
1. 概念情報モデル

本ドキュメントの利用は、https://github.com/kae-made/kae-made/blob/main/contents-license.md に記載のライセンスに従ってご利用ください。
Date:2023/11/26 - Version 1.1.0
概念情報モデル
概念モデルは、図やテキストで記述します。概念モデルを作成した人達の意図が第三者でも誤解なく理解できるように、モデルを構成する基本要素、および、図やテキストの記述方法にはある程度の厳密さで定義された決まりが必要です。
図による記述は、概念情報モデルの直感的な理解の促進や、対象領域全体を俯瞰する際に役立ちます。テキストによる記述は、詳細で厳密な記述を可能にし、IT技術活用による情報のデジタル化に寄与します。
本編では、図の表記は UML(Unified Modeling Language) を、テキストによる記述は YAML(YAML Ain‘t Markup Language) をベースにした記法を用いることにします。
以下、概念モデルの構成要素と記述方法を、概念モデリングの手順を交えながら解説していきます。
概念情報モデルの構成要素
概念情報モデルを構成する要素には、大きく分けて以下の三種類があります。
モデル化対象の“主題領域”(Domain)
概念インスタンスを分類して抽出した“概念クラス”(Class)
概念クラス間の“関係”(Relationship)
ドメイン(主題領域)
概念情報モデル作成の開始にあたり、まず、モデル化する主題を特定し、名前と概要説明を作成します。主題領域は、概念モデルを作成していく過程で理解が深まっていくものなので、作成開始時点では漠然としたもので構いません。名前は、例えば、“商品販売”とか“装置管理”などといったシンプルなものを選びます。 概要説明はモデルを作成するチームの各メンバーが、モデルを作成しようとしている主題について、漠然と頭に浮かんでいる場面や情報の流れ、処理手順、等々を絵(ラフなスケッチで構いません)に描いて相互に説明しあうなどしてメンバーの合意のもとに、モデル化対象を説明する簡潔な文章を作成します。YAML 形式では以下の様な記述で定義します。
domain:
name: 主題領域名
description: 説明文
sketch: ラフスケッチの数々繰り返しになりますが、概念情報モデルの開始時点では、チームメンバーが何をモデル化すればいいのかについて同じスタートラインに立つためのベースをつくることが目的なので、厳密な名前や説明文は必要ありません。モデリング作業が進むにつれて明らかになる様々な事項は、YAML の定義に追記していきます。作業中に描いたラフスケッチの数々も保存しておいて、上の YAML の定義で保存場所の URL を記録しておいて、モデリングの最中に参照できるようにしておくことをお勧めします。
概念モデリングにおいては、実は、主題領域の定義が一番難しい。概念モデリングの初心者が最初から適切な主題領域を定義するのはまず無理なので、適切な主題領域の定義ができているかを、先達に確認してもらうことをお勧めする。
概念モデリング中に明らかになる様々な事項の中で、「その主題領域で何を扱うか」がもちろん重要ではあるが、「その主題領域で扱わないものは何か」という情報も非常に重要であり記録しておくことをお勧めする。
初稿の時点では、”ドメイン”を指して、”問題領域”という用語を使っていた。伝統的な訳なのでそれでもいいかと思ったが、「問題は、理想とする状態と現状とのギャップである」という定義も厳然としてあるということと、モデリングの対象は、理想の状態、現状の状態の両方が対象となりうるので、”問題”という用語はそぐわないと判断。よって、”問題領域”は、”主題領域”と改め、”問題”についても、文脈に応じて”主題”と書き換えた。
概念クラス
モデル化対象の主題領域名が決まったら、主題領域を構成する概念群を抽出し、“概念クラス”を定義していきます。概念モデリングでは、モデル化対象の実世界に実際に存在する(物理的な存在だけでなく概念的な存在も含む)モノ群事態に着目した後、それらを分類して概念クラスを定義します。主題領域の定義で描いたスケッチ等をもとに一つ一つ区別できたり数え上げられたりするものをピックアップします。例えば、“商品販売”という主題領域では“商品”や“注文”などが該当します。これらは“概念インスタンス”の候補になります。抽出した概念インスタンス候補について、それぞれを特徴づける値をリストアップします。
値には、それぞれの概念インスタンスを区別するのに必要な “識別子的な値”と、それぞれの“特徴を表す値”の2種類があります。例えば、“商品”には、“商品コード”や“商品名”など、それぞれの商品を区別する値(二つ以上の特徴値が組み合わされる場合もあり)、 “値段”や、“色”、“形”、“購入者評価”、”温度”、”加速度”、”位置”、…、などといった商品の特徴を表す値群です。
リストアップした値それぞれに対して意味を考えて、適切な名前を付けてそれぞれの特徴値を定義します。
次に、抽出した概念インスタンス候補群を、モデル化対象の主題領域において、同じ意味を持ち、かつ、同じ特徴値のセットを持つものに分類し、その分類ごとに、モデル化対象の主題領域において適当と思われる名前を決め、”概念クラス”の候補とします。”概念クラス”の名前は、ほかの分類につけた名前とは異なるように決定します。
概念クラスは、下図に示すルールで表記します。

