでも良い性能だった
・AWSさんのサポートが結構手厚かった
何度も相談の場を開いてくれた
反省&改善点
サンプルデータの選び方
・検証ほどの効果が本番では出なかった
・最小、中央値、最大サイズを使ったが最小の影響が大きかった
アルゴリズムの改善はこれから着手する
・一部残ったPythonをjava化してガベージコレクションをへらす
AWS上で始めるモダンデータアーキテクチャとデータ活用に向けたアプローチ:ナレッジコミュニケーション中西さん
次はナレッジコミュニケーションの中西さんによるAWS上でデータ活用をするのに人・ビジネス・システム 〜データ基盤を取り巻く課題に対してどんなアプローチが有るかという話でした。
1.どうしてデータ活用が難しいか?
・日本におけるデータを活用したサービス・製品開発の割合は20%
・データの収集・蓄積・処理の導入をしている企業は30%
・多くの経営幹部がAI・データ分析への関心
〜どうしてそういった状況に陥るのか?
・でデータは「なんとなくある」存在
2.アーキテクチャで考えるデータ活用
データに関わる人の関心事は「データウェアハウス」だがデータを活用するために必要なエンジニアリングは多岐にわたる

⇒必要なところ全ては埋まらない
・貯めるのみで活用されない
・分析のエンジニアリング要素は全体の5%以下でしかない
取り組んだ事例:ブックリスタ様
・Redshiftにためているデータを活用したい
・サービスとデータ提供の組み合わせで乗り換える
Redshift MLとSageMaker Autipilotの機能の組み合わせ
⇒SQLだけで機械学習の推論モデルが出来た
シンプルなSQLのみで実装が出来た
AWSは監視機能が便利
・Amazon SageMaker Model Moniterでワンストップ
どうML Opsに発展させていくか

これを実現するには?
・AWSのピタゴラスイッチは大変
・実施できる人材が居ない
・自分たちにはまだ早い
3.どうアプローチをしていけばいいか
mipoxさんの事例
・データ分析業務の内製開発
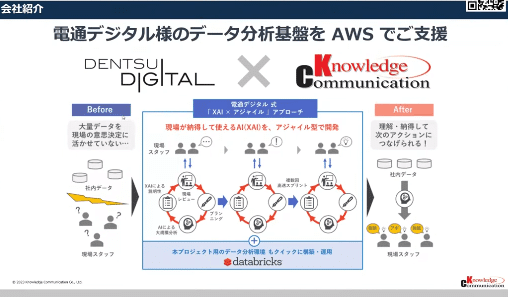
DataBricksというサービスを導入
モダンなアーキテクチャがDatabricksで提供される
・インフラはS3とEC2

・データ活用に必要なすべての領域をカバー
Databricks:近年は充実した機能に進化
Databricksの価値〜基盤検討から価値創造へ
・SQLの形式で検索や分析ができる
・AutoMLの機能を最初から用意
・ひとつのnotebookでデータパイプラインを構築できる
・データ管理ができる
・どんな分析をしたかが公開されている

⇒Mipox様の声
・初歩的なPython、SQLで分析できた
・アーキテクチャを意識なくても基盤を持てる
・2ヶ月ほどで社内AIツールを開発
Databricksはまだまだ普及していない
・導入までの過程が必要
AWS SUMMITに出展します
まとめ

AWSのパワーでコラボレーション促進!Snowflake データクラウドの話 / Snowflake KTさん
つぎはSnowflakeでプロダクトマーケティングをしているKTさんのセッションでした。もちろんSnowflakeの話です。
BIG DATA IS DEAD
・本質的なことはデータの量ではなく何に使っていくか?
・人はデータの分量に頭を悩ますのではなく何をしたいのか?
・どんな世界をもたらしたいのか、どんなビジネスを打ち出したいのか?
〜そういう様になっていかないといけない
SnowflakeはAWSの潤沢なリソースを効率よく仕様
〜リソースマネジメントの悩みに終止符を打つ
Snowflakeのミッション
To Mobilize the World's Data(世界のデータをもモビライズ)
・ありとあらゆるデータを使いたいと思った時に使える
・自分が持っているデータだけでは立ち行かなくなってきている
⇒データクラウド
・グローバルなネットワーク
・プラットフォームに様々なコンテンツ
(データ・サービス・アプリケーション)
いろんなひとが集まって様々なコンテンツを置いてこそ完成する

データクラウドに向けたイノベーションの流れ
7つの柱で構成されている

プラットフォーム要件
・どんなワークロードも迅速に処理
・要求通りに機能
・本当に重要なものにつながる
〜あまり果たされていないのが今まで
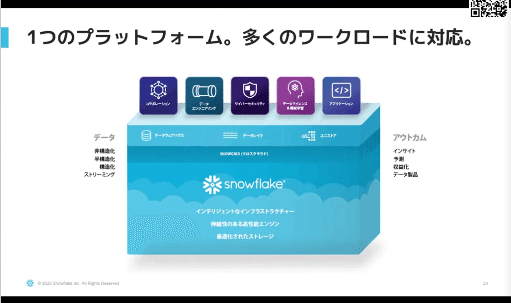
Snowflakeのアーキテクチャ
最適化されたストレージ

