
OpenAIの音声認識モデル "Whisper" を使ってZoomの文字起こしをやってみた

2023年に入ってからOpenAIのGPT-3を搭載したChatGPTを筆頭に、AIツールがどんどん登場しています。
「オンラインミーティングの議事録を手間かけずに作りたいなぁ…」と思い、OpenAIの音声認識モデル「Whisper」を触ってみることにしました。
このnoteは、音声認識モデル「Whisper」を使って音声を文字起こしする過程をまとめた勉強メモです。
このnoteのターゲット
議事録の作成がめんどくさいと思ってる人
オンラインミーティングを普段からやっている人
このnoteで得られること
音声認識モデル "Whisper" の使い方が分かる
Zoomのレコーディングから文字起こしする方法が分かる
文字起こしをするステップ
Whisperを使っての文字起こしは、以下の3ステップで実施することができます。
Google Colaboratoryの設定
音声ファイルをアップロード
文章を整える
1. Google Colaboratoryの設定
まずはGoogle Colaboratoryにアクセス。「New Notebook」をクリックします(画像は英語表記ですが、日本語だと新規作成とかになっていると思います)。

右上の「Connect」をクリック。
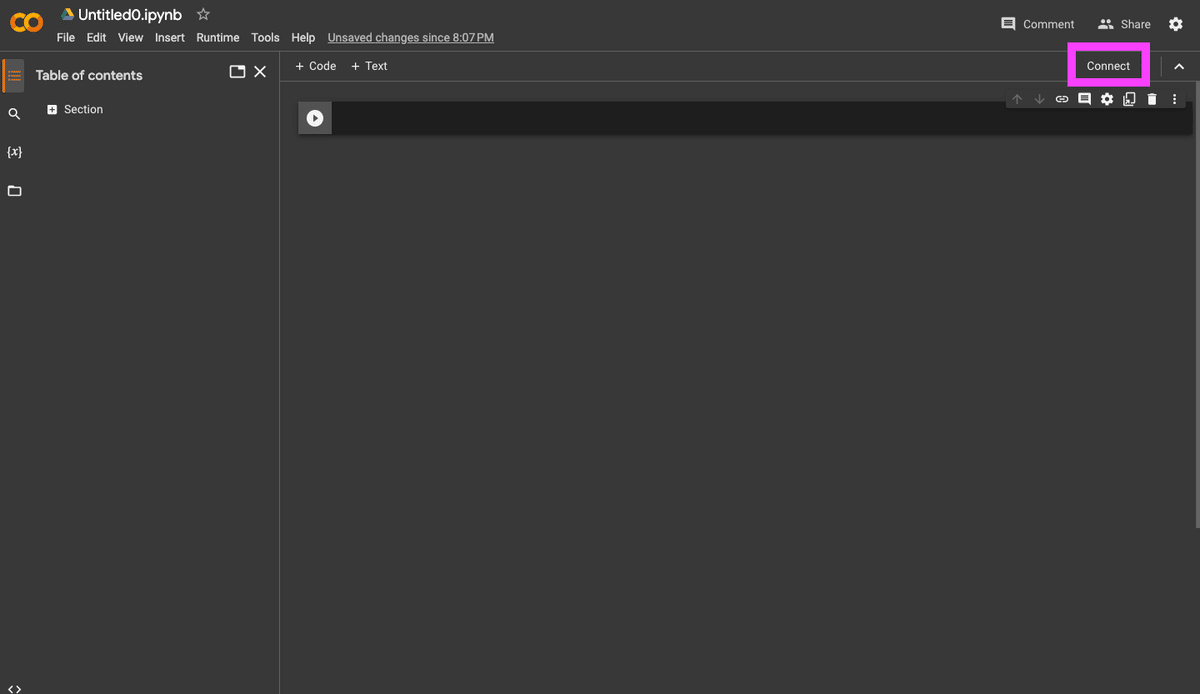
Connectのところが「RAM Disk」に変わったら再度クリックし、「Change runtime type」をクリック。
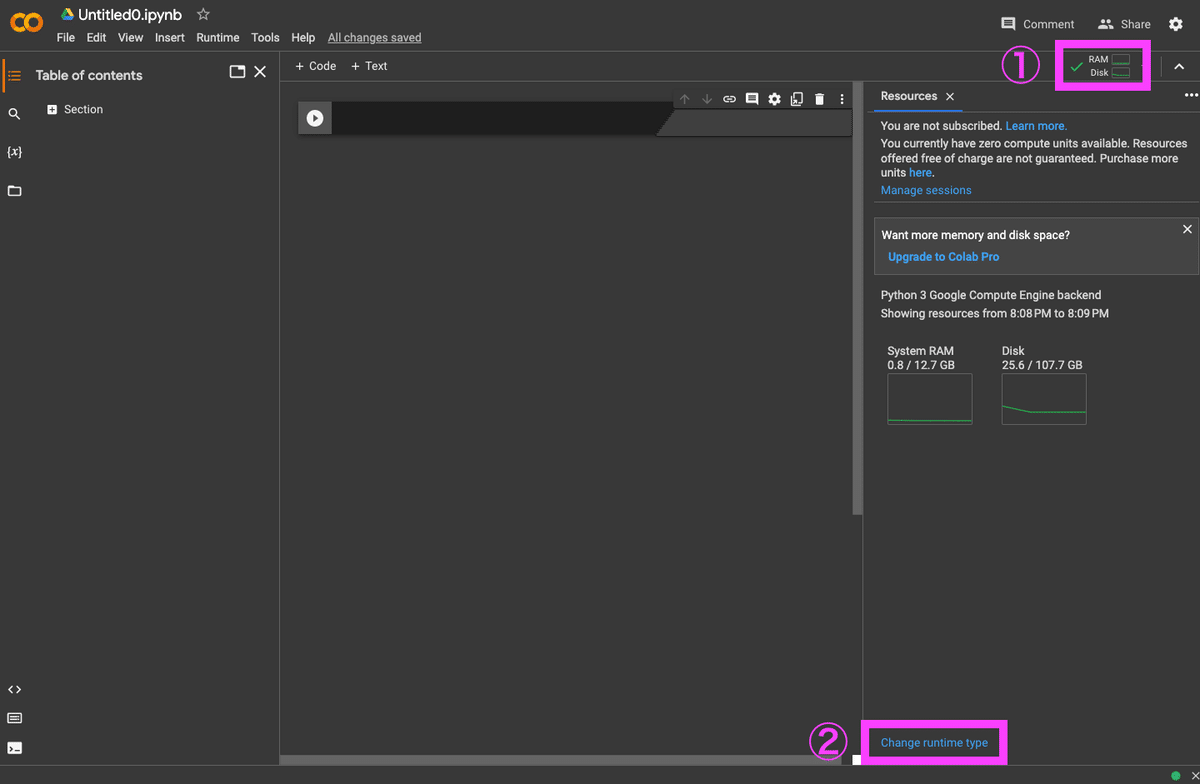
Hardware acceleratorで「GPU」を選択し、「Save(保存)」をクリック。

以下のコードを入力し、左隣にある再生ボタンを押します。
!pip install git+https://github.com/openai/whisper.git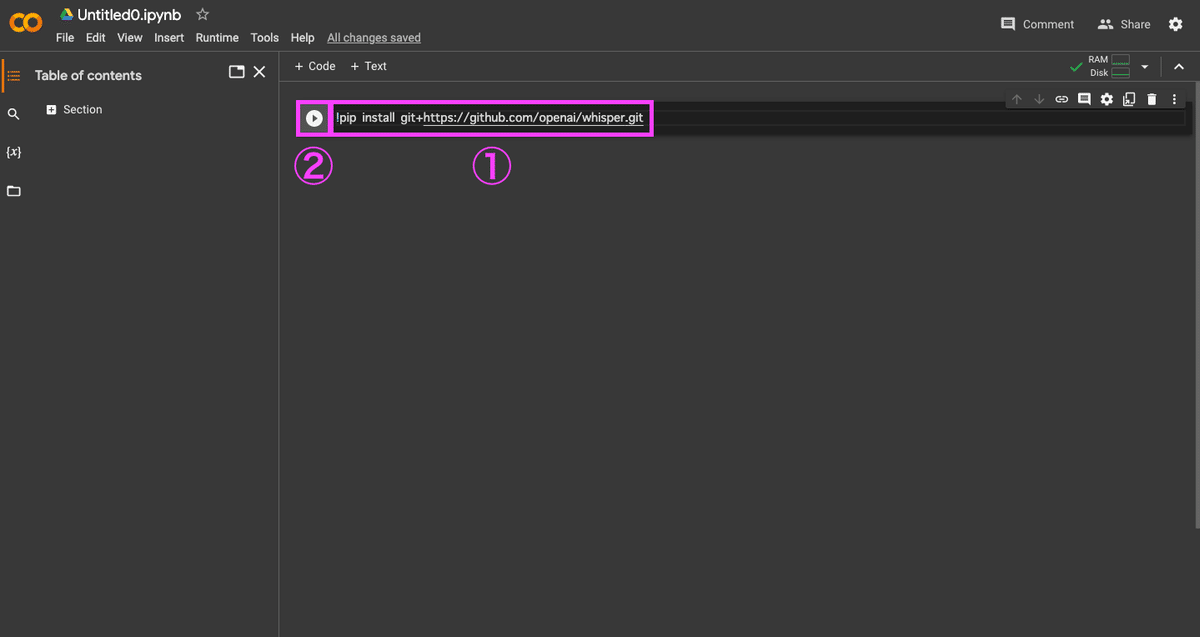
コマンドが実行されたら、上にある「+ Code」をクリック。

