
C言語教室 解答編 第19回 - リスト構造についての補足

おまたせしました。今回は
C言語教室 第19回 - 単方向リスト
の解答編です。いきなりリスト構造の操作を課題に出しましたが、やはり少々難易度が高かったのかもしれません。ここまでで文字配列でポインタ操作を覚え、構造体という仕組みを学びましたが、このようなC言語の文法は、言ってみればリストやツリーといったデータ構造を使うための道具だったんです。ようやく今までの知識が活かせるわけです。
我が家の教室でも、なかなか理解が難しかったようで、そもそもリストがどうして登場するのかが判らず、どのように使うものなのかが見えないので、具体的な処理を示してもピンと来なかったようです。
そこで、もう少しリスト構造について説明をしておこうと思います。まだ課題に挑戦していない方は、以下の説明に目を通してから課題に挑戦していただけると幸いです。
コンピュータのプログラムに於いては、多くのデータを扱うので、それらをどのように関連付けて読み書きするのかで、使用するメモリの大きさや処理のパフォーマンスに大きく影響します。最初に説明した配列という仕組みは、要素の番号を使うことで、どの要素にも一発で読み書きできますし、先頭のアドレスと何番目という情報以外に何かを覚えておく必要がないので、利用するメモリの大きさも最低限です。但し、もうお気づきかもしれませんが、予め何個の要素を必要とするのかを決めておく必要がありますし、後から要素の数を増やすには、新しい配列を用意して今までの内容をコピーするしかありません。
この為、配列以外にもいろいろな多くのデータを関連付けて扱う方法が用意されています。C言語よりモダンな言語であれば、リストやスタック、キュー、連想配列、ツリーといったコレクションと呼ばれるような仕組みが用意されています。それぞれの仕組みは良し悪しがあるので、用途によって使い分ける必要があります。残念ながらC言語には、これらの仕組みが用意されていないので自分でデータ構造を定義して関数を用意する必要があります。
Collection (abstract data type) - 英語ページですいません。翻訳して読んで下さい。
今回、扱っている単方向リストは、要素の数を増やしたり減らしたり並べ替えるのが得意なのですが、読み書きするには常に先頭から要素を辿る必要があるので、やや遅くなりますし、要素ごとに次の要素のアドレスを記憶する必要があるので、メモリ使用量もやや増えます。ファイルであるとかネットワーク上からデータを得るときに、データの数を決めるのは、前もってデータの数をやりとりするように工夫しない限り現実的ではなく、大抵は最大値を仮定して処理することになるのですが、そうすると無駄になるとわかっていても、とても大きな領域を用意することになります。そう考えると多少、読み書きに余分な処理が必要になるとしても、リスト構造を使って処理をすることで、要素の数をあまり気にせずに処理を進めることが出来ます。
他の言語であればリスト処理は用意されているものを使えば間に合うとはいえ、これらをC言語でしっかり理解しておくことにより、その特性を理解することが出来ますし、何らかの不具合(バグ)が出たときにも、その原因を追うのが楽になります。特にメモリ使用量やパフォーマンスは、そのための測定をしない限り、結果に変化は無いので、見落としやすいのですが、とても多くのデータを扱うときには、実はかなりの影響がでるので、しっかりと身につけることはとても大事です。
あらためて単方向リストを説明すると、ひとつのデータはノードという構造を持っており、ノードには値と次のノードへのポインタがあります。またリスト全体の先頭へのポインタを持つことでリストを管理します。

ノードを追加するには、新しくノードを作ってから、それを既にあるノードのポインタを繋ぎ変えることでリストの一員にします。
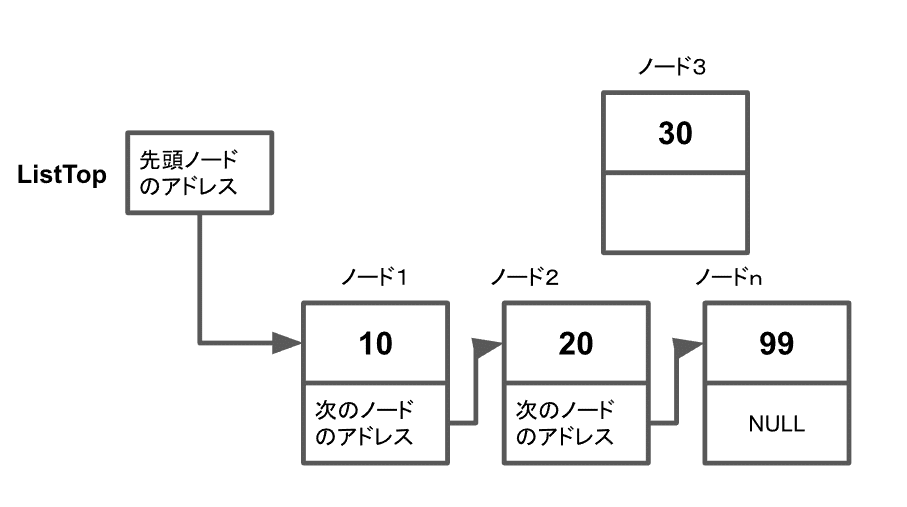

この方法は、既にあるノードが必要なので、先頭にノードを追加する時だけは別の処理になり、追加するノードの次のノードのアドレスとして先頭ノードのアドレスを入れ、先頭ノードのアドレスとしてに追加したノードのアドレスを入れます。
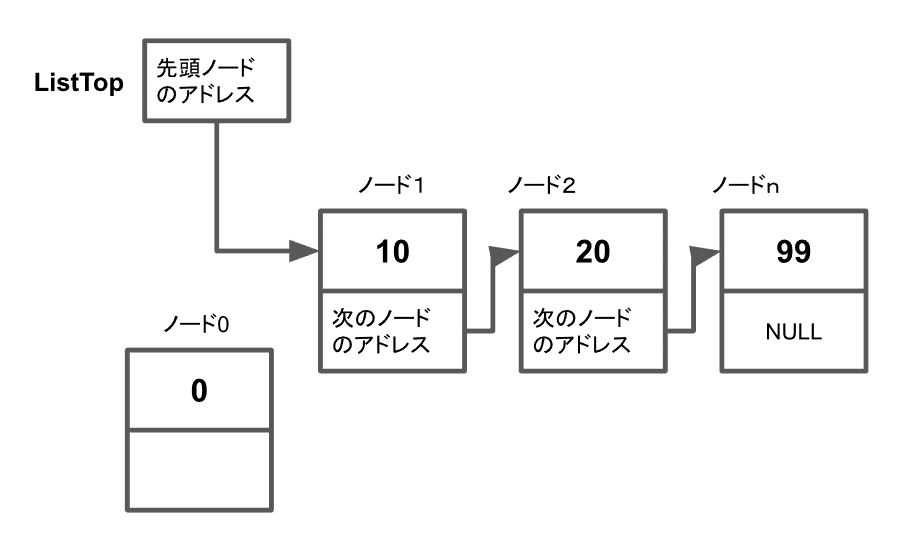

この例外があるのが、少しやっかいです。削除に関しても同様で、途中のノードを削除する時には、前のノードが持っている次のノードのアドレスを、削除するノードが持っていた次のノードのアドレスに変えれば良いのですが、先頭のノードを削除するときだけは、先頭ノードのアドレスを変えてやる必要があります。
やはりC言語でポインタに依る処理を書く時には、ここで示したような箱の図を自分で書いて、どのような関係になるかを見ながらコードを書いていくのが良いようです。削除の場合の図は、せひ自分で書いてみてください。
そろそろ解答に移りましょう。今回の課題は
課題
・リストの要素の数を返す関数を書きなさい。
