
OpenAI o1の開発者がo1の仕組みなどについて語るインタビュー(日本語訳と感想)

OpenAIの新推論モデルのo1シリーズを開発したノーム・ブラウン博士らのインタビュー動画を見つけたので、その内容を日本語訳して紹介します。
このインタビュー動画は、ベンチャーキャピタルのSequoia CapitalがYouTubeチャンネルで配信しているものです。
3人の開発者の紹介
Noam Brown
ノーム・ブラウンは、OpenAIのリサーチ・サイエンティストであり、特に多段階推論や複雑な問題解決の分野で重要な役割を果たしています。彼は、OpenAIのo1モデルの開発において中心的な役割を担いました。
OpenAIに参加する以前、ブラウン博士はMeta(旧Facebook)のFAIR研究所でCICEROというAIを開発し、戦略ゲーム「Diplomacy」で人間レベルのパフォーマンスを達成しました。また、ノーリミットポーカーでトップの人間プロを打ち負かしたAIの「Libratus」や「Pluribus」の開発にも貢献し、その結果、強化学習と戦略的推論の分野で彼の専門知識が高く評価されました。
ブラウン博士は、特に「チェイン・オブ・ソート(chain-of-thought)」推論を使ったo1モデルの開発において注目されています。この方法は、複雑な問題を小さなステップに分けて解決し、解を確認するプロセスで、数学やコーディングの分野で特に強力です。彼は、o1モデルが以前のAIモデルとは異なり、解を出す前により長い時間をかけて考える設計になっている点を強調しています。
ブラウン博士は、カーネギーメロン大学でコンピュータサイエンスの博士号を取得しており、AIやアルゴリズム取引の研究を経て、現在の多エージェントAI研究に従事しています。
Hunter Lightman
ハンター・ライトマン博士は、OpenAIの研究者であり、技術スタッフのメンバーとして、大規模言語モデルの推論能力向上に貢献しています。彼の主な功績の一つは、複雑なステップごとの問題解決におけるAIの推論能力を向上させる「プロセス監督(Process Supervision)」の開発です。この手法は、従来の結果ベースの監督方法よりも優れたパフォーマンスを発揮し、特に数学的問題を解決する際の信頼性と解釈可能性を大幅に向上させることが示されています。
OpenAIに参加する前、ライトマン博士は自動運転車業界で働いており、Nuroというロボティクス企業でデータインフラストラクチャを構築し、自動配送車両の開発に携わっていました。現在は、OpenAIで「o1モデル」の開発に取り組んでおり、強化学習などの高度な技術を適用して、AIの長期的で論理的な思考能力を向上させています。
ライトマン博士の研究は、AIが人間のような思考プロセスを辿り、信頼性が高く解釈可能な結果を提供できるようにするため、AI推論能力の向上に重要な役割を果たしています。
Ilge Akkaya
イルゲ・アッカヤ博士は、OpenAIの技術スタッフであり、プログラム合成や推論システムの開発に携わっています。彼女はo1モデルが複雑な推論タスクを実行できるようにするための開発に貢献しました。OpenAIに参加する前は、ロボティクスやマルチエージェントAIシステムに取り組んでおり、ルービックキューブをロボットで解くプロジェクトなどに関与していました。カリフォルニア大学バークレー校で博士号を取得しており、サイバーフィジカルシステム向けの機械学習フレームワークを開発しました。
要約
ノーム・ブラウン、ハンター・ライトマン、イルゲ・アッカヤはOpenAIの研究者で、プロジェクト・ストロベリーに取り組みました。このプロジェクトは、OpenAIが初めて本格的に取り組んだ汎用推論時計算であるo1の開発につながりました。このエピソードで彼らは、o1の推論能力の重要性とそれがAIの未来にとって何を意味するかについて話しています。
より長く「考える」ことで、モデルはより複雑な問題に取り組めるようになります。 o1は機械知能の大きな進歩を表しており、推論時計算とLLMを組み合わせて汎用AI推論能力を生み出しています。
o1は人間が解釈可能な「思考の連鎖」を使って問題を枠組みし、探索します。 このモデルは、より長く考える時間を与えられると、バックトラッキングや自己修正といった新たな能力を示します。これらは以前は言語モデルで実現が困難だった能力です。これにより、問題に新しい方法でアプローチでき、時にはOpenAIの研究者を驚かせることもあります。
o1はSTEM分野で特に強みを発揮し、数学やコーディングタスクで以前のモデルを上回る性能を示しています。 場合によっては、AIがこれまで解けなかった数学の証明を解決し、数学者や科学者の研究アシスタントとしての可能性を示唆しています。
o1で発見された推論時スケーリング則は、AI能力を向上させる新たな次元を示唆しています。 GPTモデルは、モデルサイズと訓練データを増やすだけで着実に進歩してきました。訓練時と推論時の計算を組み合わせることで、AIの性能の上限が以前考えられていたよりも高い可能性があることを示しています。
多くの分野で印象的ですが、o1にはまだ限界があります。 研究者たちは、すべてのタスクで人間や以前のモデルよりも普遍的に優れているわけではないことを強調しています。開発者やユーザーが新しい応用を発見し、可能性の境界を押し広げることを彼らは心待ちにしています。
チームはo1を人工汎用知能(AGI)に向けた重要なステップと見ています。 前進への道筋はまだ不明確であることを認めていますが、このアプローチを繰り返し改良し、将来のバージョンでさらに強力な推論能力を実現することに興奮しています。
