
ChatGPTのトークン数の説明がいい加減なのはOpenAIがいい加減だから

ChatGPTをAPI経由で利用すると、入出力のトークン数で課金されます。トークン数とは何か、日本語のいい加減な情報が多く、元の情報を調べもせずに知ったかする人が間違いを再生産しています。
もっともいい加減な説明
英語は1単語=1トークン、日本語は1文字=1トークンという説明があります。間違いです。実用上の英単語で一番長いとされる「antidisestablishmentarianism」は6トークンです。

ところが、「こんにちは」は1トークンです。

多少マシに見えて間違った説明
3字以下の英単語は1トークン、4字以上は3字ごとに1トークンになる、ひらがなは1字3トークンという説明も見かけますが間違いです。fail, hail, jail, mail, nail, rail, sail, tailは1トークンですが、bail, pail, wail, zailは2トークンです。

「あいうえお」は4トークンですが、

「かきくけこ」は5トークンです。

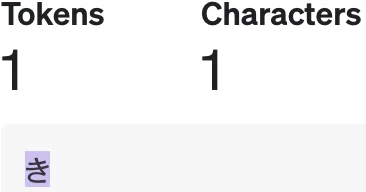
ひらがなは2トークン、漢字は3トークンという説明も見かけますが、これも間違いです。「き」は1トークンです。
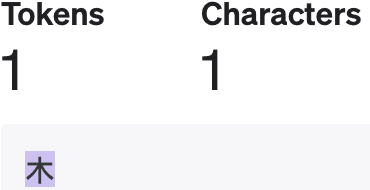
「木」も1トークンです。
どうすればいいのか?
あるテキストのトークン数を画面で調べたいときは、Tokenizerを使って調べるしかありません。プログラム的に知りたいときはTiktokenというふざけた名前のツールで調べます。
概算を知りたい場合は、OpenAI自身の説明では英単語はトークン数の4分の3になる、つまり100トークンは約75語換算になります。英語以外の簡易な換算方法はありません。これ以上の説明がないから、適当な説明がまん延するのです。
日本語のトークン数は、たとえば「古池や蛙飛びこむ水の音」は11字で18トークン、「やせ蛙負けるな一茶これにあり」は14字で16トークン。漢字よりひらがなは少なめ、難しい漢字より簡単な漢字は少なめ、という傾向はありますが、それだけで計算はできません。トークン数は少ないほうが費用は少なめにはなりますので、日本語テキストをAPIに渡すときは、次の方法がベストプラクティスです。
読点は少なめ、句点は使わない
読点(、)は「ここで、はきものをぬぐ」のように意味的に必要な場合以外使わないほうがよいです。文末の句点(。)は必ず省略しましょう。「。」だけで1トークン扱いです。空白文字や英文の文末の「.」も1トークン消費します。
文字数が同じならひらがなにする
「素晴らしい」は6トークンですが、「すばらしい」は5トークンです。ただし、「出来る」も「できる」も3トークンです。とはいえ、「又は」は3トークンですが、「または」は2トークンです。
冗長な言い回しを避ける
「設定を行うことが可能となっている」は15トークンですが、「設定できる」は6トークンです。
カタカタ語は英語にする
「インクジェットプリンターの特徴は?」は16トークンですが、「inkjet printersの特徴は?」は9トークンです。応答はさほど変わりません。全文を英語に翻訳するよう推奨している人もいますが、意味(ニュアンス)が変わってしまうことがあるので私はおすすめしません。
大量にAPIを呼び出す場合は、こうしたテクニックを駆使することで、費用を抑えられます。