
AIアート入門:キャラのLoraのモデルを訓練しましょう。 一時間以内にColabでできます。!!!!!!!!!!!!

皆さん Loraのモデル革命をご存知でしょうか?
AI画像作成のモデルは、素晴らしいですが、特定のキャラクターを使いこなすのは難しいです。DreamBoothのバンドは特定なキャルを訓練できますが、モデルのサイズは多くて、訓練時間もかかります。しかし、Loraのモデルを訓練したら、40分間以内で、同じ品質でより小さいサイズのモデルが手に入るので、より使い勝手がよくなります。
これは革命的なレベルの技術です。そして、訓練も難しくないです。すべてColab内で訓練できます。画像の準備とちょっとラベル作成のわずかな手作業と、ほとんどコードのない技術で、自分だけのモデルを作ることができます。今回の記事では、Loraの基本的な知識とKohtaさんの訓練ノートブックを紹介してあげます。
Loraとは
Loraの略は(Low-rank Adaptation)です。日本語で「低ランクの適応」に翻訳されます。Loraのモデルは元に言語モデルのために作れました。(下記に元の英語の論文です。そして、この数ヶ月、AIアートモデルに対して非常に有効であることが示されています。
LoRAのモデルの役割は特定のスタイル、キャラクター、機能に対するファインチューニングです。ベースモデルの特定を変えずに、新たに学習させた重みをモデルに注入します。これをすれと、訓練は早くなり、注入できるLoRAモデルのサイズは非常に小さいです。映画「マトリックス」でクングフーを習うネオのようです。新しいモデルやデータを注入して、対象話題を対応できるように
LoRAを訓練しましょう
LoRAのモデルはColab内で簡単に訓練できます。今回の記事では、Kohya LoRA Fine-Tuningのノートブックを利用しています。
作成者は日本人なので、もっと詳しいを知りたいなら、彼のGithubとNoteブログのページをご覧ください。
リンク Readme-ja.md
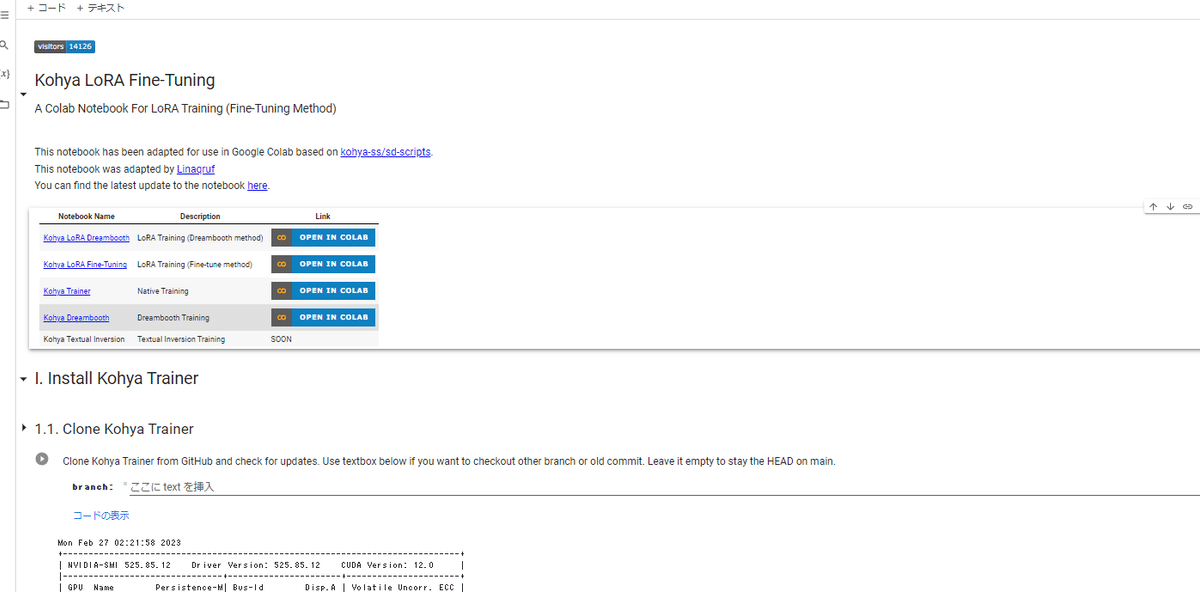
Kohyaさんのノートブックは6つの部分に分けて、今回の記事では、それぞれを紹介しながら、説明してあげます。
1 セットアップ
2 バースモデルセットアップ
3 データのセットアップ
4 画像前処理
5 訓練
6 テスト
1)セットアップ
セットアップの部分では、一つをやるべきことは、HuggingFaceのアカウント作成です。ベースのDiffusionのモデルをダウンロードするために、HuggingFaceのAPI鍵が必要です。
アカウントを作成した後で、設定(Setting)/AccessTokensに移動して、「New Token」(新しいトーケン)というボータンを押してください。これは、API鍵をコピーして、セル(1.3.1)のHuggingfaceのところで貼り付けます。