YAML による表記
domain: 主題領域名
class:
クラス名:
description: 説明文
property:
特徴値名:
datatype: データ型名
description: 説明文
・・・参考までに、“商品販売”という主題領域における“商品”と、“装置管理”という主題領域の“装置”を、各主題領域で抽出したクラスの例として挙げておきます。

“商品販売”における“商品”
domain: 商品販売
class: 商品:
description: 販売対象
property:
商品コード:
datatype: 商品コード
description: 商品を一位に区別するための識別子情報
商品名:
datatype: 文字列
description: 商品の通称
在庫数:
datatype: 正の整数
description: 注文可能な在庫数
単価:
datatype: 金額
description: 販売時の一個あたりの値段“装置管理”における“装置”
domain: 装置管理
class: 装置:
description: 管理対象の装置
property:
装置ID:
datatype: 装置ID
description: 装置を一位に区別するための識別子情報
温度:
datetype: 温度
description: 装置の槽内温度
設置日:
datatype: 日付
description: 装置をプラントに設置した日付
状態:
datatype: 装置の状態
description: 現時点での装置の状態
稼働時間:
datatype: 時間
description: 設置から現時点までの稼働総時間※ 例示したクラスの特徴値は、あくまでも例であり、筆者が適当に思いついたものを羅列しています。特徴値は、モデル化対象によって様々です。
※ 特徴値やデータ型については、後ほど、詳細に解説します。
モデル化対象の主題領域が複数ある場合は、それぞれに同じ名前の概念クラスがあっても問題ありませんが、名前は同じでも、それぞれの主題領域ごとにその概念クラスが表す意味は全く異なります。

※ 上の例は、クラスに対する名前付けがいかに重要かに対する悪しき例という意味合いも含めて挙げています。どちらのクラス名も“オーダー”としていますが、あまりいい名前とは言えません。左のクラスは“注文”、右のクラスでは“命令”とか、あるいは、適切な名前が浮かばない場合は“装置に対する指示”といったような冗長な名前をつけておいて、後で名前を見直すのでも構いません。
以上、概念クラスの描き方、定義方法を解説しました。 モデル化対象の主題領域から、概念インスタンスをリストアップし、全ての概念インスタンスに対して、
概念インスタンスに対応する概念クラスがあるか?
ある場合、対応する概念クラスの特徴値が全て意味を持ち、具体的な値を持つか?
の二点を確認します。一番目の、対応する概念クラスが無い場合は、その概念インスタンスの意味を吟味し、新たな概念クラスの候補(名前と特徴値のセット)を抽出します。二番目の場合は、特徴値が適切か見直す、または、本来複数の概念クラスとして抽出するべき分類が一つの分類にごっちゃになって抽出されている可能性があるので、特徴値が意味を持つ概念インスタンス群、持たない概念インスタンス群に分けて適切と思われる概念クラスの再抽出、整理を行います。抽出した概念クラスの妥当性の検証は、次に説明する関係の抽出・定義作業の間も含めて、概念情報モデルの完成まで続きます。
概念情報モデルは、その都度様々に構成が変わる概念インスタンス群ではなく、それらを分類したもの=概念クラスを使って作業を進めます。この点は非常に重要なので、概念モデリングでは、今扱っているのは、概念インスタンスの話なのか、概念クラスの話なのかを常に意識することが必要です。オブジェクト指向プログラミングに精通した読者であれば、“概念クラス”と“概念インスタンス”の関わりは、オブジェクト指向言語の“クラス”と“インスタンス”の関わりと同じと説明すれば納得いただけると思います。ただし、概念モデリングにおける“概念クラス”は、オブジェクト指向の“クラス”ライブラリとは似て非なる別物と思って読み進めてくことをお勧めします。それを踏まえ、以下は敢えて、“概念クラス”、“概念インスタンス”という言葉は煩雑なので、単にそれぞれ、“クラス”、“インスタンス”という言葉を使う事にします。特段の説明がない限り、“クラス”は“概念クラス”、“インスタンス”は“概念インスタンス”のことを意味すると思ってください。また、これまで使ってきた“主題領域”も簡便のため、今後は、“ドメイン”と記すことにします。
関係(Relationship)
概念モデリングでは、モデル化対象のドメインは、抽出されたクラスの定義に従って存在するインスタンス群から構成されると考えます。各時点で存在するインスタンスは別のインスタンスと意味的なつながりを持ちます。
例えば、“販売管理”という主題領域(ドメイン)で、“注文”、“顧客”、“商品”というクラスがあるとして、ある“注文インスタンス”は、“誰が注文したか”という意味において、”顧客インスタンス“のどれかとつながっているでしょうし、”何を注文したか“という意味において、”商品インスタンス“のどれかとつながりを持っています。このような概念インスタンスの間のつながりを”リンク”と呼ぶことにします。
このような、異なるクラスを雛形にしたインスタンス間の“意味的なつながり”を、クラス間の“関係(Relationship)”として定義します。
“関係”は、ドメインが扱うシナリオやアイデアスケッチ等を元に、二つのクラスの間で定義します。
名前が“A”と“B”という二つのクラスがあるとします。“A”のインスタンスから見た“B”のインスタンスの“関係”は、- そのつながりの“意味”を表す簡潔なテキスト - つながっている“B”のインスタンスの個数
つながっているインスタンスの個数は、“多重度”と呼びます。 “A”から見た“B”の“意味”と“多重度“と、逆方向の“B”のインスタンスから見た“A”のインスタンスの“意味”と“多重度”を合わせたものが、“A”と“B”の間の“関係(Relationship)”の定義です。図で描くと下図のようになります。

