ポケカのカード検索サイト作成①データ収集編

トレーナーズウェブサイトのカード検索が使いにくいので、自分が使えるカード検索サイトを作成しました(著作権の関係上、第三者への公開はしません)。せっかくなので、具体的にどんなことをしたか書いていきます。
初めに、要件定義としては
・外出先でも使いたいためwebブラウザ上で操作
・スタンダードレギュレーションのカードのみ
・テキストで結果を表示
を考えているため、完成までの大まかな手順は
①トレーナーズウェブサイトのカード詳細ページから必要な情報を取得する
②取得したデータをデータベースに入れやすいように整え、データを入れる
③画面操作用のhtmlファイル、動的コンテンツとして動作させるためのCGI等を作成してリモートサーバーにデプロイし、完成
となっています。この記事では、①のデータ収集について書いていきます。
例えば、ミュウツー(smE)のカード詳細ページは画像のようになっています。
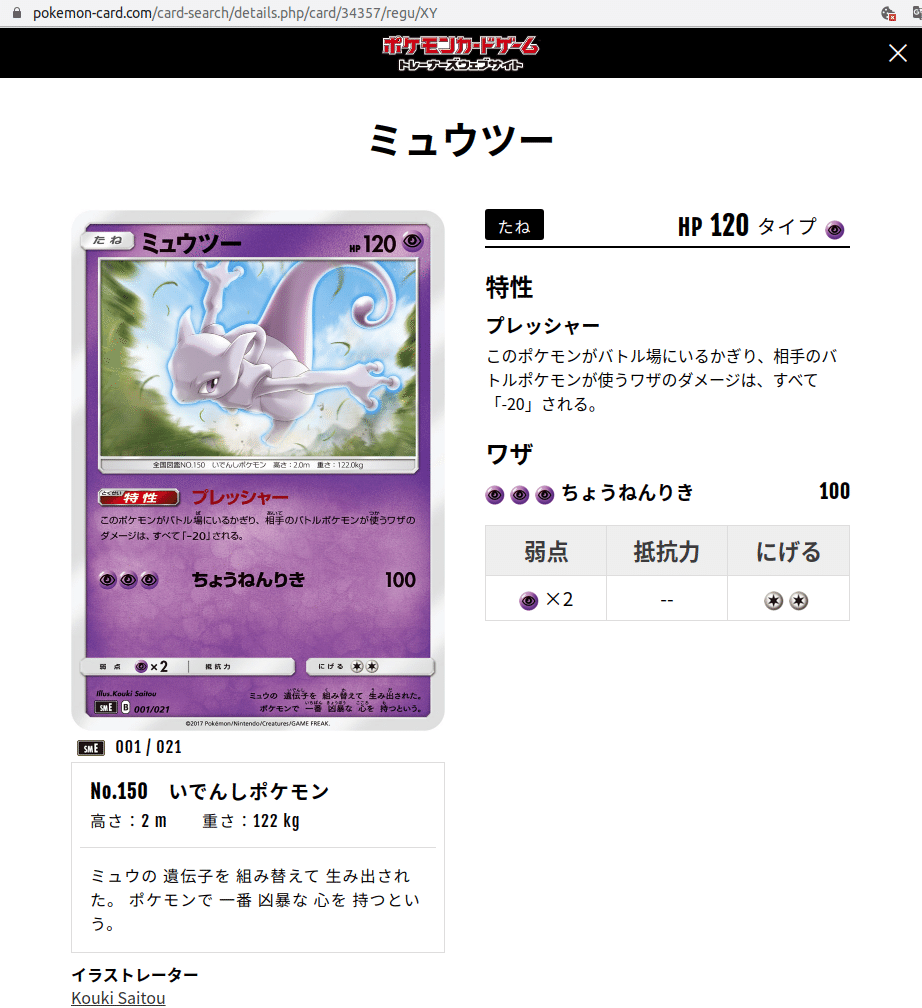
このページから、'ミュウツー'というカード名やHP、特性の名前と効果といったものを抜き出すのに、Beautiful Soupを用いたhtmlタグ抽出を行いました。
ここでどんなことをしているかというと、この詳細ページを開いているときにDeveloper Toolを開くと(ChromeだとF12キーを押す)、画像のような画面が出ます。

このDevTool内ではhtmlタグの構造が確認できて、例えば'ミュウツー'というカード名は<h1 class="Headingl mt20>というタグ内のテキストであることがわかります。
こうして必要な情報のhtmlタグ構造を確認すると、Beautiful Soupでh1タグのテキストをカード名として取得、といったことができます。
こうして取得した結果と、後の処理で必要になりそうな情報をテキストファイルに出力していくと、画像のようなものが得られます。

次の工程では、1行ずつテキストファイルの内容を読み込んで整理しようと考えており、特性やわざの効果文や、ワザを使用するのに必要なエネルギーはカードによって複数行あるため、どこからどこまでがこれらの内容か判別できるように、begin_energyといったテキストを挿入し、カード1枚の終わりに / を入れました。
こうしてカードの情報が集まったので、次はデータを整理していきます。