
【Python初心者 スクレイピング基礎】映画一覧から「タイトル」「監督名」「価格」を抽出する

こんにちは(@t_kun_kamakiri)
本記事では、スクレイピングの基礎について、コーディングをながら解説をします。
今回、対象とするのは以下のサイトです。
こちらのサイトは以下のように映画一覧があり、色々な情報が載せられています。

今回は、こちらのサイトから以下の情報を取得してデータとしてまとめたいと思います。
【取得するもの】
●タイトル
●監督名
●価格

では、まずスクレイピングの基本からおさらいをしていきます。
スクレイピングの基礎
Pythonでは、BeautifulSoupというHTMLなどを解析するライブラりがあり、データ取得などを行う機能が備わっています。
まずは、以下のように「BeautifulSoup()」の中にHMTLを書いて出力を見てみましょう。
from bs4 import BeautifulSoup
soup1 = BeautifulSoup('<h1>Example Domain</h1>')
soup1
このようにして、簡単にHTMLの要素が抽出できました。
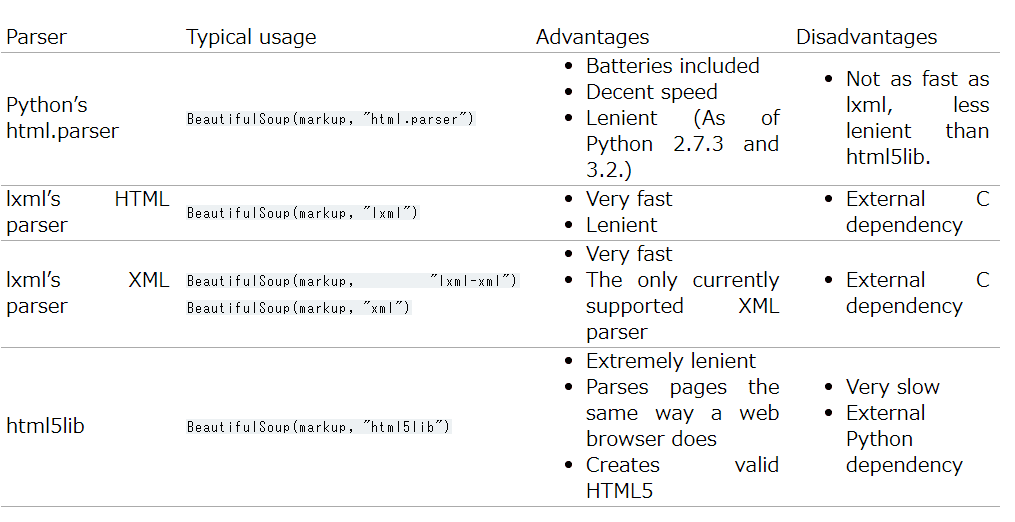
さらに、HTMLを解析しやすいように以下のような改正方式があります。
●html.parser:Python標準のHTML解析方式
●lxml:XML方式
●html5lib:
from bs4 import BeautifulSoup
soup2 = BeautifulSoup('<h1>Example Domain</h1>', 'html.parser')
soup2
BeautifulSoupの第一引数に解析したい情報を、第二引数に解析の方式を書きます。
BeautifulSoupで使う関数名
BeautifulSoupを使ってHTMLの要素を抽出する方法は以下があります。
●find():最初の要素を取り出す
●find_all('タグ'):タグ指定したすべての要素をとリストで取り出す
●get('属性'):指定した属性の要素を取り出す
●get_text():タグを除いたテキストを取り出す。
スクレイピングで注意する点
●Webサイトへの負荷
●著作権
頻繁にアクセスをしてサーバーに負荷をかけたり、思いもよらず著作権を侵害してしまう可能性があるので注意です。
サーバー側にリクエストを送るのは、Requestsモジュールを使います。
import requests
url = 'https://www.imdb.com/search/keyword/?keywords=public-domain&ref_=kw_ref_typ&sort=moviemeter,asc&mode=detail&page=1&title_type=movie'
response = requests.get(url)
response.status_code「response.status_code」で200と返ってくれば正常にレスポンスが返ってきていることになります。
print(response.text)
これで、
url = 'https://www.imdb.com/search/keyword/?keywords=public-domain&ref_=kw_ref_typ&sort=moviemeter,asc&mode=detail&page=1&title_type=movie'
内のHTMLをすべて取り出すことができました。
これを以下のように、BeautifulSoupでhtml.parserに変換しておきます。
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
soup
あとは、要素を取り出すだけです。
取得したいものを整理
もう一度取り出したい要素を整理しておきます。
【取得するもの】
●タイトル
●監督名
●価格
いきなりすべての映画一覧の要素を取り出すのはコーディングとして難しいので、まずはひとつの映画に対して「タイトル」「監督名」「価格」を抽出します。
タイトルを抽出
まずは、先ほど生成した「movie」オブジェクトから要素を取り出します。
このとき、以下のように第二引数で「 {'class': 'lister-item-header'}」の徐庶型を指定すると、それに応じたクラスセレクタの要素のみを抽出します。
title = movie.find('h3' , {'class': 'lister-item-header'})
title
この中の「aタグ」のみを抽出するので、以下のようにします。
title = movie.find('h3' , {'class': 'lister-item-header'}).find('a')
title.text
titleという変数に格納しています。
これで映画のタイトルが抽出できました。
監督名の抽出
続いて、監督名も抽出します。
movie.find_all('p', {'class': 'text-muted text-small'})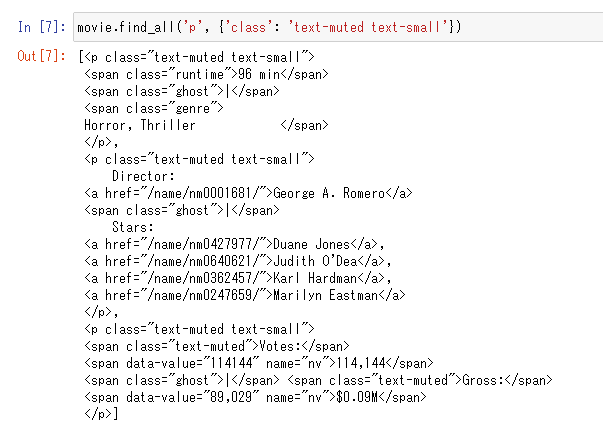
find_all()を使っているので、第一引数のpタグ、第二引数のクラスセレクタを持つ複数の要素がすべて取り出されています。

