第7章 線形モデル編: 第4節 株価を線形回帰で統計的推論する

とうとう面白そうな章に突入しました(笑)
今までのチャプターも開発環境の設定やデータセットの準備、モデルの紹介等でいわゆるチュートリアルです。ここからやっと予測的なことを始めます。次に節は予測に入りますので、ここから本腰ですよ!
インポートと設定
import warnings
warnings.filterwarnings('ignore')%matplotlib inline
import pandas as pd
from statsmodels.api import OLS, add_constant, graphics
from statsmodels.graphics.tsaplots import plot_acf
from scipy.stats import norm
import seaborn as sns
import matplotlib.pyplot as pltsns.set_style('whitegrid')
idx = pd.IndexSliceデータの読み込み
with pd.HDFStore('data.h5') as store:
data = (store['model_data']
.dropna()
.drop(['open', 'close', 'low', 'high'], axis=1))データのフィルタリング
data = data[data.dollar_vol_rank<100]dollar_vol_rankというのは前回の記事で定義した変数で
prices['dollar_vol'] = prices.loc[:, 'close'].mul(prices.loc[:, 'volume'], axis=0)
prices['dollar_vol'] = (prices
.groupby('ticker',
group_keys=False,
as_index=False)
.dollar_vol
.rolling(window=21)
.mean()
.fillna(0)
.reset_index(level=0, drop=True))
prices.dollar_vol /= 1e3prices['dollar_vol_rank'] = (prices
.groupby('date')
.dollar_vol
.rank(ascending=False))どういうことかって言いますと、銘柄が大体2500銘柄あるんですが、2500銘柄に対して毎日の出来高の上位99銘柄だけを使うという意味です。
モデルデータの作成(目的変数と説明変数の定義)
y = data.filter(like='target')
X = data.drop(y.columns, axis=1)
X = X.drop(['dollar_vol', 'dollar_vol_rank', 'volume', 'consumer_durables'], axis=1)目的変数として1営業日、5営業日、10営業日、21営業日のフォワードリターン(将来価格変化率)とします。
特徴量に関しては様々なテクニカル指標やメタデータが入っていますので、前回の記事で全て定義していますので、ご参照くださいませ。
データの探索
目的変数
sns.clustermap(y.corr(), cmap=sns.diverging_palette(h_neg=20, h_pos=220), center=0, annot=True, fmt='.2%');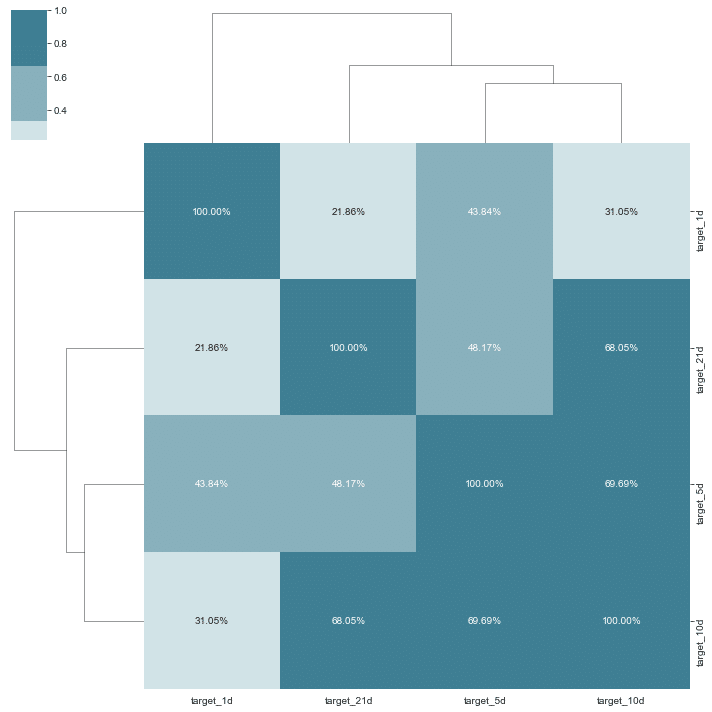
説明変数
sns.clustermap(X.corr(), cmap=sns.diverging_palette(h_neg=20, h_pos=220), center=0);
plt.gcf().set_size_inches((14, 14))
高い相関のペアについて調査します。
corr_mat = X.corr().stack().reset_index()
corr_mat.columns=['var1', 'var2', 'corr']
corr_mat = corr_mat[corr_mat.var1!=corr_mat.var2].sort_values(by='corr', ascending=False)corr_mat.head().append(corr_mat.tail())
線形回帰で統計的推論:statsmodelsを使用したOLS
statsmodelsは、行列が高い条件数で設計されていると警告が出ます。これは、変数が標準化されておらず、スケーリングのために固有値が異なる場合に発生する可能性があります。次の手順では、この警告を回避します。(要するに標準化するってことです)
sectors = X.iloc[:, -10:]
X = (X.drop(sectors.columns, axis=1)
.groupby(level='ticker')
.transform(lambda x: (x - x.mean()) / x.std())
.join(sectors)
.fillna(0))1営業日後リターン
先にサマリー変数について解説します。
R-squared: 決定係数。ピアソンの相関関係の二乗、線形回帰モデルの傾き。
F-statistic: F値。F検定の定義は以下参照。
Prob (F-statistic): F統計量、定義は以下参照。
t: t値。定義以下参照。
P>|t|: t統計量、こちらの回帰分析の係数参照。
F検定定義
F検定には次のようなものがある:
