
113. DTDL Generator の日本語文字化けを直す

はじめに
今回は、前回書いた通り、日本語の文字化けの問題を解決に向けた取り組みを、ありのままに、書いていきます。
結果的には、YaccLextTools のバグだったんだけどね(苦笑)…
DTDL Generator の仕組み
その前に、DTDL Generator の仕組みを簡単に説明しておくことにします。
詳細は、
BridgePoint で作成した概念モデルから DTDL 定義を自動生成する|Knowledge & Experience
に書いてあるので、そちらも見てほしい。
全体のフロー
処理の流れは、

こんな風になっていて、概念モデリングのメタモデルと基本データの定義を読み込んで、それに合わせて、BridgePoint で作成した HealthCare モデルを読み込んで、DTDL に変換しているという流れ。
Parser
概念モデリングのメタモデル=xtumlmc_schema.sql は、SQL を拡張した文法でメタモデルのスキーマが記述されたテキストファイルです。どんなふうに拡張されているかというと、もともとある TABLE = 概念クラスという対応付けに加えて、”ROP REF_ID”で Relationship を定義できるようになっている。私が書いて公開している概念モデリングの基本で、
人間の思考は言語を前提としている
認識は、事柄、事柄の性質、事柄間の意味的つながりでなりたつ
認識は、ある意味の場を通じて行われる
と、紹介しているのだけど、もともとの SQL は”事柄間の意味的つながり”を明示的に書く方法がないので、それを追加したということ。
Azure Digital Twins の DTDL は、一応 Relationship を明示的に記述する方法はあるものの、Twin(=Interface…これも微妙なんだけどね。まぁある意味、意味の場を通じて存在にアクセスして事柄を拾い上げるので、Interface と言えなくもないのだけれど…微妙、微妙、微妙)に従属した形式で Relationship を定義できるようにしている。哲学的な本来的な視点からすると、Relationship は独立して記述できたほうが、より、オントロジー的だと思う。まぁオブジェクト指向プログラミングの影響が強すぎるというのが、原因の一つと思われるのだけれど。
Globals.xtuml、HealthCare の sql の拡張子がついたファイル群は、メタモデルスキーマのインスタンスという扱いになる。
で、これらのファイルは、日本語をはじめとするマルチバイトのテキストを保持できるように、UTF-8 でエンコードされて保持されている。それを読み込んで、GitHub - ernstc/YaccLexTools: This package includes GPPG and GPLEX tools for compiling YACC and LEX source files in your C# project. Useful if you want to create a compiler, a transpiler or interpret a formal language. で開発されていて、NuGet パッケージとして公開されているパッケージを使って、字句解析・構文解析のロジックを組んでいる。
Yacc、Lex は、UNIX の時代からあるツールで、Lex が字句解析、Yacc が構文解析をそれぞれの文法に従ってパターンで記述するとパーサーの実装をC言語のプログラムとして生成してくれるという、知っていればとても便利な代物。ちなみに、GNU版は、それぞれ、flex、bison という名前になっている。
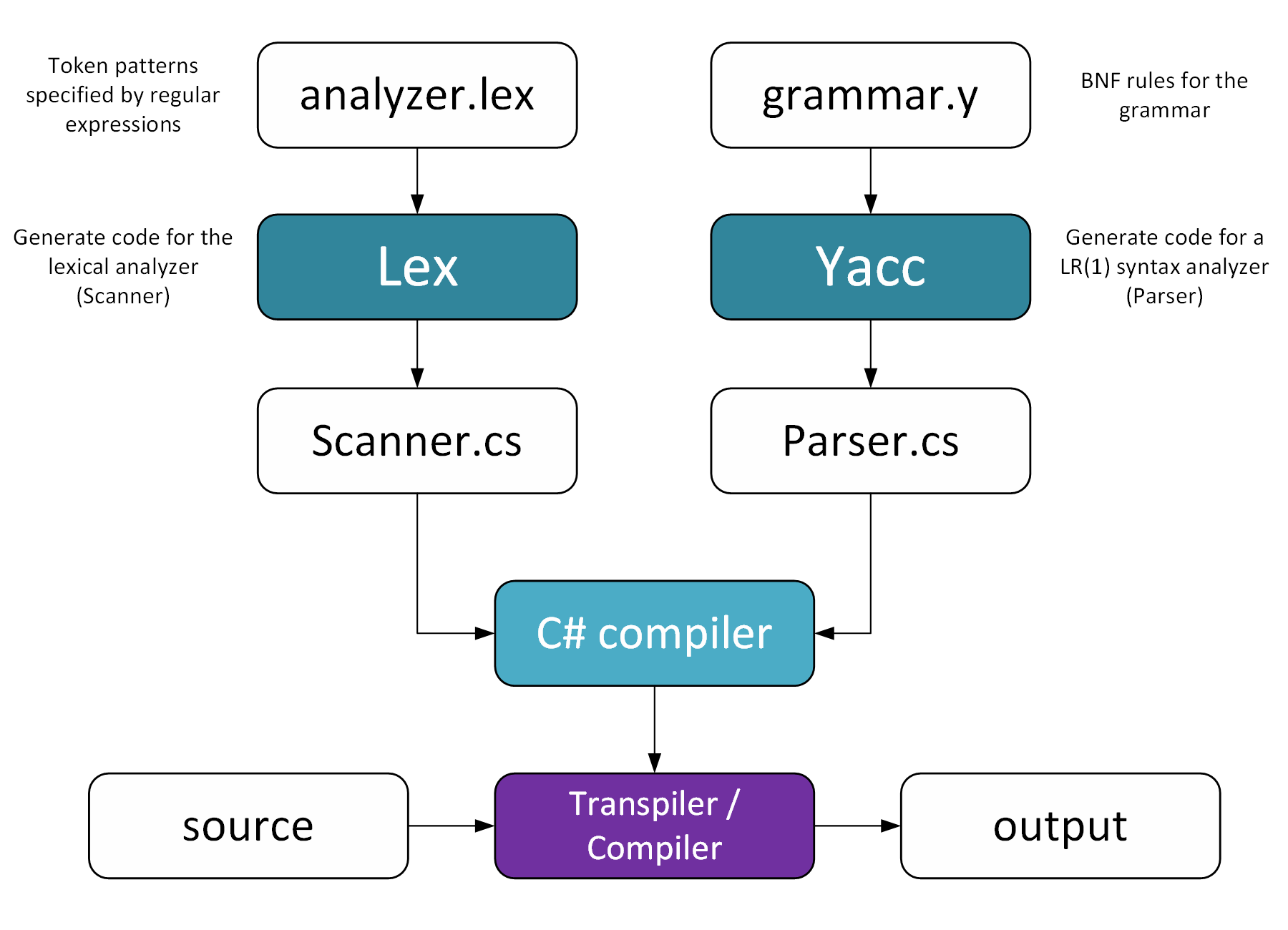
んでもって、YaccLexTools は、C# のパーサーの実装コードを生成してくれる。

