
LangChainを使った3つのLLM文書要約手法「Stuff, Map Reduce, Refine」を検証してみた。

こんにちは!株式会社IZAI、エンジニアチームです。
今回は、LLMのタスクとして活用の場面が多い文章要約の3つの手法「Stuff, Map Reduce, Refine」について検証して、その精度を比較していきます。
LangChainとは?
LangChainとは自然言語処理の分野で活躍を期待されているオープンソースのライブラリで、チャットボットや自動要約アプリなどのAIアプリケーションの開発タスクの自動化、簡易化をしてくれます。またLangchainの機能を用いることで、LLMの抱えるトークン制限の問題にも柔軟に対応できLLMの制限を超えた運用が可能となっています。
この利便性を利用し、最近では膨大なトークン数を要する論文や議事録の要約における文書整理の時間削減や書式の一貫した可読性の高い文章の取得に貢献しています。なので本記事では実際に文章要約に使用されているLangChainとLLMを用いた3つの手法であるstuff, map_reduce, refineについて検証していきます。
要約手法
ここからは、LangChainの公式ドキュメントにも掲載されている代表的な3つの要約手法であるstuff, map_reduce, refineに関する大まかな流れや特徴を紹介していきます。
1. stuff
stuffは文書全体をそのままLLMに渡して要約をするという手法です。この手法は難解なコードを書く必要もなく、最も手軽に試すことのできるものだといえます。しかしstuffを使用する場合投入できる文章量は使用LLMに依存するので、トークン制限に引っかかる場合があります。ですが、anthropic 社の Claude2 など 100k token 等の長い入力にも対応しているモデルの登場により最大トークン数もかなり緩和されています。

2. map_reduce
map_reduceは文章をチャンク分けしそれぞれに対して要約を適用し、最後に要約したすべての文章まとめ再度要約をするといういわゆる要約の要約をするという手法です。
この手法の長所としては要約処理を並列して実行でき後述するrefineよりも短時間で実行できます。
短所としては、分割した文章を別々に要約するため文脈や情報を見落とす可能性があります。
以下がmap_reduceの実際の実行フローです。
ドキュメントを分割する
分割したそれぞれの文章を個別に要約する
要約した文章をまとめてもう一度要約する

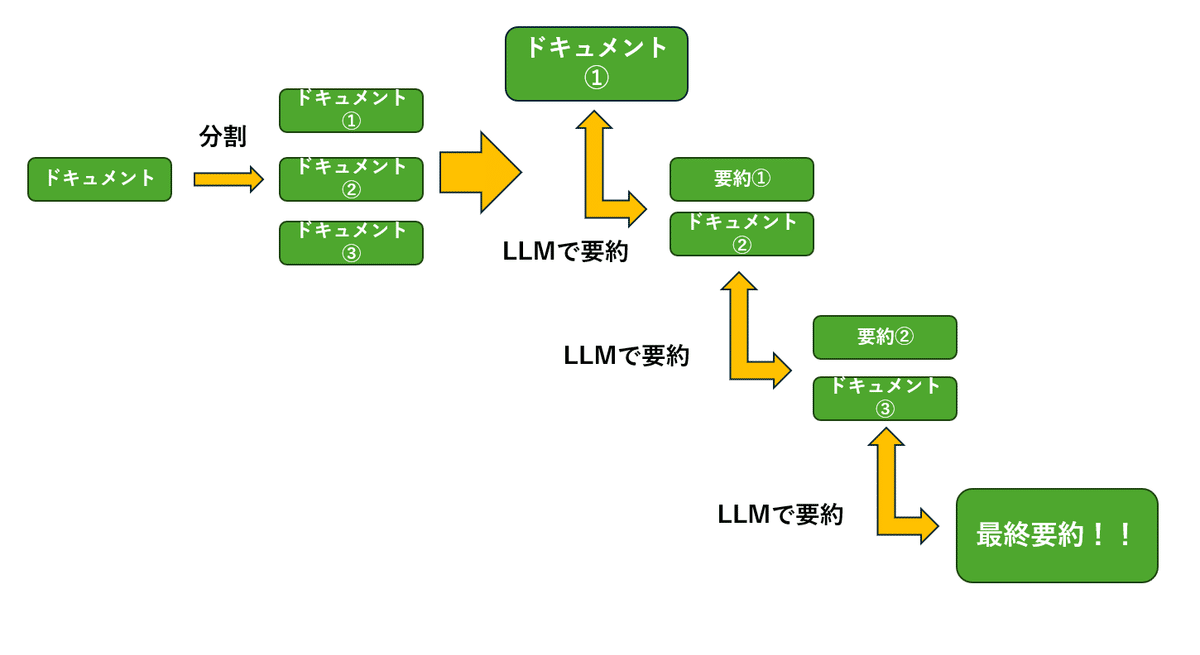
3. refine
refineは分割した文章を順番に要約処理をしていくのですが、そのときに直前に要約した文章を次に要約する文章と一緒にLLMに与えてあげます。こうすることで分割したチャンク間での文脈を損なうことなくより正確な要約をすることができます。
ですがこの手法では前の要約が終わるまで次の要約に進めないので処理の並列化ができず実行に時間がかかり、それと同時にAPI使用時のコストもほかの2つと比べてかかります。
以下がrefineの実際の実行フローです。
ドキュメントを分割する
ドキュメントを要約する
次に処理するドキュメントに直前の要約を加えて要約する
分割したドキュメントがなくなるまで繰り返す
検証方法
今回は「教育工学とインフォーマル学習」という論文を用いてそれぞれの要約を作成し、最後に元の論文に掲載されている要約と比べてみます。
また以下の設定で要約処理を行いました。
チャンクサイズ:1500
オーバーラップ:100
最終要約の長さ:300
実装
必要なライブラリ
実行に必要なライブラリをインストールします。
!pip install langchain
!pip install openai
!pip install tiktoken
!pip install PyPDF22024/07/30更新
- ライブラリのバージョンによってはlangchain-communityのインポートが必要な場合があります。
- 記事公開後にGPT-3.5-turboより安価で高性能なGPT-4o-miniが公開されました!以降そちらをお使いください。
ドキュメントの読み込み
以下のコードでPDF形式の論文を読み込み、テキストファイルに変換して出力します。
import PyPDF2
filename = '要約したいファイルのパス' #任意で変更
# PDFファイルを開く
pdf_file = open(filename, 'rb')
# PDFリーダーオブジェクトを作成
pdf_reader = PyPDF2.PdfReader(pdf_file)
# ページを繰り返し処理し、テキストを取得
text = ''
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
text += page.extract_text()
# テキストを出力
print(text)
with open('output.txt', "w") as f:
f.write(text)
# ファイルを閉じる
pdf_file.close()APIキーと使用モデルの設定
