
GPTなどの大規模言語モデルは脳科学・記号論・言語学の観点で驚くほど良くできている

大規模言語モデルの優秀さの秘訣
ChatGPTなどに代表されるサービスで採用されている大規模言語モデル(LLM)によって、AIは今までとは比べ物にならないくらい自然な対話ができるようになった。
なぜLLMでは自然な対話ができるかというとその秘訣の1つは、LLMは大量のテキストを学習する際に、文章内の単語を「ベクトル(向きと長さを持つ数学的な量)」に変換して処理しているからだ。
GPTでは各単語は数万という次元でベクトル化されており、単語ベクトルは意味が近いほどベクトル同士の距離が近くなる。

これこそが大規模言語モデルがここまで高い言語能力を獲得したポイントであるが、たまたま最近読んだ脳科学、言語学、文字学の本の中で、このLLMにおけるベクトル化の仕組みは非常に理にかなっていることが分かった。
一言でいうと、人間が意味や概念を扱う処理とかなり近い処理が、この単語のベクトル化なのだ。
注)以下の3冊で提唱されるのはいずれも科学的に検証された事実ではなく、『仮説』だ。しかし、仮説の中でも非常に説得力のある仮説であり、大規模言語モデルと人間の思考の共通点を指し示す非常に示唆深いものであるため紹介する。
脳は知識の保存と思考を「座標系」で行っている
ジェフ・ホーキンスの「脳は世界をどう見ているのか」において、「すべての知識は脳内で座標系として保存される。そして、脳が何かを思考するときは、新皮質全体が座標系をつくり、数千のニューロンが同時に活性化し、ある種の『投票』が行われることによって1つの知覚が形成される」という驚きの新説が提唱される。
例えばコップを認識する際には、コップの形状や自分との相対位置を座標系で認識している。
しかも、その座標系は物体だけではなく、愛や正義といった概念についても座標系で捉える。

本書では、その理論を裏付けする様々な研究も紹介されるのだが、上記はまさに大規模言語モデルがベクトルという座標系で知識をストックし、確率的論的に答えを生成するというプロセスとまさに合致する。
冒頭に説明したように、これは100%立証された科学的事実ではない。しかし、本書の序文が「利己的な遺伝子」著者のリチャード・ドーキンスであったり、様々な科学者が本書を支持していることからも、一定の信憑性はあると思っている。
異なる言語の文字同士も構成要素の頻度は同じであり、自然のなかの形状の出現頻度とも同じ
東浩紀氏と石田英敬氏による「新・記号論 - 脳とメディアが出会うとき」で紹介されていたマーク・チャンギージーの研究も大規模言語モデルと人間の共通項を考える上で非常に示唆深い。
チャンギージーによると、なんと「ヒトはみな同じ文字を書いている」。
まずチャンギージーらは下図のように、物体を構成する基礎的な要素(T字/L字/*字など)を整理し、様々な文字システムのなかで、そうした要素が出現する頻度を分析した。
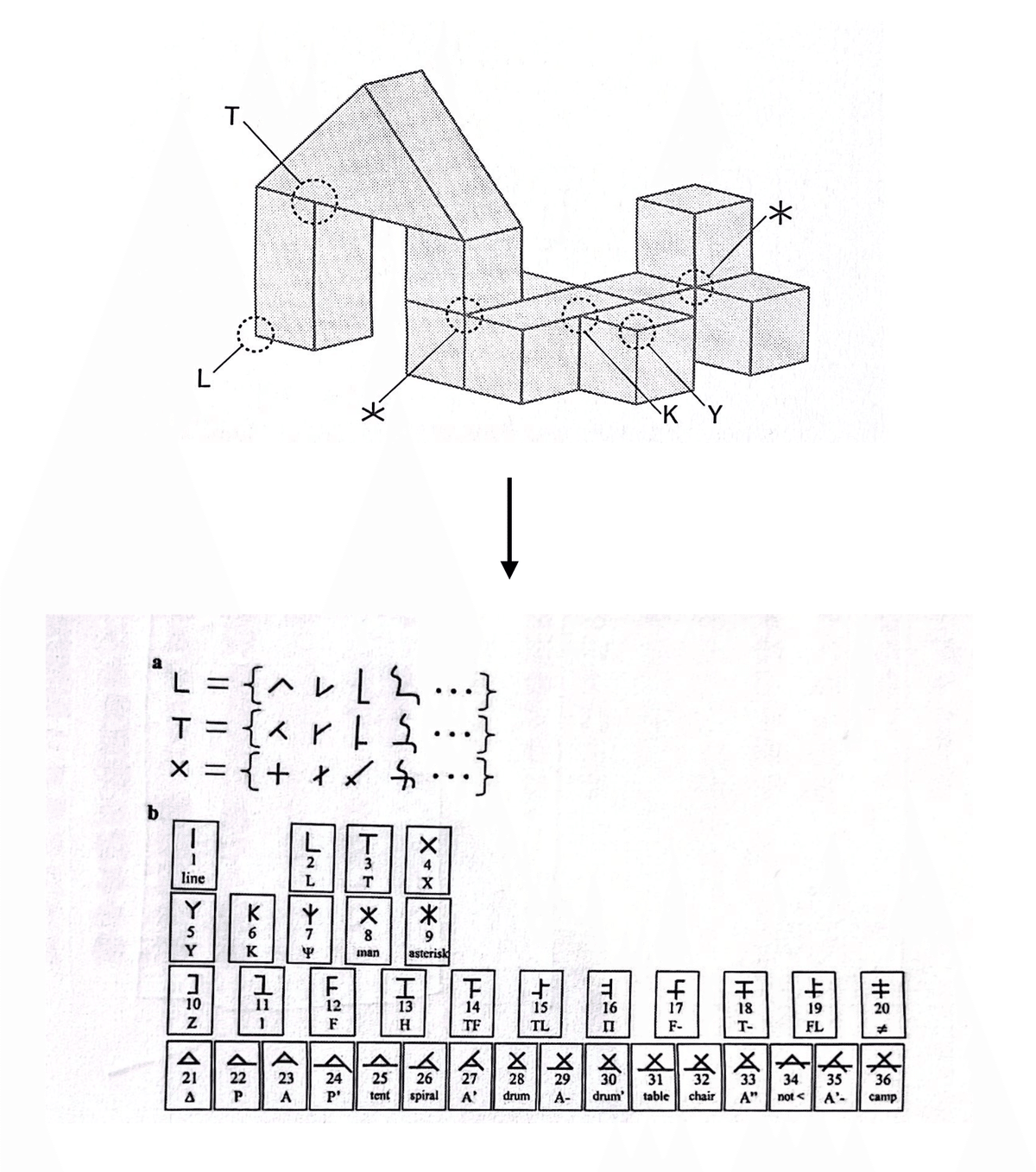
すると、驚くべきことに、①漢字などの表語文字、②カナやアルファベットなどの非表語文字、③矢印やピクトグラムなどの記号群、という一見まったく異なる見た目をしている文字システムたちが基礎的なカタチの出現頻度の分布が一致したのだ。