私が作成した、
xtuml-ooa-of-ooa-library/Kae.XTUML.Tools.MetaModelGenerator at main · kae-made/xtuml-ooa-of-ooa-library · GitHub
では、上の図のように、Lex の定義ファイル(.lex)と Yacc の定義ファイル(.y)を拡張された SQL ファイル用に作って、パーサーを実装している。ちなみに、
XTUMLOOAofOOAParser.Language.analyzer.lex
→ XTUMLOOAofOOAParser.Scanner.Generated.cs
XTUMLOOAofOOAParser.Language.grammer.y
→ XTUMLOOAofOOAParser.Parser.Generated.cs
で、生成されている。残りの、XTUMLOOAofOOAParser.Parser.cs と XTUMLOOAofOOAParser.Scanner.cs は、生成された C# ファイルが字句・構文解析した後の結果の処理を手書きで書いた実装ファイル。
文字化けが発生しうる場所
結果として、文字化けを起こしているのは、

と、赤い点線で囲んだ部分だということになる。そこを順番に調べて発見することにした次第。
文字化けしている処理を特定する
以下、順に調べていくことになるわけですが、まずは、C# の文字列におけるエンコーディングの基本をおさらいすることにします。
C# の基本エンコーディングと処理のパターン
ここから先は
Azure の最新機能で IoT を改めてやってみる
2022年3月にマイクロソフトの中の人から外の人になった Embedded D. George が、現時点で持っている知識に加えて、頻繁に…
この記事が気に入ったらチップで応援してみませんか?