・リストの最後に要素を追加する関数を書きなさい。
・リストの先頭の要素を削除する関数を書きなさい。
・n番目の要素を返す関数を書きなさい。
でした。
順に進めましょう。単方向リストで要素の数を返す関数の例を示しますが、構造体名は typedef しないコードにしました。またノード構造体は関数の外側で作り解放も外でやる例になっています。
#include <stdio.h>
#include <stdlib.h>
// リストのノードを表す構造体
struct node {
int data; // データ
struct node* next; // 次のノードへのポインタ
};
// リストの要素数を返す関数
int count_elements(struct node* head) {
int count = 0;
struct node* current = head; // 現在のノードを表すポインタ
while (current != NULL) { // ノードが存在する限りループ
count++; // 要素数をカウント
current = current->next; // 次のノードに進む
}
return count;
}
// テスト用のメイン関数
void main() {
// リストを作成する
struct node* head = NULL;
struct node* second = NULL;
struct node* third = NULL;
head = (struct node*)malloc(sizeof(struct node));
second = (struct node*)malloc(sizeof(struct node));
third = (struct node*)malloc(sizeof(struct node));
head->data = 1;
head->next = second;
second->data = 2;
second->next = third;
third->data = 3;
third->next = NULL;
// 要素数を表示する
int count = count_elements(head);
printf("要素数: %d\n", count);
// リストの解放
free(head);
free(second);
free(third);
}これでしっかり以下の出力が得られるはずです。
要素数: 3次は最後に追加する例です。
#include <stdio.h>
#include <stdlib.h>
/* リストのノードの定義 */
typedef struct node {
int data;
struct node *next;
};
/* 新しいノードを作成する関数 */
struct node* create_node(int data) {
struct node* new_node = (struct node*) malloc(sizeof(struct node));
new_node->data = data;
new_node->next = NULL;
return new_node;
}
/* リストの最後に要素を追加する関数 */
void append(struct node** head_ref, int data) {
struct node* new_node = create_node(data);
struct node* current = *head_ref;
/* 空のリストの場合 */
if (current == NULL) {
*head_ref = new_node;
return;
}
/* 最後のノードを見つける */
while (current->next != NULL) {
current = current->next;
}
/* 最後に新しいノードを追加する */
current->next = new_node;
}
/* テストするメイン関数 */
void main() {
struct node* head = NULL;
append(&head, 1);
append(&head, 2);
append(&head, 3);
/* リストの要素を表示する */
struct node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
}結果は以下になります。
1 2 3 次は最初の要素を削除する関数の例を示します。
#include <stdio.h>
#include <stdlib.h>
// リストのノードを表す構造体
struct node {
int data; // データ
struct node* next; // 次のノードへのポインタ
};
// リストの最初の要素を削除する関数
struct node* delete_first_element(struct node* head) {
