多くの変数から重要な変数をスクリーニングする方法 第2回:応答のスクリーニング

増川 直裕
スクリーニングシリーズの第2回です。前回は「説明変数のスクリーニング」を紹介しましたが、今回は「応答のスクリーニング」の紹介です。
その名の通り、応答変数(Y)が多数ある場合に、重要な応答をスクリーニングすることを意図した機能なのですが…

実際は多くの単変量解析を一度に実行し、検定結果等を表形式でまとめられるメリットがあり、多くの検定を一度に実行するときに非常に便利な機能です。
「応答のスクリーニング」は非常に多くのことができるのですが、この記事では主な特徴を中心に紹介します。
■「応答のスクリーニング」による分析の流れ
単変量解析とは、1つのY(応答)と1つのXと関係をみる解析のことです。JMPでは、「二変量の関係」というプラットフォームで実行でき、Yの尺度(連続、順序/名義)、Xの尺度(連続、順序/名義)の組み合わせに対し、最適な分析レポートが表示されます。

「二変量の関係」でも単変量解析が実行できますが、多くのYや多くのXを分析対象として単変量解析を行った際、多くの組み合わせに対して単変量解析を実行するので、非常に多くのレポートが表示されます。
例えばYが100個あり、Xが10個あったとき、YとXの組み合わせは1,000通りあるので、1,000個分のグラフや統計量、検定結果などが表示されるのです。
さすがに1,000個もあると、その中から重要な組み合わせを調べるのが困難です。そこで、今回紹介する「応答のスクリーニング」の出番になります。
重要な変数をスクリーニングするために、「応答のスクリーニング」では次のような流れで、分析を進めていきます。
手順
① 多数の変数間の関係を調べるために、単変量の検定処理を一度に行う。
② 多くの検定結果が一度に参照できるように、表やグラフで表現する。
③ 気になる検定についてドリルダウンし、詳細な結果を確認する。

では、実際の例を行ってみましょう。
■「応答のスクリーニング」の実施例
JMPのサンプルデータ「Drosophila Aging」を用います。ショウジョウバエの実験データで、遺伝子型、性別、週齢、チャネルの組み合わせに対し、100個の遺伝子に対する発現量を測定したデータです。
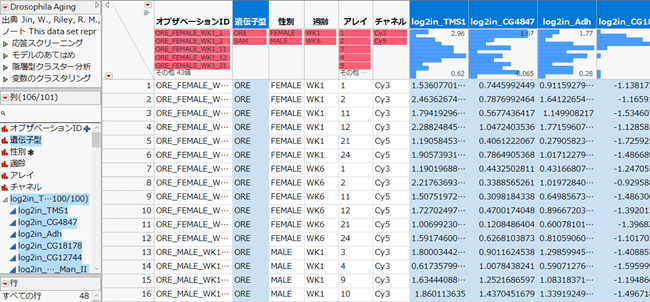
このデータを用い、100個の遺伝子から遺伝子型(ORE, SAM)間で発現量に差があるものを調べることを目的とします。このとき、YとXは次のようになります。
Y: 遺伝子発現量 (log2in_XXXX) 100個
X: 遺伝子型(ORE, SAM)
すなわち、2つのグループ間(ORE, SAM)での発現量の比較検定を100回実施することになります。
JMPのメニューから [分析] > [スクリーニング] > [応答のスクリーニング] を選択し、次のように[Y, 応答変数] と[X]を指定します([Y,応答変数]には100個の連続尺度の列を指定しています)。
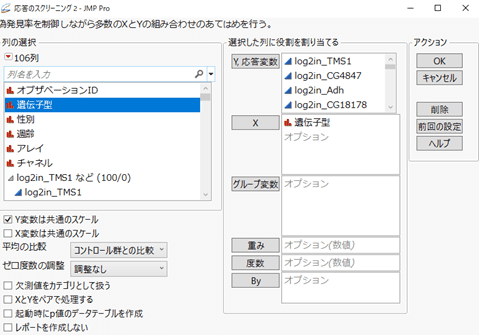
すると、次のレポートが表示されます。