さらに驚きの研究結果はまだ続く。
チャンギージーらは、私たち人間が見ている光景に対しても同様に基礎的なカタチの要素の出現頻度を分析した。
彼らは①人類の祖先たちが見ていた自然界の光景に近い部族写真、②「ナショナルジオグラフィック」誌のアウトドアシーンの写真、③CGで描画したフェン題都市空間の建物や街並みのデータ、それぞれを大量に用意し、それらにおける基礎的なカタチの要素の出現頻度を分析したのだ。
すると、これも驚くべきことに、3種類の画像の中に現れる基礎的なカタチの要素の分布は、先述の文字・記号のなかに出現するカタチの要素の分布ときれいに相関していることが分かった。

つまり、人間は自然のなかの事物を見分けているパターンと同じ頻度でカタチの要素を組み合わせ、文字をつくってきたのだ。
ここまでの研究内容をまとめると以下の2点だ。
人間がつくった文字は、構成要素の出現頻度で見るとみな同じ分布をしている
その出現頻度は自然界における構成要素の出現頻度と同じ分布になっており、人間は自然のなかのカタチの出現頻度をまねて文字をつくってきたと考えられる。
この研究は大規模言語モデルの仕組みや、AIの諸研究と直接結びつくものではない。しかし、個人的にはチャンギージーらの研究によって示された事実と大規模言語モデルの仕組みの共通項に思いを馳せずにはいられない。
GPTなどの大規模言語モデルは様々な言語のデータを一度ベクトルという形で、AIだけに分かる共通言語に全て翻訳して、言語の壁が完全になくなったAI語のデータとして保存している。
レイヤーもスケールも異なるが、自然界をある種のベクトル的に認識し文字をつくり、それによって繁栄してきた人間という種が、対象をベクトル的に認識することで圧倒的な知能を獲得したAIを生み出した、というのはなんとも壮大なドラマではないだろうか。

言語学的なLLMと人間の共通点と相違点
今井むつみ氏と秋田喜美氏の「言語の本質」では、我々の言葉がどう生まれ、進化してきたかという疑問に関して、「オノマトペ」や「アブダクション(推論)」を中心的な鍵としながら興味深い仮説が提示されている。
本書の仮説を端的にまとめると以下のようになる。
まず我々の祖先はオノマトペ(ニコニコやギクッといった言葉)を使用するようになり、それらが文法化され、体系化されて、現在の記号の体系としての言語にしていった。
そして、その過程ではアブダクション(推論)によって、知識や概念を拡張することによって、現在の複雑な記号体系をつくり上げることができた。

赤ん坊が言語を覚えていく過程も基本的には上記のプロセスを辿る。
そして、それはとても統計的な作業だ。
赤ん坊は、自分の母語において、単語の最初に来る確率が高い音(ex.わたし)、低い音(ex. です。)、単語の最後に来やすい音(ex. です。)、来にくい音(ex. わたし)などを分析し、それを扱えるようになる。
この確率的な文法の学習と文章生成は、なんと大規模言語モデル的だろうか。
ただし、GPTなどの大規模言語モデルと我々人間とで決定的に異なる点がある。それが「記号接地しているかどうか」だ。
我々は「身体的感覚」と「オノマトペ」を通して、「最初の知識」を形成し、それを上の図のようなブートストラッピング・サイクルによるアブダクション(推論)を通して言語を学習していく。
しかし、GPTなどの大規模言語モデルには、その「身体性を伴う最初の知識」というものが存在しない。
つまり、大規模言語モデルがどんなに知性的に言葉を話そうと、そのAIはその話している内容を実は全く理解できていないのだ。
AI開発における記号接地の欠如の問題が指摘されてから久しいが、人間の言語の形成や学習過程から考えると、やはり非常に優秀な大規模言語モデルにおいても記号接地できていないというのは大きな欠陥であることがわかる。
まとめ
この駄文が誰のためになるかは分からないが、たまたま最近読んだ3冊が「大規模言語モデル」というテーマで自分の頭のなかで結びついたので、その考えを整理するためにもこのnoteを書き綴った。
自分は大規模言語モデルそのものを開発する研究者ではないので、これを実務に活かしたりする予定もスキルもないが、これだけAIの知性が人間に並び追い越しつつあるいま、AIの本質や、人間の本質を1人1人が考えることは何かしらの価値があるだろう。
これからもその問いへの考えを深めるための読書と探究を続けていきたい。
いいなと思ったら応援しよう!