YAML による表記
domain: 主題領域名
class:
・・・
relationship:
関係名:
description: 説明文
Aのクラス名:
meaning: シンプルな意味のテキスト
multiplicity: 0|0..1|*|1...* のどれか
Bのクラス名:
meaning: シンプルな意味のテキスト
multiplicity: 0|0..1|*|1...* のどれか
・・・クラスや特徴値に名前を付けたように、“関係”にも名前を付けておくと便利なので、それぞれの“関係”に対して、ドメインで重複しない名前を決めます。“関係”は、その両端のクラス、意味、多重度で、それがどんなつながりを意味するのか明確に定義されているので、単なる記号的な名前で構いません。テキスト表記の場のみ明記し、図表記の場合は必要なければ記載しなくても構いません。
多重度
二つのクラスの、片方のインスタンスにつながるもう一方のインスタンスの数は、モデル化対象によって千差万別ですが、これまでの経験から、以下の4種類のうちからどれか一つを選択して定義すればよいことが実用上問題ないことが判っています。
1. ”1” 片方のインスタンスがある場合、かならず、もう一方のインスタンスが1個だけ必ずある
2. ”0..1” 片方のインスタンスがある場合、もう一方のインスタンスはない場合もあるが、つながりがある場合は1個だけしかない
3. ”1..*” 片方のインスタンスがある場合、もう一方のインスタンスは1個以上ある
4. ”*” 片方のインスタンスがある場合、もう一方のインスタンスはない場合もあるが、つながりがある場合は複数ある

関係の多重度に、2 や 3 といった 1 より大きい特定の数の場合もあるのではないかと不思議に思う読者もいるかと思いますが、それは参考にしている状況が偶々そういう値になっていたり、システムの実装上の制約でそうなっているケースが大半です。そうでない場合は、概念モデリング的には、例えば3の場合、ドメインの文脈において、その3つそれぞれに別の意味が見つかることがほとんどです。概念情報モデルを使ったインスタンス構成の自由度を確保する意味でも、上にあげた4種類の多重度のみでモデル化しましょう。
参考までに、多重度の組合せの一覧を図に示しておきます。

関係は一つのクラスに対して定義することもできます。例えば、何かが順番に並んでいるような事柄をあらわしたいなら、以下のような関係の定義が可能です。

関係クラス
モデル化対象のドメインには、あるクラスのインスタンスが存在するために二つのクラスを雛形にしたインスタンスが必要なコトや役割があります。例えば、“商品販売”では、“注文”というクラスのインスタンスには、“顧客”クラスと“商品”クラスのインスタンスが必要そうだというのは直感的に間違っていなさそうです。“注文”クラスのようなクラスを、“関係クラス”と呼びます。表記法は以下の通りです。

YAML による表記
domain: 主題領域名
class:
・・・
relationship:
関係名:
description: 説明文
Aのクラス名:
meaning: シンプルな意味のテキスト
multiplicity: 0|0..1|*|1...* のどれか
Bのクラス名:
meaning: シンプルな意味のテキスト
multiplicity: 0|0..1|*|1...* のどれか
class:
関係クラス名:
description: 説明文
property:
特徴値名:
datatype: データ型名
description: 説明文
・・・例で挙げた、“顧客”、“商品”、”注文“のインスタンスのスケッチとクラスモデルを参考までに図示します。

関係クラスの場合も、両端の多重度は16種類です。念のため、全ての種類をリストアップしておきます。

16種類のうち、0..1、*のように関係する相手方のインスタンスがない場合の多重度を持っている場合、ある特徴値のセットを持つ新たな意味のクラスが抽出可能なことが多いので留意しましょう。
関係クラスを雛形にした概念インスタンスは、その関係クラスが点線で紐づいている関係(Relationship)を雛形にした概念インスタンスをつなぐリンクと1対1に対応します。モデル化対象の主題領域において、リンクに紐づく値がある場合や、そのリンクが単なる切り貼りではなく、振舞モデルの章で説明する様なダイナミクスを伴っている場合に定義します。
”is-a”
概念クラス、概念クラス間の二項関係、関係クラスまでは、リレーショナルデーターベースを設計する際に行う、リレーショナルセオリーに基づいた、ER図(Entity Relationship Diagram)で行うモデルとほぼ同じです。しかし、現実の世界は非常に複雑であり、複雑な主題を可視化するためにもう一つの武器を追加します。次の図に示すような関係の定義です。