これで、すべての設定セルを実行します。
2) バースモデルセットアップ
このステップでは、ターゲット画像で微調整したいモデルをダウンロードします。SD1とSD2のモデル選択があるが、今回 SD1のモデルを選択しています。(理由、現在 ControlNetはSD1モデルのみからです)。私の対象キャラはアニメのキャラなので、Anything-v4-5prunedを選択しました。しかし、他のアニメモデルは良い選択です。このモデルを確認したいなら、HuggingFaceでこのモデルの名前を検索してください。

もしこのモデル選択以外のモデルを使いたいなら、下のセルでは、HuggingFaceからカスタムダウンロードの設定があります。HuggingFaceからモデルのリックを張り付けて、実行したら、ダウンロードしてくれます。

3) 訓練画像セットアップ
このステップは一番重要です。これは画像を準備です。私はクルミちゃんのVtuber動画から20枚のフレームを使います。
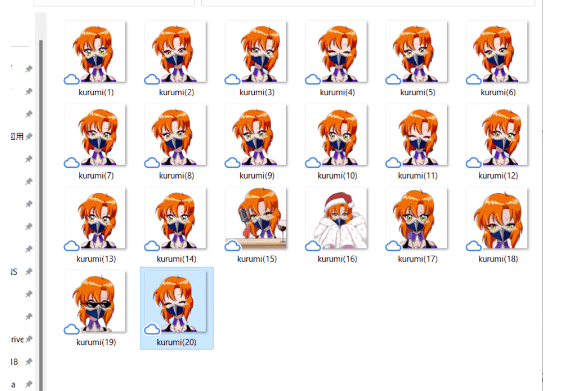
ギャルバースをお持ちの方で、ギャルを使ってローラモデルを作りたい方は、Vtuberにアップグレードしてください。
Why yes, we did finish rigging 2200 traits by hand so that the entire @galverseNFT community could make real-time animation— and I’d do it again!! #GalTubers pic.twitter.com/gVDktISwe0
— Sally Danger | Engineer (@SallyDanger) January 11, 2023
他のキャラを使いたいなら、オンランから画像を取得してください。
次はこの画像は同じのサイズに変換しなければなりません。ネットから取得したら、サイズはバラバラはずです。BIRMEというサイトは画像を一括で切り抜くことができます
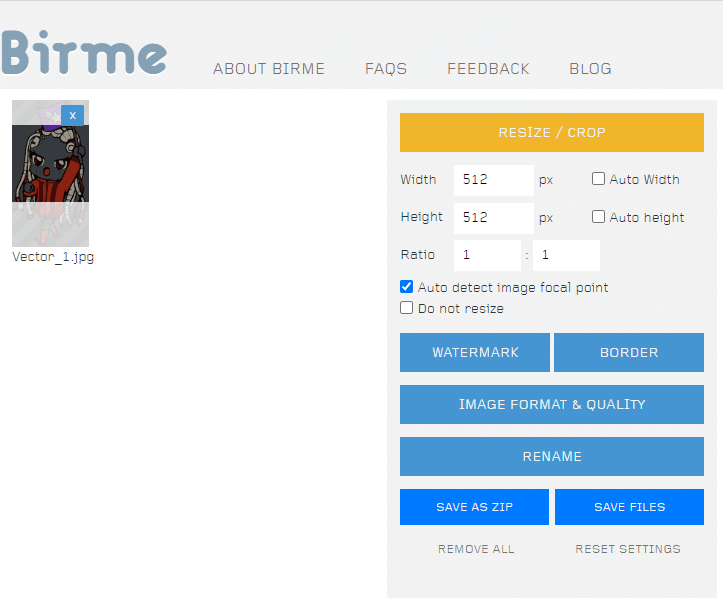
Birmeでは、ファイル名を設定できます。対象のキャラの名前を記入して、 xxx を追加して画像番号を示しています。それぞれの画像は同じファイル名の形式が必要です。
そして、もしかしたら画像は背景が目立つと、背景削除をお勧めます。Lora訓練では、対象のキャラだけ訓練したいですね。これはremove.bgの無料な背景削除のサイトではできます。
ひとつの注意点はremovebyから画像をダウンロードすると、ファイル名を変更されます。元画像の名前を上書きするか、別のフォルダに保存することをお勧めします。