if (head == NULL) { // リストが空の場合
return NULL; // 何もしない
}
struct node* new_head = head->next; // 新しい先頭のノードを取得する
free(head); // 元の先頭のノードを解放する
return new_head; // 新しい先頭のノードを返す
}
// テスト用のメイン関数
void main() {
// リストを作成する
struct node* head = NULL;
struct node* second = NULL;
struct node* third = NULL;
head = (struct node*)malloc(sizeof(struct node));
second = (struct node*)malloc(sizeof(struct node));
third = (struct node*)malloc(sizeof(struct node));
head->data = 1;
head->next = second;
second->data = 2;
second->next = third;
third->data = 3;
third->next = NULL;
// リストの先頭の要素を削除する
head = delete_first_element(head);
// リストの要素を表示する
struct node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
// リストの解放
free(second);
free(third);
free(head);
}これを実行すると
2 3 と出力されて、最初の要素が削除されていることが確認できます。
最後の課題はn番目の要素を返す関数です。
#include <stdio.h>
#include <stdlib.h>
// リストのノードを表す構造体
struct node {
int data; // データ
struct node* next; // 次のノードへのポインタ
};
// リストのn番目の要素を返す関数
struct node* get_nth_element(struct node* head, int n) {
int count = 0;
struct node* current = head; // 現在のノードを表すポインタ
while (current != NULL) { // ノードが存在する限りループ
if (count == n) { // n番目の要素に到達したら
return current; // そのノードを返す
}
count++;
current = current->next; // 次のノードに進む
}
return NULL; // n番目の要素が存在しない場合はNULLを返す
}
// テスト用のメイン関数
void main() {
// リストを作成する
struct node* head = NULL;
struct node* second = NULL;
struct node* third = NULL;
head = (struct node*)malloc(sizeof(struct node));
second = (struct node*)malloc(sizeof(struct node));
third = (struct node*)malloc(sizeof(struct node));
head->data = 1;
head->next = second;
second->data = 2;
second->next = third;
third->data = 3;
third->next = NULL;
// 2番目の要素を取得する
struct node* element = get_nth_element(head, 1);
if (element != NULL) {
printf("2番目の要素: %d\n", element->data);
} else {
printf("2番目の要素が存在しません。\n");
}
// リストの解放
free(head);
free(second);
free(third);
}実行すると
2番目の要素: 2と2番めの要素の値が出力されます。
コードとして示すには、都度リストを生成して確認するコードが必要なので、少し長くなっていますが、肝心な処理自身はそんなに難しいものではありません。基本的には先頭から順にポインタを辿る処理が書かれているだけです。ここではノードの作成は関数の外側で行いましたが、関数の側でノードを作成したほうが呼び出し側の手間は減るので、これをさらに直して自分で便利だと思うコードに直してみてください。
一通り、リストにも慣れたと思いますので、演習も済ませましょう。
演習
・リストを配列にコピーする関数を書きなさい。