入力欄が表示されたら、以下のコードを入力して再生ボタンをクリックします。
import whisper
2. 音声ファイルをアップロード
Whisperのインポートは数秒で終わったかと思います。左サイドバーにあるフォルダをクリック。
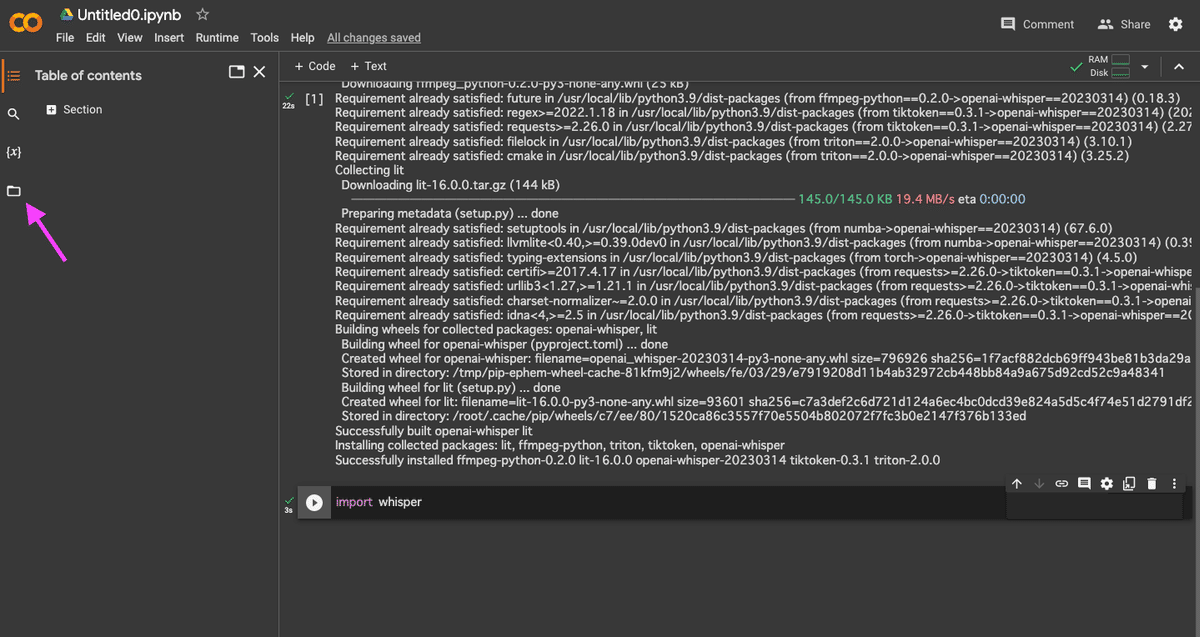
「content」の横にある三点リーダをクリックし、音声ファイルをアップロードします。
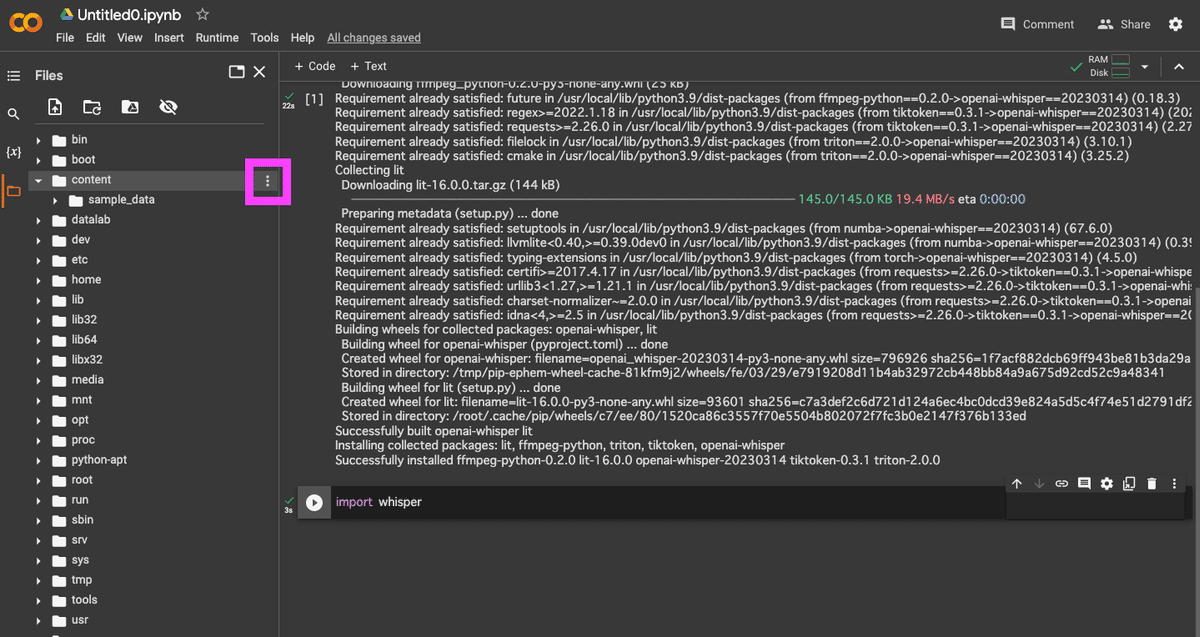
「Upload」から音声ファイルを選択。

音声ファイルをアップロードしたら再度「+Code」からコードの入力欄を追加し、以下のコードをコピペしてそれぞれ実行します。
model = whisper.load_model("base")
上記コードの "base" の部分は、"small" や "large" などのモデルも使用でき、文章の精度に影響があるようです。
■ 参考:OpenAIの文字起こしAI「Whisper」の使い方|Smiley