”is-a”の関係(Relationship)は、上図の P、C1、C2 について、
C1 is a P
C2 is a P
という述語表現が可能です。
YAML による表記
domain: 主題領域名
class: クラス名:
is_a: [,で区切ったスーパークラスの名前のリスト]
description: 説明文
property:
特徴値名:
datatype: データ型名
description: 説明文
・・・オブジェクト指向プログラミングに精通していればしているほど混乱しそうなので、継承(Inheritance)や実装(realize)、多態(Polymorphism)といった概念は一旦忘れてくださいね。
図に示したモデルの、△の頂点が接している“P”クラスを“スーパークラス”、△の底辺から伸びた線が接している“C1”、“C2”クラスを“サブクラス”と便宜上呼ぶことにします。このような関係がある場合、以下のような意味を表します。
サブクラスのインスタンスが1つ存在する場合、必ず対応するスーパークラスのインスタンスが1つだけ存在する。
スーパークラスのインスタンスが1つ存在する場合、関係でつながっているサブクラスのうちどれか1つのクラスのインスタンスが1つ存在する
図に示したモデルの場合は、
C1クラスのインスタンスが1つ存在する場合、対応するPクラスのインスタンスが必ず1つだけ存在する。C2の場合も同様
Pクラスのインスタンスが1つ存在する場合、C1かC2どちらかのクラスの対応する1つのインスタンスが必ず存在している
という解釈になります。
若干数学風に言えば、“概念クラス”は“集合”で、“概念インスタンス”はその集合に属する“要素”です。この関係は、スーパークラスが“全体集合”、サブクラスが“部分集合”でかつ、その全体集合に属する要素は、必ず、どれかの部分集合の要素ですよ、という定義です。
図中の△と線の付近に“{complete, disjoint}”と書いてあるのが、この制約を明記するUML風の呪文です。
誤解のないように、ちょっとだけくどくて詳細な説明をしましたが、世の中、大体同じでちょっとだけ違うモノやコト、役割は山ほどあります。”is-a”の関係はその様なモノ、コト、役割を分類し明記するための道具です。
概念情報モデルにおいては、
「モデル化対象のドメインにおいて、完全に同じ意味を持ち、同じ特徴値のセットで特徴づけられ、かつ、他のインスタンスと同じ関係を持つ」
ことが、“概念インスタンスが同じ”であることの条件です。概念モデリング中に抽出した概念インスタンス群から概念クラスの候補を抽出し、関係を定義していく過程で、
一部の概念インスタンスはいくつかの特徴値を持たない、あるいは、別の特徴値を持つ
一部の概念インスタンスだけが、別の概念クラスのインスタンスと関係を持つ
ような場合に遭遇したら、”is-a”の関係を使って、概念クラスを新たに抽出していきます。主題領域によっては、あるクラスが複数のスーパークラスのサブクラスになることも当然あり得ます。

