
GoogleのSpeech-to-Text APIでマイクを使ったリアルタイム文字起こしを試す方法【GCP入門】 #Python #PyAudio

こんにちは。IZAIエンジニアチームです。
今回はGCP初学者向けに日本語文字起こし精度が最も高いAPIの1つであるGoogle CloudのSpeech-to-Text APIを使用する手順を簡単に紹介します。
手順
ほとんど全てのコードはGCP公式ドキュメントに公開されています。
今回はこのサンプルコードをサービスアカウントを作成して動作させてみましょう。

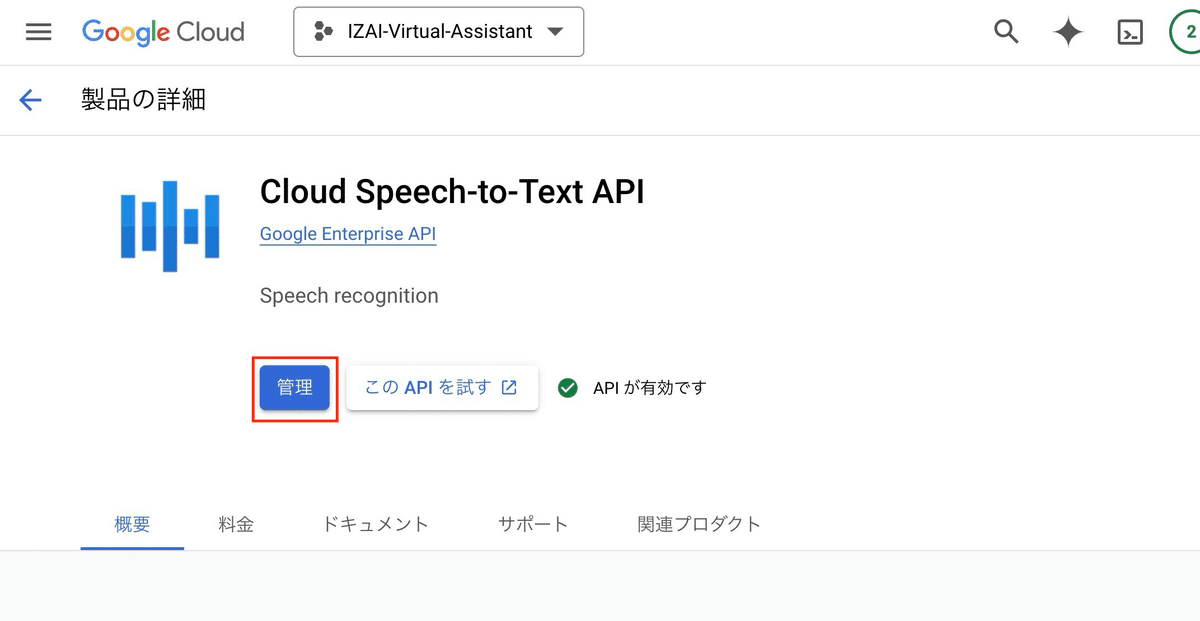
1. Cloud Speech-to-Text APIを有効化
コンソールから、「Cloud Speech-to-Text API」を検索。有効化→[管理]をクリック
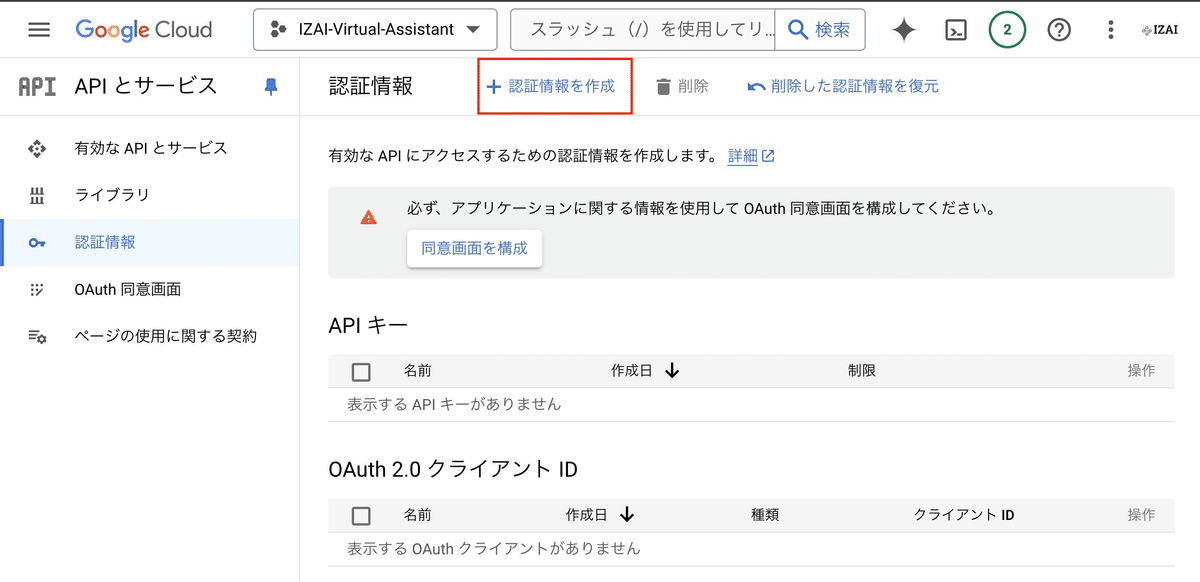
2. サービスアカウントを作成
[認証情報を作成] > [サービスアカウントを作成]
任意のアカウント名を設定して[完了]をクリック
(Speech-to-Textのロールが既に設定済みなのでロールの追加はスキップしてください)
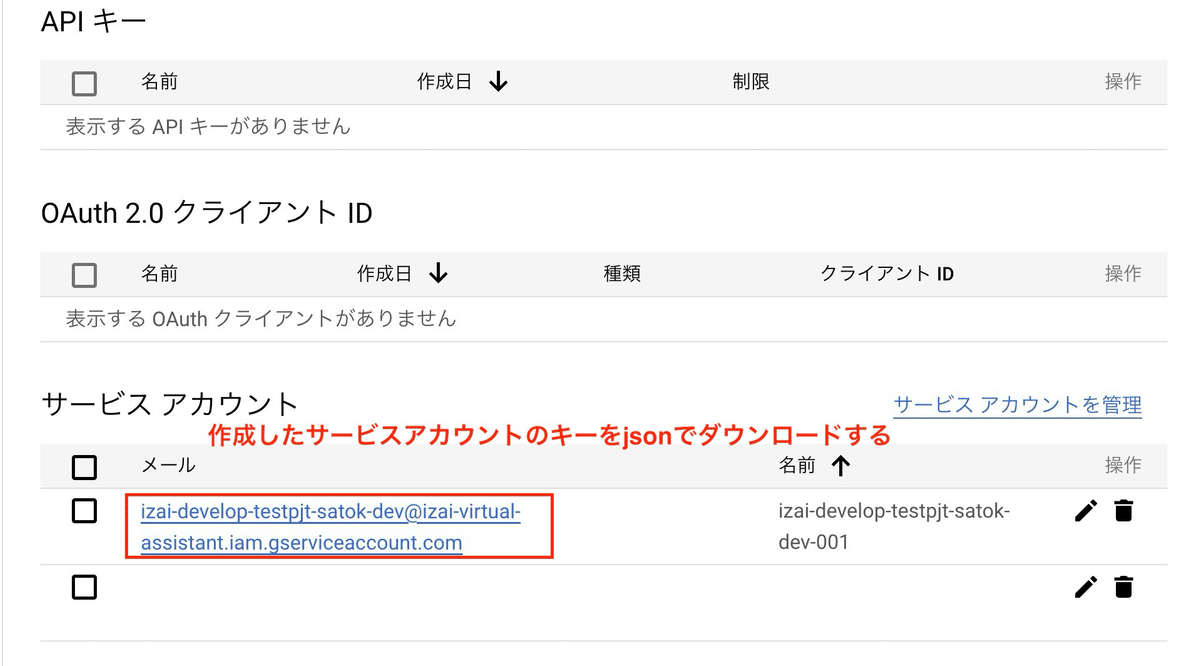
3. サービスアカウントのキーを取得
作成したサービスアカウントを選択して > [キー] > [鍵を追加] > [新しい鍵を作成]からJSON形式のキーを作成してください
4. キーを環境変数に設定して実行
公式ドキュメントのサンプルコードに加えて、先ほど作成したキーを環境変数に設定して、言語を日本語にすると完成です。
## ライブラリをインストール
pip install pyaudio google-cloud-speech six## 公式サンプルコード + 環境変数、日本語化
from __future__ import division
import re
import sys
import os
from google.cloud import speech
import pyaudio
from six.moves import queue
# Google Cloud認証情報のパスを環境変数として設定
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "credentials.json"
# Audio recording parameters
RATE = 16000
CHUNK = int(RATE / 10) # 100ms
class MicrophoneStream(object):
"""Opens a recording stream as a generator yielding the audio chunks."""