・配列からリストを作る関数を書きなさい。
リストから配列を作るには以下のようにします。
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
struct node* next;
};
void copyListToArray(struct node* head, int* arr, int size) {
struct node* current = head;
int i = 0;
while (current != NULL && i < size) {
arr[i] = current->data;
current = current->next;
i++;
}
}
void main() {
// リストを作成
struct node* head;
head = (struct node*)malloc(sizeof(struct node));
head->data = 1;
head->next = (struct node*)malloc(sizeof(struct node));
head->next->data = 2;
head->next->next = (struct node*)malloc(sizeof(struct node));
head->next->next->data = 3;
head->next->next->next = NULL;
// 配列を作成
int size = 3;
int* arr = (int*)malloc(sizeof(int) * size);
// リストを配列にコピー
copyListToArray(head, arr, size);
// 配列を表示
printf("Array: ");
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
printf("\n");
free(arr);
free(head->next->next);
free(head->next);
free(head);
}結果は
Array: 1 2 3 となります。配列からリストを作る方は
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
struct node* next;
};
struct node* createListFromArray(int* arr, int size) {
struct node* head = NULL;
struct node* tail = NULL;
for (int i = 0; i < size; i++) {
struct node* newNode;
newNode = (struct node*)malloc(sizeof(struct node));
newNode->data = arr[i];
newNode->next = NULL;
if (head == NULL) {
head = newNode;
tail = newNode;
} else {
tail->next = newNode;
tail = newNode;
}
}
return head;
}
void deleteList(struct node** head) {
struct node* current = *head;
struct node* next = NULL;
while (current != NULL) {
next = current->next;
free(current);
current = next;
}
*head = NULL;
}
void printList(struct node* head) {
struct node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
void main() {
// 配列を作成
int size = 5;
int arr[5];
arr[0] = 1;
arr[1] = 2;
arr[2] = 3;
arr[3] = 4;
arr[4] = 5;
// 配列からリストを作成
struct node* head = createListFromArray(arr, size);
// リストを表示
printf("List: ");
printList(head);
deleteList(&head);
}出力は以下のように出るはずです。
List: 1 2 3 4 5 白状するとコードを書くのに ChatGPT君に助けて貰ったのですが、書くたびに構造体の定義が変わったり、確保したメモリの解放を忘れたりするので、気が抜けません。それからブラウザ版で動くようにも手を入れました。
さてさて今回も Akio van der Meer さんから答案を頂くことが出来ました。
C言語教室 第19回 - 単方向リスト