※ 木構造を持った概念インスタンスの構成は一般的によく見かけるパターンです。上の図のクラス名やParentクラスとChildクラスの両端の意味は、あくまでも説明のための一般化した言葉での例示であり、実際の概念モデリングにおいては、もっとモデル化対象のドメインで意味を持つ具体的な言葉を探さなければなりません。
※ 読者の中には、UML の表記において、包含関係にある関係は、包含する側の関係の端にひし形のアイコンを使うと機械的に覚えている方もいるかもしれません。しかし、ここで説明している流儀の概念モデリングでは、モデル化対象のドメインにおけるスペシフィックな意味を頭をひねって抽出する事が目的であり、曖昧な“包含”というような言葉でとどめるべきではないのと、そもそも包含関係も単なる関係の一つであり、あえて表記のための道具を増やす価値はないという二つの理由でひし形の表記は使いません。
概念情報モデルのクラスの特徴値と関係の抽出においては、この”is-a”の関係と、リレーショナルセオリーの正規化をベースにしています。これらは、モデル化対象のドメインに対して、クラスやその特徴値、関係の適切な抽出されているかを判断する手段の一つです。以上で、概念モデリングで扱う、全ての”関係“が出そろいました。 念のために加えておきますが、関係を定義できるのは、同じドメインのクラスの間だけです。
オブジェクト指向プログラミングに精通した読者の中には、「多重継承はよろしくない」と思われる方もいるかもしれない。オブジェクト指向プログラミングにおいて多重継承で問題になるのは、継承するスーパークラスで宣言された変数名やメソッド名が重複するような場合であり、それらが継承したサブクラスの名前空間から見えてしまうためである。そもそも、概念情報モデルにおける、”is-a”の関係は二つの概念クラス間で定義された特殊な二項関係であり、継承ではないので、問題はない。
”概念インスタンス”が”概念クラス”を雛形として定義されるのと同様に、”リンク”は”関係(Relationship)”を雛形に定義されることになります。ひとつの”リンク”が存在する時、その両端には必ず、それぞれ一つづつの”概念インスタンス”が、”関係(Relationship)”の両端に定義された”意味”で存在します。関係クラスが定義されている場合には、その二つの概念インスタンスに加えて、更に、その関係クラスの概念インスタンスが一つ存在することになります。
主題領域(ドメイン)のコンテキスト、シナリオは、モノ(概念インスタンスに相当)が存在するだけでは意味を成しません。モノとモノの間に存在するリンクがあって初めて、コトや役割を示すことができます。概念情報モデルは、一見すると、”概念クラス”が主役に見えますが、現実世界の理解には、むしろ、関係(Relationship)の方が重要なので、”概念クラス”の抽出と同様、”関係(Relationship)”の抽出も気合を入れて行わなければなりません。
特徴値
概念クラスの抽出で、特徴値には、“識別子的な値”と、それぞれの“特徴を表す値”の二種類があると説明しました。ここでは更に特徴値について更に詳しく解説することにします。特徴値は、その変数名と存在しているインスタンスごとにその時々の値を持ちます。変数がどんな値をとりうるのかの定を“データ型”と呼びます。 モデル化対象のドメインで扱う“データ型”を定義することも概念モデリングの重要な作業の一つです。概念モデリングの過程で、様々なデータ型の、“名前”、“値域”を明らかにし、“概要説明”を加えて定義していきます。データ型の“名前”は、クラスの名前と同様、ドメイン内で重複しないように名付けていきます。
データ型には、“単純型(Simple Type)”と“複合型(Complex Type)の二種類があります。
まずは、“単純型”です。“単純型”は、“数”、”文字列“、”列挙“の3種類のうちのどれかで定義します。
数
数は、1個、2個、3個、…、1番目、2番目、3番目、…といったように数えられるもの、いわゆる、自然数や負の数も含めた整数(integer)と、28.32℃、52.81km/hといった実数(real)の、二つに分類されます。数の単純型の定義では、“種別”(整数|実数)と“単位”、そして、最小値や最大値がある場合は、“値域”として明確に定義します。

文字列
文字列は、英数字や記号文字の連続した並びです。特徴値の値として使われる文字列において任意の並びの文字列もあつかうことも当然ありうるわけですが、概念モデリングにおいては、それぞれのクラスの特徴値の意味に基づいたある特定のパターンの並びを持つものが多いです。例えば、“顧客”の“名前”は、“姓” と “ ”(空白文字)と“名”(あくまでも日本人の名前を扱うドメインの場合だけですが)というパターンだったり、”商品“の”商品コード“であれば、その会社で決められた特定の英数字のパターンになっているはずです。 文字列の単純型の定義では、その文字列のパターンを、正規表現や、プロトコル構文規定言語のASN.1などを使ってパターンを明確に定義します。

列挙
例えば、装置の状態が、“電源OFF”、“初期化中”、“稼働中”、“テスト実行”、“故障中”の5つの中のどれかの値をとるといったような、それぞれの項目がドメイン内で明確な意味を持つ複数の項目のうちのどれか一つを値として持つようなデータ型を“列挙型”と呼びます。列挙は、それぞれの項目の名前と意味を定義したリストで定義します。

繰り返しになりますが、特徴値のデータ型は、“名前”、“概要説明”と、数の場合は、「“種別”、“単位”、“値域”」、文字列の場合はパターン、列挙の場合は、項目名と意味のリスト、により定義します。定義されたデータ型は、モデル化対象のドメインのあるクラスの特徴値と別の特徴値のデータ型がそのドメインにおいて同じ意味を持つならば再利用してかまいません。 しかし、同じように見えてもそのドメインにおいて意味的に異なるようなら、面倒くさがらずに別のデータ型として定義することをお勧めします。
真偽値型
論理演算に出てくる、“真(True)”か、“偽(False)”の値をとる型です。
複合型
次に複合型です。複合型は、複数の、単純型の変数、または、あらかじめ定義された複合型の変数からなるデータ型です。例えば、一般的な加速度センサーは3軸であり、一度に“距離/時間の二乗”を単位とする、x方向、y方向、z方向の3つの実数から構成されていたり、地球上の位置は、角度を単位とする、緯度、経度の二つの実数から構成されている、といったような変数は、単純型の変数に分割してしまった場合意味を失ってしまいます。この様な特徴値は組として扱うのが妥当です。複合型は、“名前”と“概要説明”、“構成する下位のデー型名のリスト“で定義します。