1. 正規分布に従う2つの群の「標準偏差が等しい」という帰無仮説の検定。これはt検定の前段階の「等分散性検定」として用いられる。ただし、このような前段階での等分散性検定の利用は正しくないという指摘も見られる。
2. 正規分布に従う複数の群(標準偏差は等しいと仮定する)で、「平均が等しい」(つまり同じ母集団に由来する)という帰無仮説の検定。この方法は分散分析に用いられる。
一般に統計量Fとは、2つの群の標準偏差の比であって、両群とも正規分布に従う場合にはFはF分布に従う。これを用い、Fの計算値が片側有意水準内に入るかどうかを検定するのがF検定である。
t検定定義
t検定(ティーけんてい)とは、帰無仮説が正しいと仮定した場合に、統計量がt分布に従うことを利用する統計学的検定法の総称である。母集団が正規分布に従うと仮定するパラメトリック検定法であり、t分布が直接、もとの平均や標準偏差にはよらない(ただし自由度による)ことを利用している。2組の標本について平均に有意差があるかどうかの検定などに用いられる。統計的仮説検定の一つ。日本工業規格では、「検定統計量が,帰無仮説の下でt分布に従うことを仮定して行う統計的検定。」と定義している。
target = 'target_1d'
model = OLS(endog=y[target], exog=add_constant(X))
trained_model = model.fit()
print(trained_model.summary())
'''
OLS Regression Results
==============================================================================
Dep. Variable: target_1d R-squared: 0.010
Model: OLS Adj. R-squared: 0.009
Method: Least Squares F-statistic: 18.88
Date: Wed, 17 Jun 2020 Prob (F-statistic): 8.58e-184
Time: 15:16:12 Log-Likelihood: 2.8850e+05
No. Observations: 109675 AIC: -5.769e+05
Df Residuals: 109618 BIC: -5.763e+05
Df Model: 56
Covariance Type: nonrobust
=========================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------------
const -0.0002 0.000 -0.793 0.428 -0.001 0.000
rsi 0.0002 0.000 1.126 0.260 -0.000 0.001
bb_high 0.0002 0.000 0.740 0.459 -0.000 0.001
bb_low 0.0006 0.000 2.560 0.010 0.000 0.001
atr -0.0002 6.61e-05 -3.275 0.001 -0.000 -8.69e-05
macd -0.0005 0.000 -1.992 0.046 -0.001 -7.56e-06
return_1d 0.0029 0.000 9.767 0.000 0.002 0.003
return_5d -0.0019 0.001 -2.073 0.038 -0.004 -0.000
return_10d -0.0064 0.001 -6.434 0.000 -0.008 -0.004
return_21d 0.0028 0.000 6.200 0.000 0.002 0.004
return_42d -0.0035 0.001 -5.830 0.000 -0.005 -0.002
return_63d -0.0020 0.000 -4.350 0.000 -0.003 -0.001
return_1d_lag1 0.0027 0.000 9.087 0.000 0.002 0.003
return_5d_lag1 0.0048 0.001 7.047 0.000 0.003 0.006
return_10d_lag1 -0.0009 0.001 -0.796 0.426 -0.003 0.001
return_21d_lag1 0.0029 0.000 7.577 0.000 0.002 0.004
return_1d_lag2 0.0027 0.000 9.269 0.000 0.002 0.003
return_5d_lag2 0.0008 0.001 1.054 0.292 -0.001 0.002
return_10d_lag2 0.0001 0.001 0.138 0.890 -0.002 0.002
return_21d_lag2 0.0003 0.000 0.965 0.334 -0.000 0.001
return_1d_lag3 0.0027 0.000 9.067 0.000 0.002 0.003
return_5d_lag3 0.0014 0.001 1.821 0.069 -0.000 0.003
return_10d_lag3 0.0005 0.000 3.460 0.001 0.000 0.001
return_21d_lag3 -0.0002 5.55e-05 -3.795 0.000 -0.000 -0.000
return_1d_lag4 0.0030 0.000 10.072 0.000 0.002 0.004