レポート下側に表示される表から見ていきましょう。Xに指定した遺伝子型の違いによりYの値に差があるかどうかを検定した結果が、p値が小さい順に表示されます。
ここで表示されるp値は、t検定を実施したときの値になります。さらに対数価値やFDR P値、FDR対数価値という値も表示されていますが、それぞれの意味は以下のとおりです。
p値: 検定のp値(調整なし)
対数価値: - log10(p値) で算出される値。値が大きいほど有意度が高いことを示し、値が2以上(p値が0.01以下)の項目に色が塗られる。
FDR P値: FDR(False Discovery Rate)を考慮した多重性調整のp値。 (多くの比較をしていることにより生じる検定の多重性を調整している。)
FDR 対数価値: FDR P値に対する対数価値
上に表示されているグラフ(FDR P値プロット)は、上記で説明したp値、FDR p値を値が小さい順に左から右にプロットしたものです。 FDR p値 < 0.05 を基準に有意かどうかを判断したとき、下図で選択されている(青色で反転している)2つのY(log2in_TMS1, log2in_BcDNA_GH06717)が有意です。
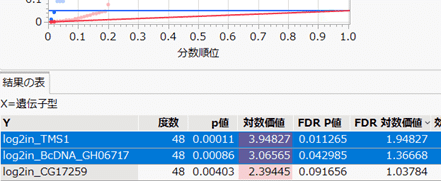
この段階で、100個のYから2個のYをスクリーニングしたと言っても良いでしょう。
■スクリーニング結果のドリルダウン
「応答のスクリーニング」は、ここからがすごいのです。スクリーニングされた項目についてドリルダウンし、さらに詳細なレポートを表示できます。
表から詳細なレポートを表示したい項目を選択し、左上の赤い三角ボタンから [選択した項目の二変量関係] オプションを選択すると、次のように、遺伝子型(ORE, SAM)でYの値を比較したグラフや詳細な統計量が表示されるのです。
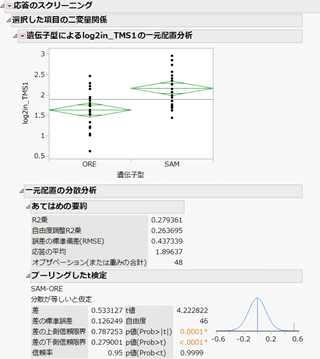
こちらは、JMPでおなじみの「二変量の関係」における「一元配置分析」のレポートです。グラフをみると、明らかにOREとSAMでYの分布に違いがあることがわかります。
■単変量解析のスクリーニングに
ここまでで応答変数Yのスクリーニング例を示しましたが、「応答のスクリーニング」は、単変量解析におけるスクリーニングで利用することができます。特に応答だけのスクリーニングに特化して考える必要がないのです。
Yが1個で、Xが100個あった場合や、Y/Xともに複数個あった場合でも、すべての組み合わせで単変量解析を実施し、上記に示したようなp値の表やグラフを表示できます。
先ほどの遺伝子の例では、Xに遺伝子型という変数1つを入れましたが、このデータはほかにも性別、週齢、アレイ、チャネルといったグループ変数がありますので、これらもXに指定してみましょう。

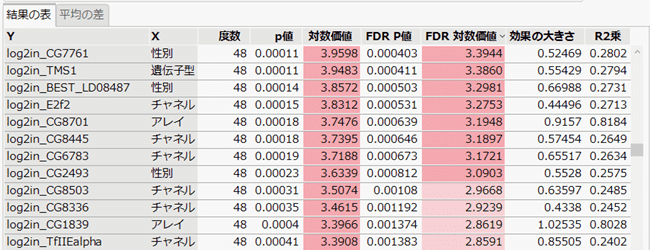
Yを100個、Xを5個指定しているので、500の組み合わせで検定を実行することになります。
先ほどと同様にp値の表が表示されますが、今回の例ではXが複数あるので、YとXのすべての組み合わせ(500組)に対し、p値の小さい順にレポートが表示されます。
■重要な変数の組み合わせをスクリーニングし、さらに詳しい情報をみる
今回の例で示したように、多くのYやXの関係を調べるときに「応答のスクリーニング」は非常に便利です。いきなりすべての組み合わせに対して詳細なレポートを表示するのではなく、まずは、p値や対数価値などの一覧表から重要な変数の組み合わせをスクリーニングし、ドリルダウンで詳しいレポートを見ているというアプローチは理にかなっているといえるでしょう。
次回の第3回では、「工程のスクリーニング」をご紹介します。
30日間JMPの全機能を試せるトライアル版は下のリンクから!