大規模言語モデルで「自習」のループを回して自己改善しながら、分子物性を予測するシステムを作る

はじめに
大規模言語モデルに化学的な知見を教える研究を進めています。
これまでは、GPT-4に「なぜそのような実験結果になるのか? (理由)」を考察させ、既存のデータベースから、実験事実(分子構造ー理由ー物性)をテキストの形で学習させるアプローチをとってきました。
わりとコンセプト実証ができてきましたが、GPT-4はAPIコストがかかったり、一日あたりの呼び出し回数に制限があったり、closedだったり、秘密計算できない難点があります。
そこで、ローカルLLMそのものに、実験事実から化学的知見を「自習」をさせられないかを検討してきました。
(前回までの試行)
今回は、「自習」がループとして回り始める兆しが出てきたので、その結果を紹介します。
アイデア
ものすごく簡素化したスキーム

はじめに、先生(GPT-4)が基本となる考え方を教え、あとは生徒(ローカル大規模言語モデル:LLM)が自習を繰り返して、賢くなっていくイメージです。
実際のスキーム
実際のスキームは、いくらか複雑になります。

融点データベースを準備し、適当な化合物を選ぶ(左上)
今回は適当に10件選びました
GPT-4に、分子構造と物性をつなぐ理由を考えさせる(右上)
質問(Q)、理由(R)、回答(A)をローカルLLMにLoRA学習させる(真ん中)
追加の化合物をデータベースからランダムに選ぶ(左下)
ローカルLLMを使い、分子構造(Q)から、理由(R)と回答(A)を予測させる(右下)※
予測誤差が一定値(今回は30)以下のデータを残す
この作業を一定回数繰り返す(今回は100回)
3に戻る (GPT-4が生成した例題と、ローカルLLM自身が生成した回答を学習させる)
※込み入った補足
GPT-4とローカルLLMで若干タスクが異なります。
GPT-4はQ-AからRを生成させる
1. Q-AからRを生成するタスクを投げる
2. 得られたQ-Rから予測されるAが、実測値とほぼ一致するなら、学習データとして採用する
一方、ローカルLLMはQからR,Aを同時に生成します。
ある意味では、GPT-4よりも難しい予測をさせています。
その理由は、ローカルLLM(数ー数十Bクラス)はあまり賢くないので、逆に、1,2を整合性よく行うのが難しい手応えだったからです。
このシステムでは、ローカルLLMがQから生成したRが、化学的に妥当かどうかについては検証していない点にも注意が必要です。あくまで、答えがあっているかのみを機会的にチェックしています。
実装など
LLMとして、高速でループを回すために必要な最低限の性能(?)を持つLlama2-7bを使いました。
コードはこちら。
データセット: 融点データ3000件 (前回までのデータセットと異なります)
試験データ: ランダムに選んだ50件
評価に時間がかかるので、少なめに設定
訓練データ(母体): 残りの2950件
うち10件(模範解答)は、GPT-4が作成したQ-R-A
知識を与えるというよりは、回答様式(template)を学ばせる目的で学習させます
これがないと、「自習用テキスト」の生成効率が著しく悪くなります
2950からランダムにQを選び、モデルでR,Aを生成(自習用テキスト)
1 generationあたり、100回の生成試行
模範解答+自習用テキストから最大50件をランダムに選び、性能評価
結果
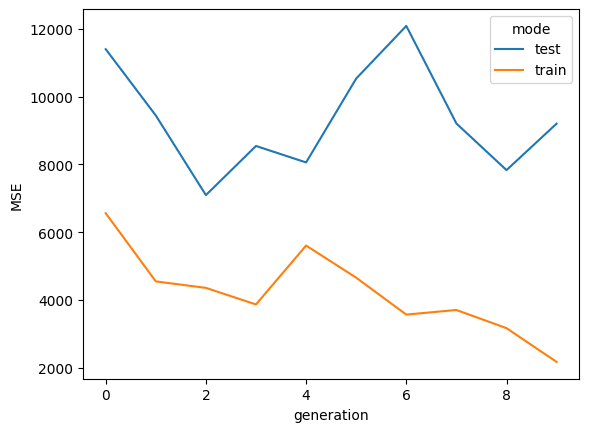
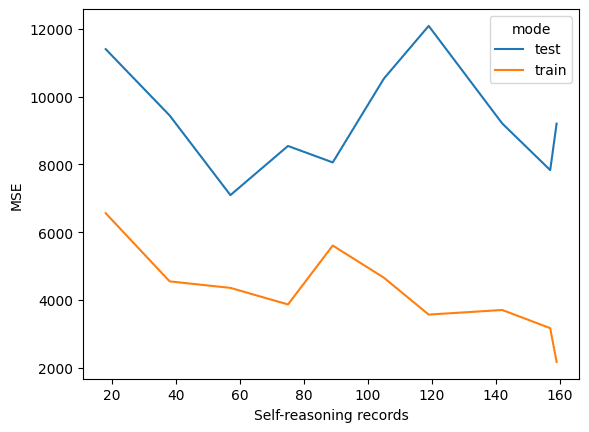
MSEの変化
計算を一晩ほど、回しました。
自習ループを回す(generationが増える)につれ、少しずつMSEが下がる兆候(?)が観測されました。
少なくともtrainについては、単調減少しています。
予測値の可視化
testデータについては、まだMSEがfluctuatingしていますが、少なくとも初期世代(generation =0)よりは、改善しているようです。
(後述するように、計算時間の都合上、まだgeneration/自習用データの数が全く足りていません)
初期世代のtest data