これは見ようによっては、リレーショナルセオリーの一次正規化のルールに反するように見えないこともないですが、加速度や角速度など同じセンサーである時点で複数の値を計測するようなものや、位置等はもともとひとまとまりにして意味がある値なので、一つの組の値として扱うほうが自然でしょう。 ただし、あまり複合型を定義しすぎると、本来概念クラスとして抽出すべきものまで複合型にしてしまう恐れがあります。概念情報モデルの作成中は、なるべくなら、複合型は単純型のデータ型のみで構成されるものにとどめておくことを推奨します。
データ型の定義は、テキストのみで記述します。
YAMLによる表記
domain: 主題領域名
datatype:
データ型名:
description: 説明
schema: integer, real, string, enum, boolean のどれか、もしくは、複合型の場合は構成するデータ型をリストで定義
unit: 数の場合、その単位名
domain: 数の場合、その値域
pattern: 文字列の場合、その正規表現や構文木
enumvalue: 列挙の場合その値の名前と説明文のリストクラスの特徴値には、以下で説明するような特殊なものがあります。クラスや関係の抽出の際、意識してモデリング作業を進めましょう。
識別子の意味を持つ特徴値
クラスの個々のインスタンスを区別するような“識別子的な値”で、モデル化対象のドメインにおいて明確に意味を持つような場合には、何らかの慣例に基づく英数字と記号で構成された一定のパターンの文字列が決められていることが多いです。一方で単に区別できればよいというような識別子的な特徴値の場合は、あえてその特徴値向けのデータ型を定義する必要はありません。識別子の意味を持つ特徴値を図で表す場合、その特徴値の名前の先頭に”*”を付けます。テキストでの定義の場合は、それが識別子であることを明記します。
概念クラスによっては、複数の特徴値が組み合わさって、概念インスタンスの一意性を表現する場合があります。更には、概念インスタンスの一意性を表現する複数の特徴値の組を持つ概念クラスも存在し得ます。その様な場合は、”*1”、”*2” の様に添え字をつけて区別できるよう定義を行います。
計算可能な特徴値
