
118. C# コードジェネレータバグフィックス ~ その2

はじめに
前回に引き続き、C# コードジェネレータの障害対応のリアルを書いていきます。今回対応するのは健診受診のモデルからの自動生成で発生した以外の障害への対応です。
症状
テストモデル(TestModelForHC)から C# のコードを生成したとき、生成された DomainClassEStateMachine.cs で、

のようなビルドエラーが発生しました。普段からプログラムを書きまくっている人なら、何が悪いのかすぐに分かりますよね。
私は最近は、それほどコードを書きまくっていないので、しばし、「なんじゃこりゃ?」状態。
そうです、エラーの原因は、States という列挙型の列挙子の”1stStep”、”2ndStep”が数字から始まっていること。
原因
C/C++、C#、Java をはじめとするほとんどのプログラミング言語では、数字から始まる文字列を列挙子や変数、型、メソッドの名前として使ってはいけないことになっています。
このコードを生成している変換ルールは、Kae.XTUML.Tools.Generator.CodeOfDomainModel.Csharp の template/DomainClassStateMachine.tt に記述されています。

C# の列挙子として記述する文字列は、図中の赤下線を引いた部分で、BridgePoint で描いた状態モデルの状態それぞれの名前(attr_Name に入っている)がそのまま使われます。
このルールの適用対象の状態モデルは、概念クラス E の状態モデルを見ると、
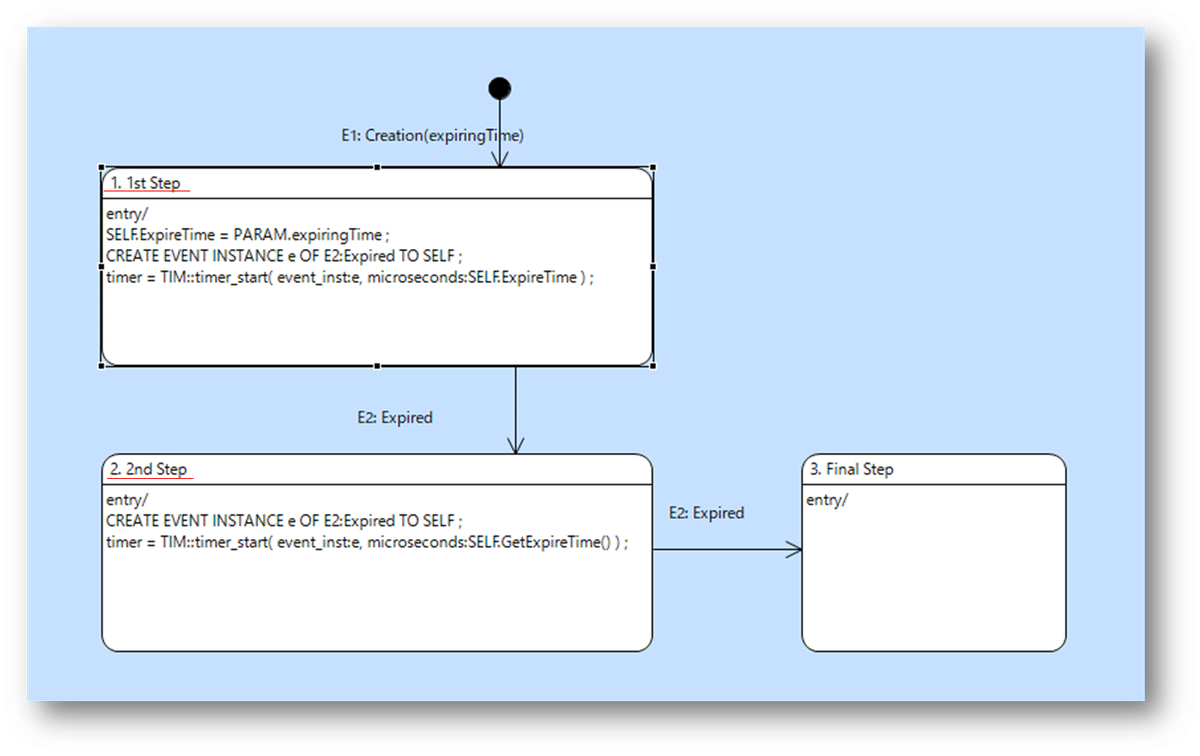
”1. 1st Step”、”2. 2nd Step”となっていて、この太字の部分がそのまま C# コードで使われているってことになります。
対応策として
要するに、数字から始まる状態名が出てきた場合は、何等かの変換を施して数字で始まらないような名前にすれば障害は対策完了です。ですが…
実務レベルでは、対応策が二つあります。
運用でカバーする
一つ目は、概念モデルを作成する際、
”何かの名前を付けるときは、1文字目は数字にしないこと”
というルールを決めてモデラーさん達に周知徹底させるというもの。
これは、例えば、3rd Party 製のジェネレータを使っていて、障害対応に時間がかかるような場合ですね。ジェネレータを社内外が開発したビジネスシステムに置き換えて考えてみると、そんなツールに使用上の問題があるときに、適応力旺盛な優秀(?)な現場社員がいるときは、結構ありがちな状況ではないかと思います。
話を概念モデルからのコード生成に戻しますね。しかし、モデル化対象の現実世界を正しく書き下す概念モデリング体系からすると、状態名を数字から始めていけない真っ当な理由は一切存在しません。
だから、ジェネレータを修正するのがやはり本来的。問題を抱えたビジネスシステムでも、案外、いつの時点でか開発者が気が付いて問題が修正されていて、現場側に謎の運用ルールが残っている状態になっているという事態も結構あるのではないかと想像します。
変換ルールを直す
対応策は、数字で始まる文字列で名前付けされた状態を見つけたら、数字で始まらない文字列に置き換えることです。今回は、”0、1、…、9”をそれぞれ”Zero、One、…、Nine”に置き換えるというルールを追加することにします。問題の変換ルールの一つ(列挙子を使って遷移配列を記述する)を、
<#
var sttDef = stateTransferTableDef.OrderBy(entry => entry.StateNumber);
index = 0;
foreach(var sttEntry in sttDef)
{
string sttRowDef = "";
foreach(var nt in sttEntry.NexTransitions)
{
if (!string.IsNullOrEmpty(sttRowDef))
{
sttRowDef += ", ";
}
string nextState = "";
if (nt.NextStateDef != null)
{
nextState = $"States.{GeneratorNames.GetStateEnumLabelName(nt.NextStateDef)}";
}
else
{
if (nt.IsIgnore)
{
nextState = "ITransition.Transition.Ignore";
}
else if (nt.IsCantHappen)
{
nextState = "ITransition.Transition.CantHappen";
}
}
sttRowDef += $"(int){nextState}";
}
#>
{ <#= sttRowDef #> }<# if (++index < stateTransferTableDef.Count()) { #>, <# } #>
<#
}
#>
のように、”GeneratorNames.GetStateEnumLabelName(nt.NextStateDef)”というように、 method 内で妥当な変換を施した文字列を使うように修正を行いました。GetStateEnumLabelName という method は、GeneratorNames.cs というファイルに、
public static string GetStateEnumLabelName(CIMClassSM_STATE stateDef, bool isDecl = false)
{