20枚の画像を準備した後で、GoogleDriveでアップして、「訓練データを定義する」というセル(3,1)でパスを貼り付けて

4) 画像前処理
このステップでは、準備した画像は変換しますので、念のために別のフィルダーのコピーを作成してください。
最初の処理は、透明背景から白化とかランダムの色に変換する処理です。前のステップでは、背景削除をしたら、この範囲のピクセルがなくなったので、訓練中で問題を引き起こされるかもしれません。

念のために、このセルで白の色(255のピクセル値)に変換します。もしかしたら、背景の効果も抑えたい場合は、ランダムカラーを試してみてください。
次のセルでは、画像のサイズをアップスケールできま。もし、画像のサイズはちょっと小さくて、512x512ではない場合は、このセルを実行してください。

次に、画像のアノテーションを行います。それぞれの画像は「この画像は何ですか」を説明しているテクストファイを作成します。Koyhaノートブック内で自動的な作成の機能があります。二つのアノテーションのモデルがあります。今回 アニメ系なキャラを使うので、WaifuDiffusion1.4Taggerを使います。キャラの場合は Threshold(閾値)の設定は0.7~0.9の間に設定してください。

アノテーションを作成した後で、画像フォルダを確認してください。画像と同じ名前のテクストファイルを作成したはずです。
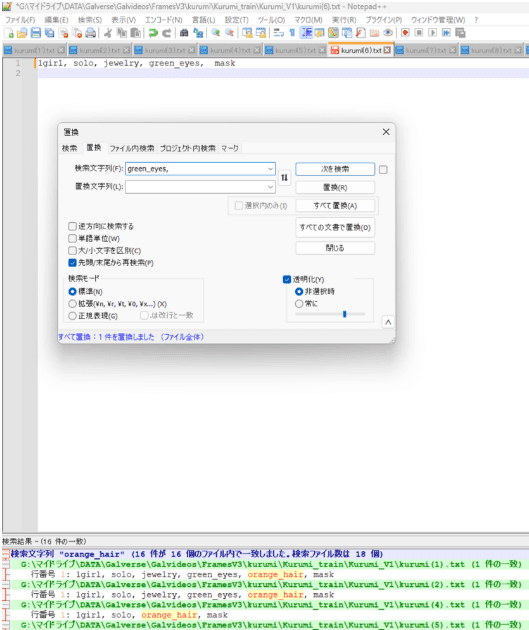
まだ終わっていないので、次はテキストファイルの整理をします。よく学習させるためには、髪や目の色のように、すべての画像に存在するタグを取り除く必要があります。例えば、クルミちゃんは緑目(Green_eyes)と赤毛(red_hair)があり、このタグを削除します。このために、Notepad++を利用することをお勧めします。すべてのファイルを開き、「ctrl+F」を押して、「置換」のタブに移動して、すべてのファイルから不要なタグを削除することができます。他の確認するべきなことは、背景色のタグがあるかどうかことです。もしランダム色の背景があったら、無意味なことを学習されたリスクがあるので、念のために、背景の色のタグを加えます。例えば、blue_background
次、Loraのモデルのために、雄一なキャラの名前を加えます。バースのモデルでは、キャラ名のタグが入ったあるかもしれませんので、区別するのに、特別な名前を加えます。ノートブック内のセル4.4.3はこれはできます。
私のキャラの場合は「kurumi_gal」のタグは最初に所に加えました。

テクストのファイルを準備した後で、次のセルでは、すべての画像とファイルは一つのJsonのファイルに保存されます。

このステップでは、自分のGoogleDriveで保存する人をお勧めます。もしかしたら、訓練中で問題があったら (接続が切れるなど)、ファイルを失うことはありません。
最後の前処理のステップは、セル4.6「Aspect Ratio Bucketing and Cache Latents」です。このステップは、訓練の時にモデルの位置と上で使ったJsonのファイルを読み込むためのファイルをセットアップするだけです。
model_dirとinput_jsonを確認し、max_resoltuonは画像を設定し、mixed_precionはfp16に変換してください。

5) Loraの訓練
すべての前処理を完了して、訓練を行いましょう。
最初にセル(5.1) 訓練の入力のファイルや出力の保存先を定義しました。
モデルとmeta_lat.json(上記のステップで作成したファイル セル4.6)のファイルと訓練のデータの保存先はここに記入してください。そして、モデルの名前は、project_nameで書けます。私は対象のキャラ名前やベースモデルと組み合わせて、project_nameとすることをお勧めします。
入力保存先(Output_dir)は自分のGoogleDrive内でパスを使ってください。