第八世代のtest data

予測の例
LLMに勝手に自習させているだけですが、実験結果をもとに、それっぽい理由(?)は生成してくれている印象です(詳細未は確認)。
第八世代の回答の例
{
"name": "7-methylquinoline",
"smiles": "Cc1cc2ncccc2cc1",
"Reason": "The base compound quinoline has a melting point of -6 degrees Celsius. Methylation of the quinoline base can increase the melting point due to the increased molecular weight and increased intermolecular interactions such as London dispersion forces. A rough estimate for the effect of a single methyl group might be around +20 degrees.",
"mpC": 39.0,
"Prediction(integer)": 26.0,
}( 理由 "塩基化合物キノリンの融点は-6℃である。キノリン塩基をメチル化すると、分子量が増加し、ロンドン分散力などの分子間相互作用が増加するため、融点が上昇する可能性がある。メチル基1個の効果を大まかに見積もると、+20度程度になるかもしれない」)
比較: 今までのベスト
GPT-4を使って生成した「模範解答」を2.5k件ほど学習させたllama2-7bの性能は以下の通り(random seed等の都合上、学習、試験データセットの中身が異なるので注意)。

混合エキスパートモデル(Mixtral-8x7B)の結果は以下の通り。
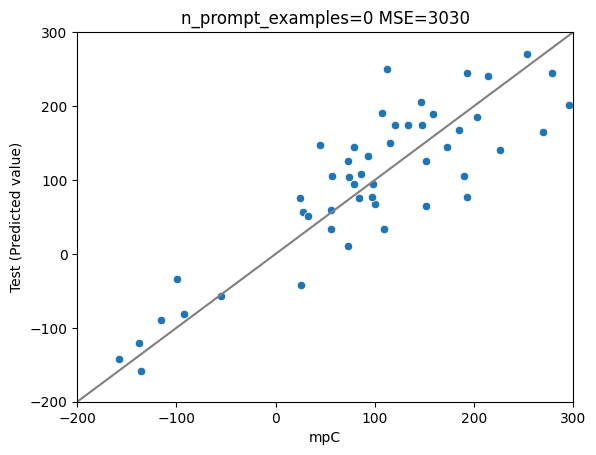
当然ながら(?)、今回のシステムの予測精度はまだ今までのベストに及んでいません。
計算時間の都合上、自己学習データはまだ160件ほどしか取れてないのが、最大の理由として考えられそうです。
(加えて、自動生成したテキストの質についても、今後評価していく必要があります)
まとめ
LLMが数値のみのデータベースから、諸々の知見を自己学習してくれそうな手応えが出てきました。そろそろ研究としてもまとまりそうです。
引き続き計算を回したり、条件を最適化して行きたいと思います。