要素の大きさが「3」となっています。
この要素が3のうち監督名はインデックス「1」の要素なので以下のようにして要素を取り出します。
movie.find_all('p', {'class': 'text-muted text-small'})[1]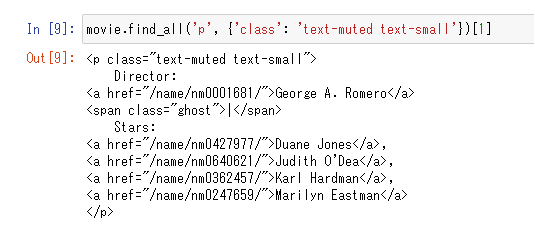
監督名は、ひとつ目のaタグのテキスト要素なので、以下のようにして抽出します。
name = movie.find_all('p', {'class': 'text-muted text-small'})[1].find('a').text
name
nameという変数に格納しています。
これで監督名が取り出せました。
価格の抽出
続いて価格の抽出を行います。
監督名を抽出したときのpタグのインデクス「2」の要素に価格がありますので、以下のようにします。
movie.find_all('p', {'class': 'text-muted text-small'})[2].find_all('span', {'name': 'nv'})
価格は2つ目のspanタグなので以下のようにします。
movie.find_all('p', {'class': 'text-muted text-small'})[2].find_all('span', {'name': 'nv'})[1]['data-value']価格は正確には、「data-value」属性の値なので、[data-value]として値を抽出します。
最後に、これをgrossという変数に格納します。
gross = movie.find_all('p', {'class': 'text-muted text-small'})[2].find_all('span', {'name': 'nv'})[1]['data-value']
gross
まとめて実行する
最後にまとめて実行するプログラムに変えます。
全コードは以下となります。
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
soup
url = 'https://www.imdb.com/search/keyword/?keywords=public-domain&ref_=kw_ref_typ&sort=moviemeter,asc&mode=detail&page=1&title_type=movie'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
movie_all = soup.find_all('div', {'class' : 'lister-item mode-detail'})
records = []
def movie_scraping(movie):
#タイトルの取得
title = movie.find('h3' , {'class': 'lister-item-header'}).find('a').text
#監督名の取得
name = movie.find_all('p', {'class': 'text-muted text-small'})[1].find('a').text
try:
#総収益を取得
gross = movie.find_all('p', {'class': 'text-muted text-small'})[2].find_all('span', {'name': 'nv'})[1]['data-value']
except:
gross = ''
dic = {
'title':title,
'name':name,
'gross': gross
}
records.append(dic)
return records
for movie in movie_all:
records = movie_scraping(movie)
recordsmovie_allでdivタグのすべて(映画のすべて)の要素を取り出しているのですが、以下のようにfor文にしてmovieにひとつひとつのdivの要素を取り出して、それを関数movie_scraping(movie)に渡しています。
for movie in movie_all:
records = movie_scraping(movie)
結果は、以下のように辞書型を要素に持つリストが作成されます。

これで映画の「タイトル」「監督名」「価格」の要素がすべて抽出できました。
データフレームにする
辞書型を要素に持つリストを作成したのは、pandasを使ってデータフレームにすることができるからです。
import pandas as pd
df = pd.DataFrame(records)
df
これでエクセルのような表が簡単に作成できました。
csvファイルの保存
できた、データフレームをcsvファイルにしてみましょう。
df.to_csv('data_scraping.csv')これでcsvファイルができました。

テキストで開くとcsvファイルはカンマ区切りでデータが作成されています。
dataの読み込み
ちなみに作成したcsvファイルを読み込むのは簡単です。
data = pd.read_csv('data_scraping.csv')
dataこれで先ほどと同じデータフレームができます。

まとめ
以上のように、
●Requests
●BeatifulSoup
を使うと簡単にHTMLから要素を取り出すことができます。
これを基本として、スクレイピングの技術をもう少し磨いていきたいですね。
本記事の内容は以下の書籍を参考にしています。
Twitter➡@t_kun_kamakiri
ブログ➡宇宙に入ったカマキリ(物理ブログ)
ココナラ➡物理の質問サポートサービス