次のセル(5.2)でLoraのモデルの設定を定義します。標準な設定の大部分をそのままにしておいて、learning_rate(学習率)とtext_encoder_lr(テクストエンコーダーの学習率)は5e-5と2e-5に変換します。学

次のセルは訓練を実行します。AIモデルの訓練をしたことがある人なら、この設定に慣れているはずです。しかし、ない場合は、編集してもいい設定を紹介します。
train_batch_sizeはそれぞれの訓練ステップで何枚の画像を利用してもいいことです。この画像はGPUのラムでロードするので、ラムサイズに応じた適切な量を選択します。無料なColabの場合は、6枚がよいです。もしColabProがあったら、8枚と10枚できるかもしれません。
次はnum_epochは、訓練を何回に繰り返す設定です。私は40Epochを使います。私は40に設定しましたが、もしに早めに訓練したいなら、20前後の値でも問題ありません。
次はRAM減の設定です。
mixed_precioionとsave_preciousはfp16に設定された確認してください。設定しない場合は GPUはもっとRAMを使うので、問題を引き起こされるかもしれません。
use_8bit_adamは他のRAM減の設定です。8bit_adamはビットサイズを32ビットから8ビットに縮小したモデルの最適化関数です。これを有効したら、RAM利用と訓練時間を減らします。

私の場合、20枚の画像を40Epochで学習させるのに40分かかりました。それは非常に速いです。しかし、毎月にAIアート訓練では、大きな展開があるので、来月に遅いかもしれません (笑)。
WebUiでLoraをテストしましょう。
ノートブック内のテスト
さて、トラニングも終わり、いよいよ結果の確認です。ノートブック内でTestingのところで移動してください。
訓練のモデル結果は自分のGoogleDriveで保存するはずです。この保存先をコピーして、セル6.1に記入してください。最初のテストはモデルのファイルを読めばどうかことです。
問題ない場合は、モデルのMetaデータを表示してくれます。

次のテストは、あなたが待ち望んでいたものです。訓練されたLoraモデルとAI画像生成をしましょう。セル6.2では、テストのプロットとAI画像を作成します。

このセルでは、新しい保存先を使ってください。モデルと同じのところがよくて、テストごとに異なるサブフォルダ名を使用することをお勧めします。例えば、20230301/Kurumi06
最初のテストは、標準な設定で、自分のキャラクターのタグ追加が良いです。Promptのテストの最初のところで、キャラクターのタグを追加して、実行してください。私の場合は「Kurumi_gal」を加えました。

クルミちゃんとそっくりですね。すごいいいいいいいいいいいい
訓練されたモデルは影響を確認するために、テスト2では、network_mulの設定はゼロにして、Loraモデルを無効します。これはモデルの標準な結果を示しています。
Model: Anything-v4-5-pruned
Prompt:masterpiece, best quality, 1girl, aqua eyes, baseball cap, blonde hair, closed mouth, earrings, green background, hat, hoop earrings, jewelry, looking at viewer, short hair, simple background, solo, upper body, yellow shirt
Negative:lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry

テスト1とテスト2(Lora無効)を比べて、Loraのモデルはクルミちゃんの顔特徴と髪色ははっきり把握できました。Promptでは、髪と服色と背景を定義したので、AI画像作成の結果は多きな変化があったら、
そして、クルミちゃんがないことを気づいたでしょうか?
クルミちゃんは口がないですよ。
すべての訓練画像では、クルミちゃんはマスクををしています。そして、テクストファイルでは、マスクのタグも加えました。Loraモデルはマスクとタグをリンクさせたのでしょう。次のテストで、maskを加えます。

マスクを加えた結果はクルミっぽくなったが、髪色はPrompt内で変化せずに、クルミちゃんの特徴的な赤色の髪になれました。クルミちゃんから特徴から大きな離れが欲しければ、kurumi_galを抜け、Loraモデルの重さをヘラすればいいです。
次のテストでは、髪色を変化したり、新しい特徴を加えたりして、毎回少しずつ変えていくのも楽しいものです。それぞれのテストでは、別のフォルダで保存することを覚えてください。