LLMの使用に必要なAPIキーと使用モデル(gpt-3.5-turbo)の設定していきます。
import os
from langchain.chat_models import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "APIキーを入力"
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, max_tokens=5000)ドキュメントの分割
設定したパラメータでドキュメントを分割します。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 100,
length_function = len,
)
with open("作成したファイルのパス") as f:
transcribe_sentence = f.read()
texts = text_splitter.split_text(transcribe_sentence)
docs = [Document(page_content=t) for t in texts]要約の実行
それぞれの手法で要約を実行します。
1.stuff
from langchain import PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
# プロンプトの定義
template = """以下の簡潔な要約を300文字の日本語で記述してください:
"{text}"
簡潔な要約:"""
PROMPT = PromptTemplate(
input_variables=["text"],
template=template,
)
# LLMチェーンの定義
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
llm_chain = LLMChain(llm=llm, prompt=PROMPT)
# StuffDocumentsChainの定義
stuff_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="text")
# 文書を要約する
print(stuff_chain.run(docs))2.map_reduce
from langchain import PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.chains.summarize import load_summarize_chain
# プロンプトの定義
template = """以下の簡潔な要約を300文字の日本語で記述してください:
"{text}"
簡潔な要約:"""
PROMPT = PromptTemplate(
input_variables=["text"],
template=template,
)
# LLMの定義
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# 文書を要約する
chain = load_summarize_chain(llm, chain_type="map_reduce", map_prompt=PROMPT, combine_prompt=PROMPT, verbose=True)
summary = chain.run(docs)3.refine
from langchain import PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.chains.summarize import load_summarize_chain
template = """次の文章の簡潔な要約を300文字の日本語で書いてください:
{text}
簡潔な日本語の要約:"""
PROMPT = PromptTemplate(template=template, input_variables=["text"])
refine_template = (
"あなたの仕事は最終的な要約を作ることです\n"
"途中までの要約があります: {existing_answer}\n"
"必要に応じて下記の文章を使い、要約の質を高めてください\n"
"------------\n"
"{text}\n"
"------------\n"
"与えられた文章を踏まえて、日本語で要約を改善してください"
"与えられた文章が有用でない場合、途中までの文章を返してください"
"最終的な要約の文章は300文字以内に収めてください\n"
)
refine_prompt = PromptTemplate(
input_variables=["existing_answer", "text"],
template=refine_template,
)
# LLMの定義
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# 文書を要約する
chain = load_summarize_chain(llm, chain_type="refine", question_prompt=PROMPT, refine_prompt=refine_prompt, verbose=True)