抽出した特徴値の中には、あるクラスの特定のインスタンスを起点にして関係でつながったインスタンスの数や、そのインスタンス群の特徴値から算出できる値を持つものがあります。これらを“計算可能な特徴値”といい、図で表す場合は、特徴値の名前の後ろに“(M)”をつけ、テキストの定義の場合は、算出方法を記載します。
関係を表す特徴値
クラスと関係の定義による制約のもとにインスタンスをリスト表現する場合、後で詳しく説明するように、便宜的に関係している他のインスタンスを示すための特徴値が必要になる場合があります。リレーショナルデータベースに詳しい読者であれば、外部キーと同等といえば理解できるでしょう。
この様な特徴値は、概念情報モデルの図表現においてはクラスの特徴値として記載しなくても判るので、不必要です。
しかし、存在する概念インスタンス群の全特徴値を表形式で表現する場合には、どの概念インスタンスとどの概念インスタンスがリンクされているのかを示す値が、必ず必要になります。そのため、ここで解説している概念モデリング体系においては、そのようなリンクの値を保持する為の特徴値を概念クラスに明示的に定義し、特徴値の後ろに“(R)”をつけることにします。
このような特徴値を、”参照特徴値”と呼ぶことにします。前のセクション”概念クラス”では、特徴値は2種類と説明しましたが、”参照特徴値”が加わるので、結果的には3種類という事になります。
関係を表す特徴値のデータ型は、“参照型”で、関係でつながっている相手のクラスの識別子と同じ型になります。また、相手側の多重度が、“0..1”の場合は、インスタンスのリンクがない場合があるので、リンクがない場合はNULLとします。
参照特徴値は、多重度によって、どちらの概念クラスに定義するかが変わります。以下に全ての多重度に関する参照特徴値の定義側を列挙しておきます。
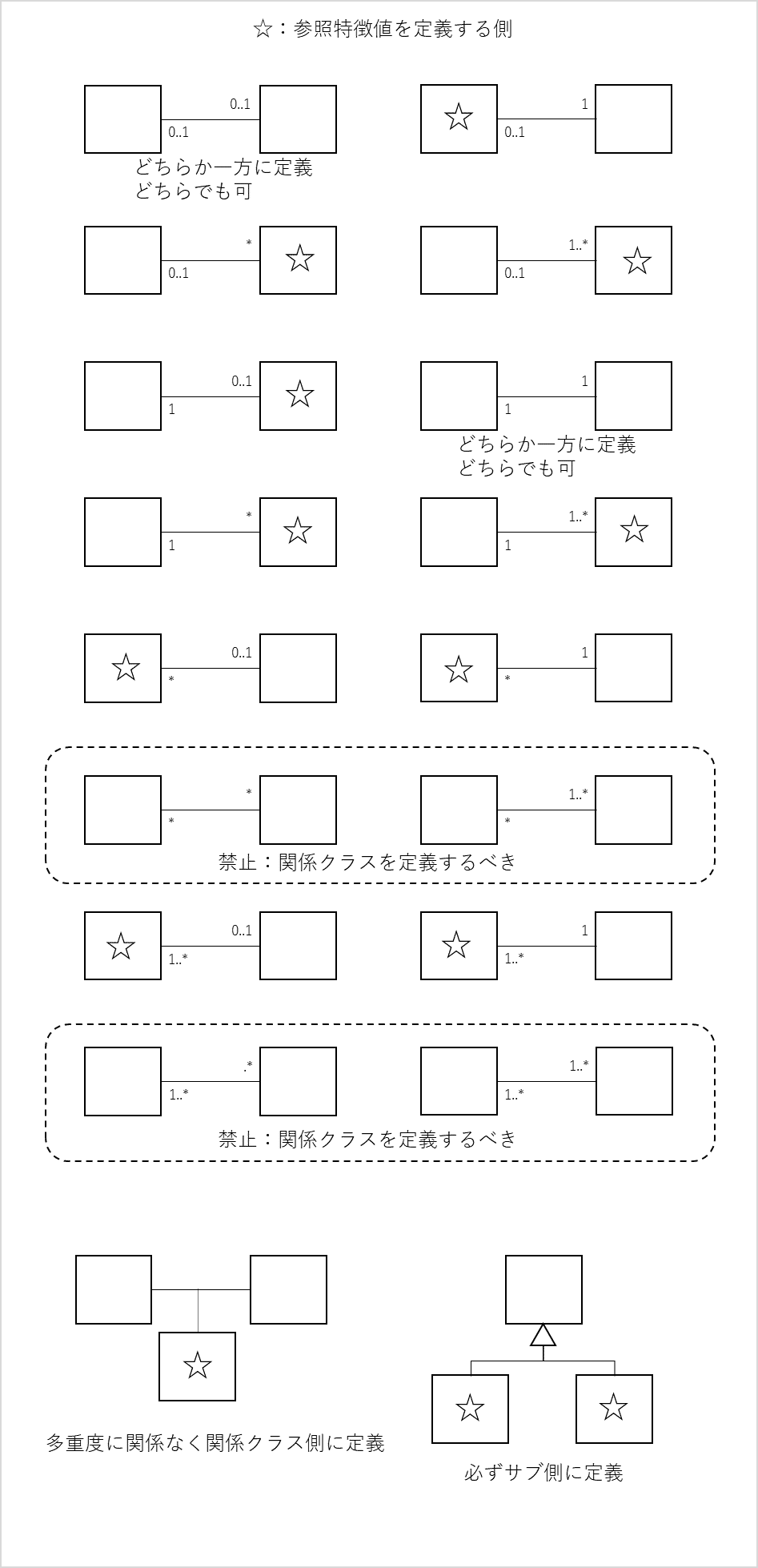
NULL許容の特徴値
“関係を表す特徴値”は、リンクがない場合はNULLであると説明しました。場合によっては、他の型を持つ特徴値の値が主題領域の状態によって意味を持たない時がでてきます。その様な状況がモデル化対象主題領域であり得る場合は、その特徴値が、“NULL許容(Nullable)”であると定義します。 参考までにこれらの特殊な特徴値の表記法を紹介しておきます。