なかなか苦労されたようですが、追記で作られたコードの方を見させて頂きました。結果の確認はされているので、やはりポイントはダブルポインタの部分のようですね。
ダブルポインタは、
C言語 - main関数の引き数を組み立てる
でコマンドラインが char** となっている部分で、サラッと登場していたのですが、やはり躓く部分であるようです。
今回あらためて説明した図の部分を見てもらいたいのですが、関数の中で、ポインタ変数のアドレスを書き換えたいので、ポインタ変数のアドレスを関数に渡す必要があるわけです。ポインタ変数が Node* という型なので、この変数のアドレスをとるには Node* の & を使いますし、受け取る方は Node* の * になるので、型としては Node** という書き方になるわけです。
思い出してください。呼び出した関数の中で変数の値を変更したい時には、変数へのポインタを引き数で渡すことで、値を変更することが出来ました。同じようにポインタ変数の値を呼び出した関数の中で変更したい時には、このポインタ変数のアドレスを引き数で渡すのです。つまりポインタ変数のアドレス、ポインタへのポインタ(ダブルポインタ)が引き数の型になるわけです。
何だかとてもややこしく見えるかもしれませんが、順序を追って考えれば、どうということはありません。どうしても判りにくいと思えば typedef を使って表現を分解してください。intへのポインタのアドレスは int** になりますが、ここで intへのポインタを int_ptr と typedef すれば int_ptr* と見覚えのある形で表すことが出来ます。
残念なことにC言語らしいややこしさは、この程度では済まず、厳密にはこれに const が関係すると慣れていても途方に暮れることがあるのですが、ひとつずつ分解し、その意味がわかれば、どうしてその書き方が必要なのかだんだんわかってくると思います。
2023.4.15 追記
その後、AyumiKatayama さん からの答案を頂きました。
C言語教室 第19回 - 単方向リスト(回答提出)
ありがとうございます。コメントが遅くなり申し訳ありません。
やはりリストは腕がなりますよね!この手のプリミティブなコードを書く時は、以前に書いた時に気になっていたことを、今度はもっとうまくやろう、どう解決しようかといつも悩みます。
提出されたコードを見ると、今回も const にこだわりを感じます。また全体的にきちんと戻り値を設定されているようで、私の解答よりきめ細かなコードになっていると思います。
実はもう少しきちんと戻り値を設定したり、ところどころエラーチェックをしようかとも思ったのですが、コードがどんどん複雑になって、本来の処理を読み取るのが難しくなってしまったので、敢えて省きました。自分で使うコードにするのであれば、assert入れたりデバッグ情報を出したりするコードを忍ばせるような気もしますし、少しでも速度を稼ぐためにメンバ変数の順序も入れ替えると思います。
for か while かについては、悩ましいのですが、イテレートしている時は for を使い、単なるループであれば while を使うようにしているつもりですが、必ずしもそうなっていません。デバッガを使う時は行単位の方が都合が良いので、for は注意して書かないと使いにくいことはあります。
数を数えるコードですが、私もカウンタを持つことを考えたのですが、内部情報をよほど上手に隠蔽できないと、一貫性の保証ができません。簡単に外部で Node を繋ぎ変えることが出来る以上、その場で数えるしかないと思います。STL の list のコードを確認しましたが、やはり数えていました(このメソッドはサイズに対してリニアな処理時間がかかるよとまで書いてありました)。
そういえば、手元の環境でコードを実行すると、printf の結果が物凄く微妙に異なっていました。もちろんポインタの値が異なるのは当たり前ですが、0x0 とはならずに 0 が並ぶんですよね。python で良くやるようなテストだと、こういう時に Fail してしまうので、気になってしまいました。
久しぶりにリストのコードを書いていて、最後に書いたときのことを思い出しました。スレッドセーフにするためには、どこがアトミックなんだと悩み、どのレベルで担保するのかで const と戦ったような気がします。でも具体的にどう悩んだのかはスッカリ忘れてしまいました。スレッドをやるまでには思い出さないと。
ここまでが追記部分です。
いやぁ、今回はどう説明したら良いのかかなり苦労しました。まだまだ充分に説明できているとは思っていませんが、理解の一助になっていれば幸いです。
次回は、双方向リストを取り上げます。
ヘッダ画像は、いらすとや さんより
https://www.irasutoya.com/2020/04/blog-post_243.html
#C言語 #プログラミング講座 #答え合わせ #単方向リスト #ポインタ #構造体 #引き数 #ダブルポインタ
いいなと思ったら応援しよう!