def __init__(self, rate, chunk):
self._rate = rate
self._chunk = chunk
# Create a thread-safe buffer of audio data
self._buff = queue.Queue()
self.closed = True
def __enter__(self):
self._audio_interface = pyaudio.PyAudio()
self._audio_stream = self._audio_interface.open(
format=pyaudio.paInt16,
# The API currently only supports 1-channel (mono) audio
# https://goo.gl/z757pE
channels=1,
rate=self._rate,
input=True,
frames_per_buffer=self._chunk,
# Run the audio stream asynchronously to fill the buffer object.
# This is necessary so that the input device's buffer doesn't
# overflow while the calling thread makes network requests, etc.
stream_callback=self._fill_buffer,
)
self.closed = False
return self
def __exit__(self, type, value, traceback):
self._audio_stream.stop_stream()
self._audio_stream.close()
self.closed = True
# Signal the generator to terminate so that the client's
# streaming_recognize method will not block the process termination.
self._buff.put(None)
self._audio_interface.terminate()
def _fill_buffer(self, in_data, frame_count, time_info, status_flags):
"""Continuously collect data from the audio stream, into the buffer."""
self._buff.put(in_data)
return None, pyaudio.paContinue
def generator(self):
while not self.closed:
# Use a blocking get() to ensure there's at least one chunk of
# data, and stop iteration if the chunk is None, indicating the
# end of the audio stream.
chunk = self._buff.get()
if chunk is None:
return
data = [chunk]
# Now consume whatever other data's still buffered.
while True:
try:
chunk = self._buff.get(block=False)
if chunk is None:
return
data.append(chunk)
except queue.Empty:
break
yield b"".join(data)
def listen_print_loop(responses):
"""Iterates through server responses and prints them.
The responses passed is a generator that will block until a response
is provided by the server.
Each response may contain multiple results, and each result may contain
multiple alternatives; for details, see https://goo.gl/tjCPAU. Here we
print only the transcription for the top alternative of the top result.
In this case, responses are provided for interim results as well. If the
response is an interim one, print a line feed at the end of it, to allow
the next result to overwrite it, until the response is a final one. For the
final one, print a newline to preserve the finalized transcription.
"""
num_chars_printed = 0
for response in responses:
if not response.results:
continue
# The `results` list is consecutive. For streaming, we only care about
# the first result being considered, since once it's `is_final`, it
# moves on to considering the next utterance.
result = response.results[0]
if not result.alternatives:
continue
# Display the transcription of the top alternative.
transcript = result.alternatives[0].transcript
# Display interim results, but with a carriage return at the end of the
# line, so subsequent lines will overwrite them.
#
# If the previous result was longer than this one, we need to print
# some extra spaces to overwrite the previous result
overwrite_chars = " " * (num_chars_printed - len(transcript))
if not result.is_final:
sys.stdout.write(transcript + overwrite_chars + "\r")
sys.stdout.flush()
num_chars_printed = len(transcript)
else:
print(transcript + overwrite_chars)
# Exit recognition if any of the transcribed phrases could be
# one of our keywords.
if re.search(r"\b(exit|quit)\b", transcript, re.I):
print("Exiting..")
break
num_chars_printed = 0
def main():
# See http://g.co/cloud/speech/docs/languages
# for a list of supported languages.
language_code = "ja-JP" # a BCP-47 language tag
client = speech.SpeechClient()
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=RATE,
language_code=language_code,
)
streaming_config = speech.StreamingRecognitionConfig(
config=config, interim_results=True
)
with MicrophoneStream(RATE, CHUNK) as stream:
audio_generator = stream.generator()
requests = (
speech.StreamingRecognizeRequest(audio_content=content)
for content in audio_generator
)
responses = client.streaming_recognize(streaming_config, requests)
# Now, put the transcription responses to use.
listen_print_loop(responses)
if __name__ == "__main__":
main()完了
リアルタイムで文字起こしできるようになりました。
さすがGoogle、声が遠くても、ノイズが入っても、正しく文字起こしできていますね
GCP入門の第一歩として、ぜひお試しください
役に立った/参考になった方はいいねをいただけると、今後の解説の励みになります。それではまた!