YAMLによる表記
domain: 主題領域名
class:
クラス名:
property:
プロパティ名:
description: 説明
unique: true # 必ず異なる値を持つ場合
relationship: 関係名 # 関係を表す特徴値の場合
mathematical: 計算式 # 計算可能な特徴値の場合
nullable: True|False # NULL許容な特徴値の場合はTrue※ 実は、データ型には、もう一つ、“ANY”という種類があります。これについては、「概念情報モデルを使う」で解説します。
概念情報モデルのまとめ
以上で、概念情報モデルを構成するための全てのピースが登場しました。復習もかねて、ここでそれらを列記しておきます。 - “ドメイン”- ドメインを構成する“クラス”- “クラス”を雛形にしたインスタンスが持つべき特徴値のセット- クラスを雛形したインスタンス間が満たすべき、意味と多重度が定義された“関係”- 特徴値の“データ型”
モデル化対象を吟味してこれらを抽出し明確に定義していく過程を“概念モデリング”といい、成果物が“概念情報モデル”になるわけです。 物事を分析してその本質を抽出することを抽象化といいますが、概念モデリングでは二段階の抽象化を行います。
一段目の抽象化は、皆さんのビジネスにおいて、様々な、モノ、コト、役割といった、その時々の状態や時間の経過に従ってどんどん変化していくインスタンスとインスタンス間のつながりの抽出です。二段目の抽象化は、抽出したインスタンスとインスタンス間のつながりが存在する際の従うべきルールの抽出です。多くの人にとって概念情報モデルが難しいと感じさせる理由が、この二段階の抽象化にあるように思えます。何かを構築する場合、なるべく安定していて変化しにくいものを基盤として使うというのは非常に重要なことです。一段階目の抽象化の結果が時間とともにどんどん変わっていく非常に不安定であるのに対して、二段階目の抽象化はとても安定しています。概念情報モデルの作成は、ビジネスシステムを構築する為の安定した基盤造りであるともいえるでしょう。
ソフトウェアエンジニアリングにおいて、“抽象化”はよく使われる用語ですが、多くの人が“抽象的”という言葉と混同しているように思えます。“抽象的”の反対語は“具体的”なであり、“抽象化”というと曖昧な記述というイメージを持ってしまいがちです。“抽象化”の元の英語は、“Abstraction”であり、この訳を調べると、“抽出”という意味があり、実は“抽象化”は“抽出”の誤訳なのではないかと、筆者は長年考えています。“抽象化”の反対語は“具象化”です。特に本稿での概念モデルの作成の目的は、ビジネスをデジタルトランスフォーメーション可能なシステムを開発するための基盤を構築することなので、曖昧なモデルをなんとなく作るのではなく、ビジネスで扱う様々なエンティティをもれなく抽出し、厳密なモデルを構築することが重要なのは言うまでもありません。
ここまでで、読者は二つの疑問を持つのではないでしょうか。
一つ目の疑問は、“概念情報モデルはいつ完成するのか?”だと思います。これはモデル化対象のビジネスに関わるステークフォルダー達の頭で思い描くビジネスの描像に登場するモノやコトが全て概念情報モデルで定義したルールに従って配置できたとき、が回答になります。 加えて、概念情報モデルを作成しているプロジェクトに関係する全員が、配置できたことを合意していなければなりません。
二つ目の疑問は、“複雑怪奇な現実の世界を、こんな簡単な道具立てで本当に定義できるのか?”だと思います。
詳しくは、玉石混交のコラム集の、
を読んでいただきたいのですが、人間が、現実世界を対象として、明確かつ明晰な論理を思考するには、まず言葉が必要だということが出発点になります。言葉は語の連なりです。語を連ねて現実世界を記述すると複数の文ができあがります。文は、語が適当に連なったものではなく、主語と述語、形容詞、副詞から構成される文法に基いて語が並べらています。皆さんご存じの通り、語は、多義性を持っています。ウィットゲンシュタインなどの言語哲学によれば、文の意味は、意味が確定した語が文脈に従って並んでいるから確定するのではなく、文脈において語と語の関連において決まるだけでなく、さらには、文全体、もっと言えば、使用可能な語と文法からなる言語全体から決まるものだとされています。
一方、概念情報モデルは、語を、以下のような、概念情報モデルの文法によって関連付けていきます。
名前(語)を持ち、かつ、単位や値域が紐づけられた、データ型
データ型によって規定される名前(語)をもった特徴値
特定の特徴値の組で状態を記述する、名前(語)をもった概念クラス
双方向で、多重度と意味(語、あるいは、語の連なり)を持って、二つの概念クラスを紐づける関係(Relationship)
これらの道具立てにより、語と語の間の関連を記述するという、人間が言葉によって思考を巡らしながら記述していくのと本質的に同等な流れで、自然文で書いた文章よりも、厳密、かつ、複数の文の関連も明確な記述を可能とします。
そもそも、人間が現実世界を記述することにおいて、人間の思考パターンを超えることはできません。これらの事実を合わせれば、
モデル化対象となる、複雑怪奇な現実の世界を、人間の思考可能な範囲で記述できるならば、概念情報モデルの道具立てで十分である
と考えて良いでしょう。
ものを主体に抽出するモデリングにおいては、モデル作成者は概念クラスに相当するようなものの抽出に注意が行きがちです。しかし、ここに書いたように、概念クラスは、紐づけられた特徴値の組と関係(Relationship)があって初めて意味をなします。曖昧な語で名前が書かれた四角形と両端に何も書かれていない線を描いただけでは、概念情報モデルを作ったことにはなりません。語の意味が、語と語の関連で確定するのであれば、概念情報モデルの主役は、概念クラスではなく、むしろ、関係(Relationship)であると感がながら、概念情報モデルを作成するとよいでしょう。
これに答える前提として、先ずは、概念モデリングは哲学ではない、というのが重要なポイントです。概念モデリングを行う目的はあくまでビジネスシステムのデータ基盤を構築するというものなので、ビジネスとしてデジタル化したい情報に関する存在ルールが全て概念情報モデルで正しく定義されているかが一番のポイントです。
概念モデルは、モデル作成者が「私はこのビジネスをこう理解しましたよ!」という表明です。一つ目の疑問に対する回答を基準にして、自信をもって表明しましょう。
概念情報モデルの基礎に関する解説は以上です。次は、「概念情報モデルを使う」で、概念情報モデルの使い方を解説します。