
GPUなしで動くAI?並列処理の秘密と大規模言語モデルの未来

みなさん、こんにちは!今日は、AIの世界で注目を集めている「GPUなしで大規模言語モデル(LLM)を動かす可能性」について探っていきます。でも、その前に押さえておきたい重要な概念があります。それが「並列処理」と「逐次処理」です。
並列処理vs逐次処理:AIの裏側で何が起きているの?
逐次処理:一つずつ、順番に
「逐次処理」は、タスクを一つずつ順番にこなしていく方法です。料理で例えると、一人で野菜を切り、次に肉を焼き、最後にソースを作るようなものですね。コンピュータの世界でも同じで、計算や処理を一つずつ順番に行います。
並列処理:みんなで一緒に
一方、「並列処理」は複数のタスクを同時に行う方法です。レストランのキッチンを思い浮かべてください。シェフが野菜を切り、別の調理師が肉を焼き、もう一人がソースを作っている...これが並列処理です。コンピュータの世界では、複数のプロセッサーやコアが同時に異なる計算や処理を行うことを指します。
AIと言語モデルの場合は?
大規模言語モデル(LLM)は膨大な量の計算を必要とします。並列処理を使うと、文章の異なる部分を同時に分析したり、複数の可能性のある次の単語を同時に計算したりできるんです。
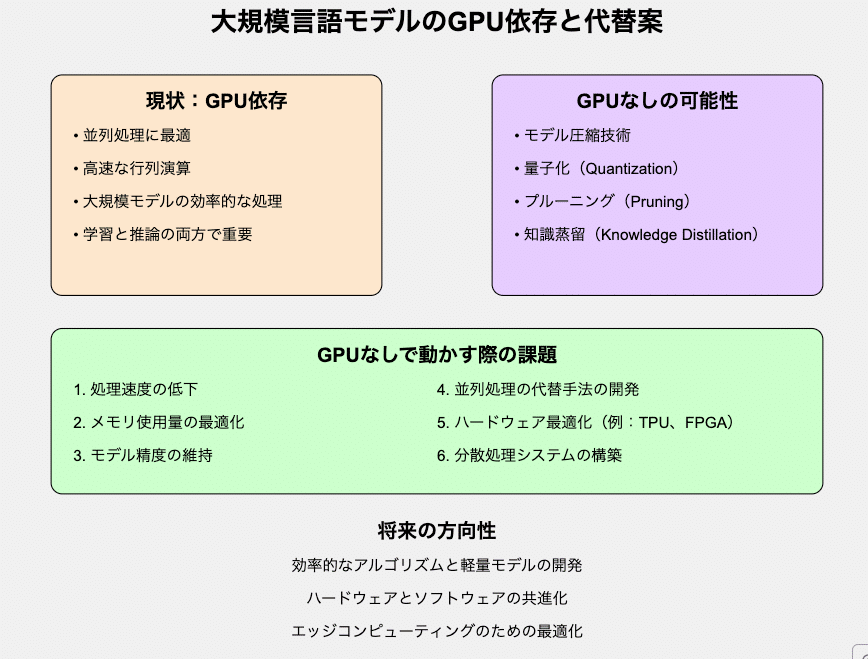
なぜGPUが重要なの?
ここでGPUの出番です。GPUは数千の小さなコアを持ち、大量の並列処理を行うことができます。これは、レストランのキッチンで数千人のシェフが同時に働いているようなものですね!だからこそ、GPUはAI、特に大規模言語モデルの処理に適しているのです。
でも、GPUなしでAIを動かせないの?
現状では、LLMは主にGPUの並列処理能力に依存しています。しかし、GPUは高価で電力消費も大きいため、AIの普及の妨げになっているんです。そこで、研究者たちはGPUなしでLLMを動かす方法を模索しています。
GPUなしの可能性を探る
モデル圧縮技術:
量子化:パラメータの精度を下げてモデルサイズを縮小します
プルーニング:重要でないパラメータを削除します
知識蒸留:大きなモデルの知識を小さなモデルに転移します
効率的なアルゴリズム:
スパースアテンション:全ての入力トークンではなく、重要なものだけに注目します
プログレッシブ計算:必要に応じて段階的に計算の複雑さを上げます
専用ハードウェア:
TPU:Google開発のAI専用チップです
FPGA:プログラム可能な集積回路です
分散処理:
複数のCPUやローエンドGPUで処理を分散します
エッジデバイスでの協調計算を行います
課題はまだまだ山積み
しかし、GPUなしでLLMを動かすには、まだまだ課題がたくさんあります:
処理速度の低下
メモリ使用量の最適化
モデル精度の維持
並列処理の代替手法の開発
ハードウェアの最適化
分散処理システムの構築
これらの課題を乗り越えるのは簡単ではありませんが、研究者たちは日々努力を重ねています。
未来への展望
将来的には、効率的なアルゴリズムと軽量モデルの開発、ハードウェアとソフトウェアの共進化、エッジコンピューティングの最適化などが進むでしょう。GPUなしでLLMを動かすことができれば、AIの利用がより身近になり、新しいアプリケーションや革新的なサービスが生まれる可能性があります。
まとめ
並列処理はAIの性能向上に重要な役割を果たしています。
現在のLLMはGPUの並列処理能力に大きく依存しています。
GPUなしでAIを動かす試みは、並列処理の能力をどう代替するかが大きな課題です。
モデル圧縮、効率的なアルゴリズム、専用ハードウェアなど、様々なアプローチが研究されています。
この記事が気に入ったらサポートをしてみませんか?