var name = ToProgramAvailableString(stateDef.Attr_Name);
if (Regex.Match(name, @"^[0-9]").Success)
{
string[] replace = { "Zero", "One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine" };
int numOfBegin = int.Parse(name.Substring(0, 1));
name = $"{replace[numOfBegin]}{name.Substring(1)}";
if (isDecl)
{
name = $"/* {numOfBegin} */ {name}";
}
}
return name;
}
のように追加しています。状態をもとに変換する列挙子に限らず、クラス名やメンバー変数名などは、宣言と様々なコードの場所で使われるので、このように一つのファイルにまとめて実装しています。GetStateEnumLabelName はデフォルトが false の値を持つ isDecl というオプション引数を持っていますが、こちらは、状態名の列挙型の変換ルールの、
<#
stateDefs = stateDefs.OrderBy(s => s.Attr_Numb);
index = 0;
#>
public enum States
{
_NoState_ = 0,
<#
foreach (var stateDef in stateDefs)
{
var stateName = GeneratorNames.GetStateEnumLabelName(stateDef, true);
#>
<#= stateName #> = <#= ++index #><# if (index < stateDefs.Count()) { #>,<# } #>
<#
}
#>
}
で、使用する列挙子の名前が、宣言で使うことを指示しています。
この修正適用で生成したコードは、
public partial class DomainClassEStateMachine : StateMachineBase, ITransition
{
public enum Events
{
E_1 = 0, // Creation
E_2 = 1 // Expired
}
public enum States
{
_NoState_ = 0,
/* 1 */ OnestStep = 1,
/* 2 */ TwondStep = 2,
FinalStep = 3
}
… 中略 …
protected int[,] stateTransitionTable = new int[3, 2]
{
{ (int)ITransition.Transition.CantHappen, (int)States.TwondStep },
{ (int)ITransition.Transition.CantHappen, (int)States.FinalStep },
{ (int)ITransition.Transition.CantHappen, (int)ITransition.Transition.CantHappen }
};のように、ビルドエラーが発生しない C# コードに変換されるようになりました。めでたしめでたし。
宣言のほうに、コメント形式で元の数字がなんであるかを明示するようにしています。
生成コードの取り扱い
”変換による実装”においては、実際にコンピューティング環境で動く C# コードは、ソースコードではありません。”変換による実装”では、ソースはあくまでも、”概念モデル”と”変換ルール”であって、通常ソースコードと呼ばれているプログラムコードは、単なる派生物だからです。
このことは、”変換による実装”を実開発で取り入れるときには、一般的な手書きによるソフトウェア開発を前提として定められた開発プロセスを改変しなければならないことを意味します。バージョン管理を行うべきは、ソースファイルではなく、概念モデルと変換ルールであり、レビューすべきもソースコードではなく、概念モデルと変換ルールです。
生成したコードを実行した際に生じる障害対応を、ソースコードで行うことは厳禁です。必ず、概念モデルか変換ルールのどちらかで対応することになります。BridgePoint はモデルベリファイヤがあって、振舞いも含め概念モデルの形式的な間違いはほぼ存在しないのと、変換ルールのミスは、今回のようにビルドエラーになることがほとんどなので、どちらの問題かを切り分けるのは比較的容易です。変換による実装の実開発への導入は、このような特性を踏まえた開発プロセスへの改変を行わなければなりません。
また、開発スキルの低い開発組織が作成したソースコードは、品質が低く、ちょっとどこかを弄っただけで、動かなくなったりするものです。そういう組織では、コードの変更に対してとても臆病なものです。変換による実装の場合、
コード生成=すべてのコードが置き換わること
なので、それに対する上層部の拒否感は半端なく、”自動生成なんてとんでもない!”という状況になるかもしれませんね。
概念モデリング×変換による実装 = ソフトウェア開発の DX 化
このように書いてくると、読者の中には、「変換による実装ってずいぶん特殊だな…」なんて思う人がいるかもしれませんね。
ただ、よくよく考えてみると、変換ルールがやっていることは、
ここから先は
Azure の最新機能で IoT を改めてやってみる
2022年3月にマイクロソフトの中の人から外の人になった Embedded D. George が、現時点で持っている知識に加えて、頻繁に…
この記事が気に入ったらチップで応援してみませんか?