return_5d_lag4 0.0006 0.001 1.021 0.307 -0.001 0.002
return_10d_lag4 0.0004 0.000 3.831 0.000 0.000 0.001
return_21d_lag4 3.547e-05 5.5e-05 0.645 0.519 -7.23e-05 0.000
return_1d_lag5 -8.947e-05 6.19e-05 -1.445 0.148 -0.000 3.19e-05
return_5d_lag5 0.0001 0.001 0.200 0.842 -0.001 0.001
return_10d_lag5 0.0007 9.95e-05 7.223 0.000 0.001 0.001
return_21d_lag5 9.29e-05 5.48e-05 1.695 0.090 -1.45e-05 0.000
year_2014 -0.0004 8.37e-05 -4.589 0.000 -0.001 -0.000
year_2015 -0.0006 9.15e-05 -6.906 0.000 -0.001 -0.000
year_2016 -0.0005 8.95e-05 -5.167 0.000 -0.001 -0.000
year_2017 -0.0002 8.8e-05 -2.485 0.013 -0.000 -4.62e-05
month_2 0.0010 7.17e-05 13.632 0.000 0.001 0.001
month_3 0.0003 7.43e-05 4.311 0.000 0.000 0.000
month_4 0.0005 7.35e-05 6.813 0.000 0.000 0.001
month_5 0.0005 7.25e-05 6.555 0.000 0.000 0.001
month_6 0.0004 7.34e-05 5.552 0.000 0.000 0.001
month_7 0.0006 7.62e-05 8.234 0.000 0.000 0.001
month_8 6.735e-05 7.7e-05 0.875 0.382 -8.35e-05 0.000
month_9 0.0004 7.59e-05 5.129 0.000 0.000 0.001
month_10 0.0007 7.8e-05 8.422 0.000 0.001 0.001
month_11 0.0006 7.59e-05 7.431 0.000 0.000 0.001
month_12 0.0004 7.41e-05 4.884 0.000 0.000 0.001
capital_goods 0.0010 0.000 2.714 0.007 0.000 0.002
consumer_non-durables 0.0007 0.000 1.793 0.073 -6.34e-05 0.001
consumer_services 0.0008 0.000 2.234 0.026 9.29e-05 0.001
energy 0.0003 0.000 0.913 0.361 -0.000 0.001
finance 0.0009 0.000 2.533 0.011 0.000 0.002
health_care 0.0007 0.000 2.065 0.039 3.51e-05 0.001
miscellaneous 0.0011 0.000 2.564 0.010 0.000 0.002
public_utilities 0.0003 0.000 0.749 0.454 -0.001 0.001
technology 0.0011 0.000 3.284 0.001 0.000 0.002
transportation 0.0010 0.000 2.426 0.015 0.000 0.002
==============================================================================
Omnibus: 29135.691 Durbin-Watson: 2.010
Prob(Omnibus): 0.000 Jarque-Bera (JB): 2803353.255
Skew: -0.103 Prob(JB): 0.00
Kurtosis: 27.767 Cond. No. 80.6
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
'''残差の取得
preds = trained_model.predict(add_constant(X))
residuals = y[target] - predsfig, axes = plt.subplots(ncols=2, figsize=(14,4))
sns.distplot(residuals, fit=norm, ax=axes[0], axlabel='Residuals', label='Residuals')
axes[0].set_title('Residual Distribution')
axes[0].legend()
plot_acf(residuals, lags=10, zero=False, ax=axes[1], title='Residual Autocorrelation')
axes[1].set_xlabel('Lags')
sns.despine()
fig.tight_layout();
まとめ
この記事では、目的変数に対してどういった特徴量が相関が強いのかを見ました。線形モデルですので、残差の分布に着目することは非常に重要です。
この記事が気に入ったらサポートをしてみませんか?