【Python】pyppeteerでスクレイピング

今回はpyppeteerの紹介。
selenium+chromeだとchromedriverをchromeのバージョンに合わせて準備しないといけない点が面倒だと思います。
自動でアップデートする方法もあるようですが、その準備も面倒。
pyppeteerだとそのあたりの手間は不要です。
ただ、情報が少ないのと、非同期IOプログラミングが必須になるのでseleniumより敷居が高い印象です。
環境
・python3.7
pyppeteer 0.2.2
websockets 8.1
・Windows10
準備
pip install pyppeteerサンプルコード
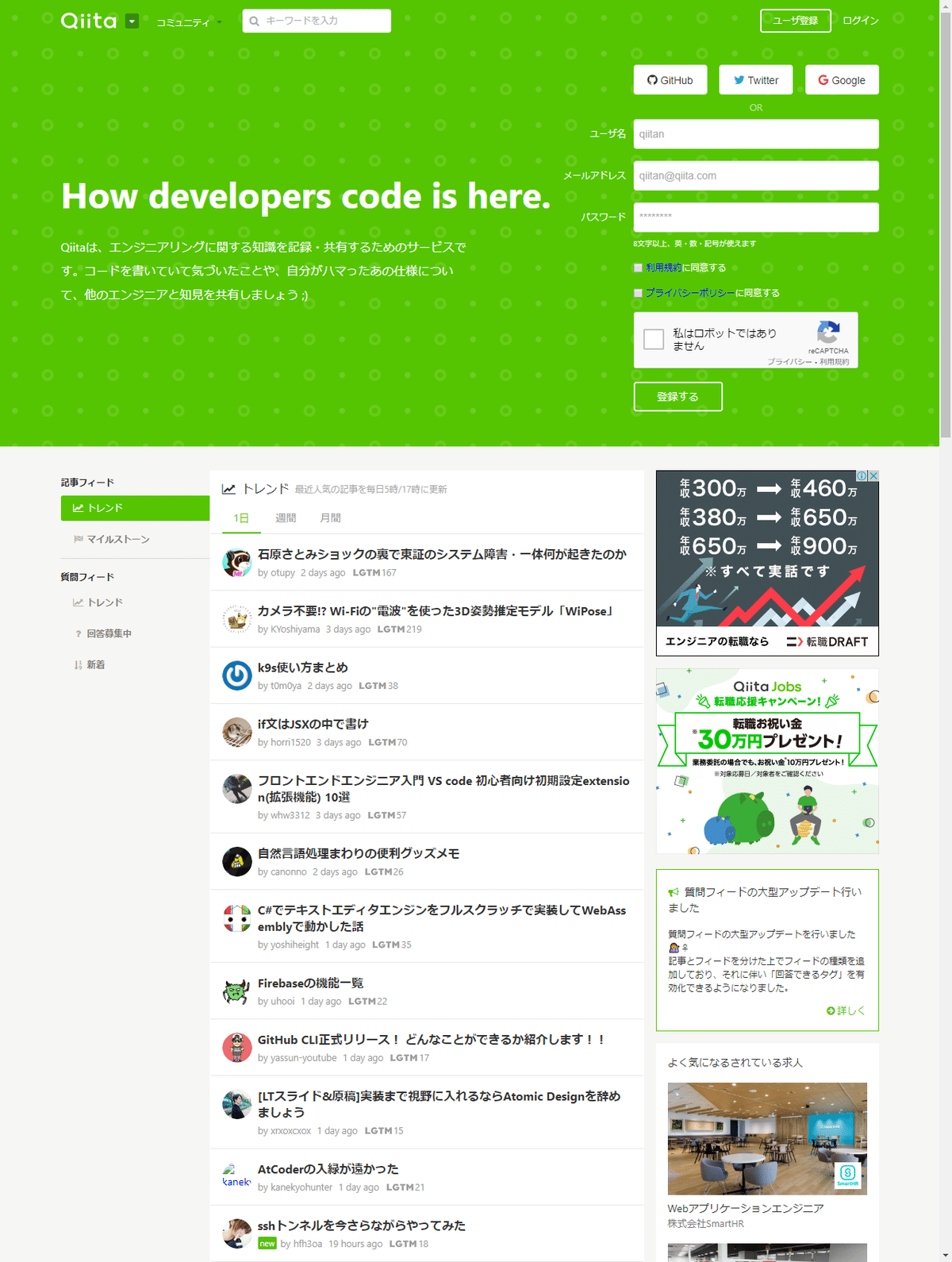
以下は、Qiitaにアクセスして、コミュニケーションをクリック。
プルダウンメニューから「Qiita Jobs」をクリックして、新しいタブで開いた画面のスクリーンショットを取得するコード。
#!/usr/bin/python
import asyncio
from pyppeteer import launch
async def html_parse(html):
from bs4 import BeautifulSoup
print("htm解析")
soup = BeautifulSoup(html, 'html.parser')
async def main():
# ブラウザ起動
# 初回はChroniumのダウンロードが実施される
print("ブラウザ起動")
browser = await launch(headless=False, args=["--no-sandbox"])
# 新規タブ追加
print("新規タブ追加")
page = await browser.newPage()
# ウィンドウサイズ設定
await page.setViewport({"width": 1280, "height": 1696})
# サイトを開く
print("ウェブサイトを開く")
await page.goto("https://qiita.com/")
# スクリーンショット取得
print("スクリーンショット1を保存")
await page.screenshot({"path": "./sceeenshot1.png"})
# 「コミュニティ」をクリック
await page.click("div.st-Header_community")
# 「Qiita Jobs」をクリック ※新規ウィンドウが開く
css_selector = "#globalHeader > div > div.st-Header_start > div:nth-child(3) > div.st-Header_dropdown.is-open > a:nth-child(4)"
result_page_future = asyncio.get_event_loop().create_future()
browser.once("targetcreated", lambda target: result_page_future.set_result(target))
await page.waitFor(css_selector)
await page.click(css_selector)
# 新規ウィンドウのオブジェクトを取得
print("新規ウィンドウのオブジェクトを取得")
new_page = await (await result_page_future).page()
# ページHTML取得
print("HTMLを取得")
html = await new_page.content()
await html_parse(html)
# スクリーンショット取得
print("スクリーンショット2を保存")
await new_page.screenshot({"path": "./sceeenshot2.png"})
# ブラウザ停止
await browser.close()
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())実行結果
ブラウザ起動
新規タブ追加
ウェブサイトを開く
スクリーンショット1を保存
新規ウィンドウのオブジェクトを取得
HTMLを取得
htm解析
スクリーンショット2を保存screenshot1.png
screenshot2.png