テスト8に結果から、Loraの重いを上げると、Promptからちょっと離れ始めます。これらのテストから、モデルのより良い使い方を学ぶことができます。
WEBUIのテスト
ノートブック内のテスト環境は限界があります。SDのWEBのUIへ移動しましょう。Automatic1111のWEBUIに最近人気になって、Colab内で無料に実行できます。前の記事では、セットアップを説明しましたので、ぜひご覧ください。
訓練されたLoraモデルは、WEBUIに利用するために、WEBUIのLoraモデルのフィルダーに移動しなければなりません。
パス:sd/stable-diffusion-webui/models/Lora/
上記のパスに、loraのモデルを移動したら、WEBUIを開くと、読み込めます。
WebUIを開いた状態で、小さな赤いカードボタンをクリックします。これはエクストラネットワークの画面を開きます。「Textual Inversion」「Hypernetworks」「Checkpoints」「Lora」のタブがあり、今回 Loraを使うので、Loraタブに移動しましょう。移動されたモデルを見つかって、押してください。

<lora:kurumi_lora_v1_anything:1> このような文字はプロンプト内に表示されるはずです。数字の部分はモデルの重いという意味です。この数値を小さくすると、AI画像作成においてLoraモデルの影響が小さくなります。Loraのモデルをテストするために、キャラと一つの説明のタグを入れてください。私の場合は kurumi_gal , maskを加えた結果が、クルミちゃんが出されました。
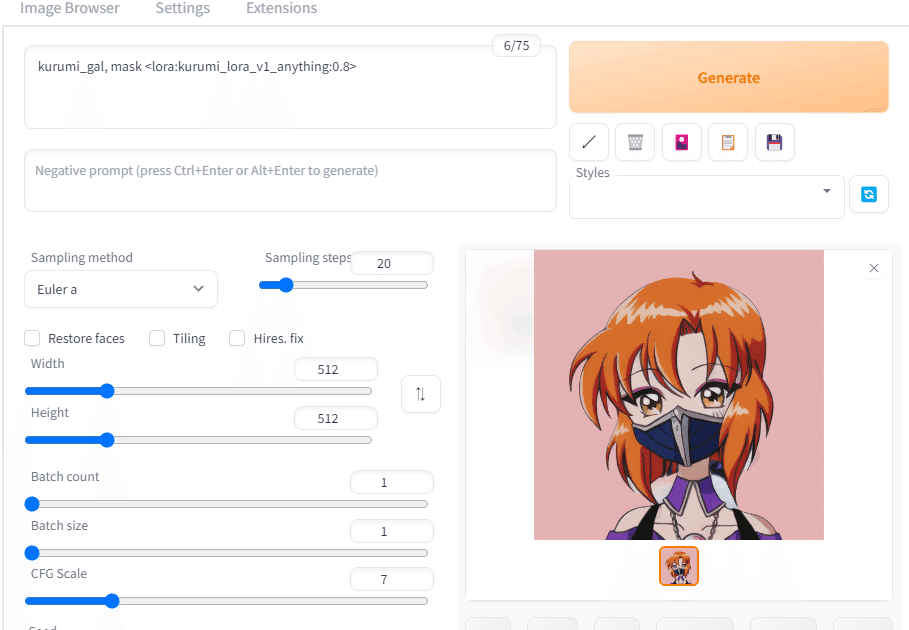
Webuiでクルミちゃんがうまくできたので、面白いキャラクターリファレンスシートを作ってみましょう。ローラーブレードがある全身のクルミちゃんを作ろう。
Prompt: Character sheet, masterpiece, best quality, 1girl, green eyes, baseball cap, ginger hair, earrings, hat, shirt, short hair, simple background,roller skates, <lora:kurumi_lora_v1_anything:0.6>
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
Steps: 20,
Sampler: Euler a,
CFG scale: 7,
Seed: 1709324676,
Size: 1024x512,
Model: anything-v4.5-pruned



結論
LoraのモデルはPrompt内でスタイルのように扱うこと必要に便利です。ともに複数のLoraモデルを利用して、たくさんな画像作成の可能性があるでしょう。しかし、AI画像作成の技術の進歩は早いです。現時点ではLoraは最も効率的なキャラやスタイルを訓練する方法ですが、いつまででしょうか?
Designing an Encoder for Fast Personalization of Text-to-Image Models
— OpenMMLab (@OpenMMLab) February 28, 2023
📌-Arxiv: https://t.co/r8CSZJ25X3
Text-to-image model can be tuned for a concept in 11 seconds on a single NVIDIA A100 GPU with just one image and 5 training iterations using E4T. pic.twitter.com/abT9azgNOA
この記事を書いている間に、Nivda研究者は11秒でスタイルとキャラ訓練の論文を発表されました。今月に次のAI画像生成の次の大きな展開があるかもしれない。しかし、今日 Lora訓練からちょっとお休みします。
この記事の情報は役に立たれなら、ぜひ結果はTwitterに共有してください。