続いて、以下のコードも入力欄を追加して実行。
result = model.transcribe("/content/ファイル名", language="ja")
print(result["text"])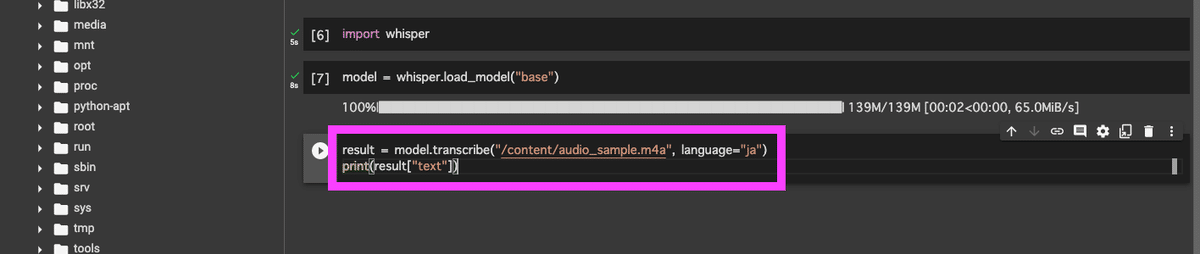
※ 上記コードの「ファイル名」の部分は、アップロードした音声ファイルの名前に変更してください。
音声ファイルから文字起こしが完了します。出力された日本語をコピーし、メモ帳などに貼り付けて確認してください。
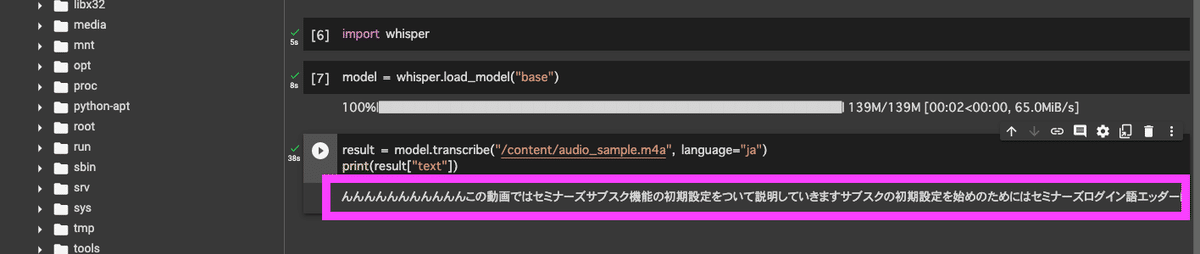
3. 文章を整える
文字起こしの文章は必ずしも読みやすいものではなかったりします。なので、ChatGPTに雑にお願いして整えてもらいました。

以下の文章を正しい日本語に修正してください。
このプロンプトだけでもかなり読みやすい、自然な日本語に修正することができました。微修正は必要ですが許容範囲だと思います。
参考記事
この記事が気に入ったらサポートをしてみませんか?