chain.run(docs)
結果
論文に掲載されているAbstract
情報化の進展により,学校教育外の学習機会が増加している.本論文では学校教育外の学習機
会についてインフォーマル学習に関連する概念を整理した上で,教育工学会誌にこの10年間で掲
載されたインフォーマル学習に関する研究の動向をまとめた.その結果,生涯教育施設でのイン
フォーマル学習・職場や仕事に関するインフォーマル学習・大学の課外活動におけるインフォー
マル学習・ワークショップとインフォーマル学習・その他の領域のインフォーマル学習・インフ
ォーマル学習の方法開発の6領域にわたる研究が行われていることが明らかになった.これらの
既存の研究の課題をもとに本特集号の論文の位置づけを解説し,今後の展望について述べた.1.stuff
日本教育工学会誌に掲載された論文では、インフォーマル学習に関する研究動向がまとめられている。
インフォーマル学習は、学校教育外の学習機会を指し、生涯教育施設や職場、大学の課外活動などで
行われている。研究では、インフォーマル学習の方法開発や実践を支援するための新しい教育方法が
提案されており、オンライン学習やソーシャルメディアを活用した学習環境の拡大が期待されている。
さらに、フォーマル学習とインフォーマル学習を組み合わせたブレンド型学習や越境的な学習環境の
構築が重要視されており、教育工学の研究が今後ますます発展していくことが期待されている。2.map_reduce
本論文は、情報化により学校外での学習機会が増加している状況を踏まえ、インフォーマル学習に
関する研究動向をまとめたものである。インフォーマル学習は生涯教育施設や職場、大学の課外活動
など様々な領域で行われており、教育工学との関係や課題についても考察されている。
研究内容は生涯教育施設や職場、大学の課外活動などの6つのカテゴリーに分類され、学習環境や
方法の改善に貢献している。また、アカデミックライティングの指導やグループ・カウンセリング
におけるロボットの活用、そしてロールプレイにおける人形劇の効果についても検討され、
オンライン学習環境の発展が未来の学習社会に革新をもたらす可能性が示唆されている。3.refine
本論文では、インフォーマル学習に関する研究動向や生涯教育施設、職場、大学でのインフォーマル学習
について解説されています。さらに、MQOCやソーシャルメディアを活用したインフォーマル学習の重要性
が示され、ブレンド型学習やフォーマル学習との連携による学習環境の構築も重要視されています。
オンライン学習の拡大や越境的な学習環境の構築が容易になると予想され、教育工学の研究を通じて
未来の学習社会の基盤につながる革新的な研究が期待されています。反転授業などの多様な学習形態が
構想され、学校内外の学習を再構成することで成績の向上や落第率の低下などの成果が得られていること
が示唆されています。すべての要約において、文字数制限300文字という設定を守りながら実行してくれました。元の論文の要約と比較すると、map_reduceで作成した要約が一番近似性が高い印象を受けましたが、stuff, refineの二つの手法も一つの話題だけを掘り下げることなく、要点から均等に情報を抽出できています。
考察
結果としてこの手法が一番優れているという明確な回答は得られませんでしたが、処理時間に関しては処理の並列化の有無の差が顕著に表れ、
stuffが実行後数秒で出力が得られたのに対しmap_reduceは約1分、refineは約2分となりました。今回使用した論文のトークン数は約15,000程だったためそこまで大きな違いは出ませんでしたが、大規模な文書を扱う場合は処理時間も要約手法を選択する上で重要な要因となりそうです。
また、チャンクサイズやオーバーラップ等のパラメータ設定次第で出力結果が大きく変化するので、実際にこれらの手法の使用を検討する際は慎重にパラメータやプロンプトを設定し比較しながらユースケースに合ったものを選ぶ必要がありそうです。
まとめ
今回はLLMとLangChainを用いた要約手法であるstuff, map_reduce, refineを紹介、検証していきました。
stuff: 最も手軽に要約処理ができる。高速。低コスト。
map_reduce: 文書の分割、処理の並列化によって大規模なテキストを高速で処理してくれる。高速。
refine: は順番に処理を行うことによってより正確な要約を可能にします。低速。高コスト。
以上、参考になった方はいいね、コメントをいただけると今後の開発の励みになります。それではまた!
参考文献
[1] 生成モデル(LLM)を用いた論文要約システムの構築~セキュリティ領域の論文の情報抽出を効率化してみた~
[2] LLM で長文から構造化データを抽出する
[3] LangChainとは?概要・代表的な機能(モジュール)・使い方を紹介
[4] LangChainとOpenAIを使用して大規模なドキュメントを要約する方法
[5] LangChainのSummarizationサンプルノートブックのウォークスルー
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?