・どんなデータも入れられる
・非常に圧縮率が高い、使えば使うほど高くなる
・他のストレージのデータにもアクセスできる
伸縮性のある高性能エンジン

・リソースマネジメントからの解放
・データを入れるリソースと参照のためのリソースを同じアクセス
・アクセスとプログラミングを実現(SQL、Python、java・・)
インテリジェントなインフラストラクチャー

・セルフマネージド:管理や調整を簡単に、何もしなくても良い
・本当に大切なことに集中
多くのワークロードをサポート

・データウェアハウス、データレイク
・アプリケーション
一元化されたガバナンス

・データの把握
・データの保護
・エコシステムとの接続
経済性の継続的改善

・色んな所のパフォーマンスが上がっていく
・新機能追加だけでなく既存の機能の強化もされていく
・ユーザは何にもしなくても良くなっていく
・使った分の料金体系なので効率化すると安くなる
Snowgrid(クロスクラウド)

・複数のクラウドやリージョンをメッシュのようにつなげる
・クロスクラウドのコラボレーション
・クロスクラウドのガバナンス
・クロスクラウドの事業継続性
Snowflakeがデータコラボレーションを実現
従来:FTP、API、ETL・・・・
⇒プライバシー保護型コラボレーション

・相手にデータを送るのではなく、相手にデータを見せる
・データは共有、処理は自分のリソースを利用する
Snowflakeマーケットプレイス
・260を超えるプロバイダーを活用できる
次のイノベーションの波を取り入れる
アプリケーション開発に革命を起こしたい

データクラウドでの製品化
Snowflake上でアプリケーションの配布と収益化

⇒シェアリングが加速していく 可能性は無限大
・データクラウドは急加速でどんどん増えていく
・インターネット黎明期を彷彿させる
Amazon DataZoneとAWS Clean Roomsのご紹介:AWS 佐藤さん
最後のセッションはAWSの佐藤さんから。Amazon DataZoneとAWS CleanRoomsの紹介です。
AWSのデータ分析に対するメッセージング
データ活用を阻む3つの要因
・データのサイロ:データの分散保管
・人のサイロ:色々なスキルを持った人が平等にアクセス
・ビジネスのサイロ:レガシーなシステムもサポート
これらのサイロを解消するのがDataZoneとCleanRooms
Amazon DataZone
ビジネスメタデータを管理するデータカタログ
ガバナンスを保ちつつデータ共有をサポートする
Amazon DataZoneの4つの柱

全社的なビジネスデータカタログ

・クロールしたデータはすべてDataZoneで管理できる
・データカタログ作成のサポート
セルフサービスポータル

データを共有したいプロデューサ、利用したいコンシューマ、場を管理したい管理者の3者のやりたいことができる
・入力レコメンド、アセット検索・・・・
分析へのアクセスを容易に

・データプロジェクトという概念がデータ共有の境界
・各プロジェクトと1:1で対応、それをつなげる場を提供
・データカタログにデータをPublishし、利用時にはカタログを経由してサブスクライブする
・DeepLink:データプロジェクトのデータに対して迅速にデータ分析のためのリンクを提供する

ガバナンスの効いたデータ共有

・iamを利用した認証がベース
・oktaなどを利用してアクセスすることも可能
・ロールに見合った利用を制御する
セルフサービス型データ共有
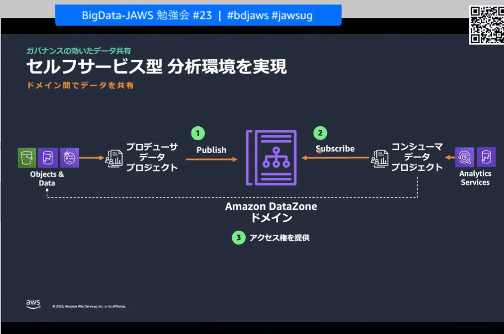
・クラウドの管理者はいっさい関わらないそれぞれがセルフで行う
Datazoneが実現するデータアーキテクチャ

・企業が成長してゆくといろんなビジネスを展開
それぞれでデータ分析基盤を作る
⇒それらの統合に対応できるような形の統合的なアーキテクチャ
Data Mesh

・分散型オーナーシップ
・統合的なガバナンス
・ピアツーピアなデータ共有
・セルフサービスインフラ
AWS Clean Rooms
企業間のサイロを解消するためのサービス
簡単にAWSアカウント間で安全に共有する場を作成する

コラボレーションという場
・5つのAWSアカウントをコラボレータという形で追加できる
・各コラボレーターは自身のデーターをコラボレーションに紐づけ
・統計データだけ共有することもできる
・相互のデータのジョインさせ、相手がヒットしたものだけ共有
分析ルール

・様々な制御条件でデータを相手と共有できる
・集約化とリスト化
暗号化コンピューティング
個人情報などを独自に暗号化

・暗号化したデータでも集約化や突合などの制御ができる
まとめ
DataZoneとCleanRoomの2つの機能を紹介
DataZone:組織内のサイロ解消
CleanRoom:企業間のサイロを解消
いまはPreview、これからGAになる
クロージング
運営、登壇者募集中です

次回はQuicksight回になります

いいなと思ったら応援しよう!