タイムスタンプ
o1への確信 (1:33)
o1の仕組み (4:24)
推論とは何か? (5:04)
ゲームプレイからの教訓 (7:02)
生成 vs 検証 (9:14)
o1について今のところ驚いていること (10:31)
幻滅の谷 (11:37)
深層強化学習の適用 (14:03)
o1のAlphaGoモーメント? (14:45)
アハ体験 (17:38)
なぜo1はSTEMが得意なのか? (21:10)
人文科学で優れるには何が必要か? (22:30)
能力 vs 有用性 (24:10)
AGIの定義 (25:29)
推論の重要性 (26:13)
思考の連鎖 (28:39)
推論時スケーリング則の意味 (30:41)
長期的な思考 (31:53)
テストタイム計算のスケーリングのボトルネック (35:10)
o1について最大の誤解は? (38:46)
o1への批判について? (40:10)
o1-mini (41:13)
創業者はo1をどう考えるべきか? (42:15)
o1について見過ごされていること (43:13)
OpenAI's Noam Brown, Ilge Akkaya and Hunter Lightman on o1 and Teaching LLMs to Reason Better
(OpenAIのノーム・ブラウン、イルゲ・アッカヤ、ハンター・ライトマンが語るo1とLLMにより良い推論を教えること)
ホスト:ソニア・ホワンとパット・グレイディ(Sequoia Capital)
(インタビュー動画冒頭のスポットライト部分)
ノーム・ブラウン: 推論について考える1つの方法は、より長く考えることで利益を得られる問題があるということです。人間のシステム1とシステム2の思考という古典的な概念がありますね。システム1はより自動的で本能的な反応で、システム2はより遅く、プロセス主導の反応です。そして、いくつかのタスクでは、より長く考える時間は本当に役に立ちません。例えば、ブータンの首都は何かと聞かれても、2年間考えたところで、より高い精度で正解にたどり着くことはできないでしょう。
パット・グレイディ: ブータンの首都は何ですか?
ノーム・ブラウン: 実は知りません。[笑] しかし、より長く考えることで明らかに利益がある問題もあります。私がよく挙げる古典的な例は数独パズルです。理論的には、数独パズルの解答の可能性をたくさん試していけば、正解を見つけるのは非常に簡単です。つまり、理論上は、パズルを解くのに膨大な時間があれば、最終的には解けるはずです。
ソーニャ・ホアン: 本日はノーム、ハンター、イルゲをお迎えしました。3人はOpenAIのプロジェクト・ストロベリー、別名o1の研究者です。o1はOpenAIが初めて本格的に取り組んだ汎用推論時計算で、推論、思考連鎖、推論時スケーリング則などについてチームと話し合うのを楽しみにしています。
o1への確信
ソーニャ・ホアン: イルゲ、ハンター、ノーム、お越しいただきありがとうございます。そしてo1の公開おめでとうございます。まず伺いたいのですが、これがうまくいくという確信は最初からありましたか?
ノーム・ブラウン: この方向性に何か有望なものがあるという確信はあったと思いますが、実際にここに至る道筋は決して明確ではありませんでした。o1を見てみると、これは一夜にしてできたものではありません。実際、何年もの研究が投入されており、その研究の多くは実際には実を結びませんでした。しかし、OpenAIとリーダーシップの多くは、この方向性で何かがうまくいくはずだという確信を持っており、初期の挫折にもかかわらず投資を続けてくれました。そして最終的にそれは報われたと思います。
ハンター・ライトマン: 私は最初からノームほどの確信は持っていませんでした。言語モデルを見つめ、数学やその他の推論を教えようとしてきましたが、研究には浮き沈みがあります - 時にはうまくいき、時にはうまくいかない。ここで追求している手法が機能し始めたのを見たとき、多くの人にとって、私も含めて、一種のアハ体験だったと思います。問題解決に異なるアプローチをとるモデルの出力を読み始めたとき、私にとってはそれが確信が芽生えた瞬間でした。OpenAIは一般的に非常に経験的でデータ主導のアプローチをとっています。データが語り始め、データが意味を成し始め、傾向が一致し始め、追求したいものが見えてきたとき、私たちはそれを追求します。私にとっては、それが本当に確信が芽生えた時でした。
ソーニャ・ホアン: イルゲはどうですか? OpenAIに長くいらっしゃいますね。
イルゲ・アッカヤ: はい、5年半です。
ソーニャ・ホアン: 5年半。どう思われましたか? このアプローチがうまくいくという確信は最初からありましたか?
イルゲ・アッカヤ: いいえ、AGIへの道筋について、入社以来何度か間違っていました。当初は - まあ、私は当初ロボット工学が前進への道だと考えていました。そのためにまずロボット工学チームに加わりました。実体のあるAI、AGI、そこに向かうと考えていました。しかし、そう、物事は行き詰まりました。ここでの時間を振り返ると、Chat GPT - まあ、今では当たり前のことですが - それはパラダイムシフトでした。世界中の人々と広く共有できる普遍的なインターフェースを作ることができました。そして今、この推論のパラダイムを押し進める可能性のある新しい道筋ができたことをうれしく思います。しかし、そう、長い間私には全く明らかではありませんでした。
o1の仕組み
パット・グレイディ: 非常に正当な理由から、公に言えることには限りがあることは理解していますが、どのように機能するかについて、一般的な用語でも構いませんので、共有できることはありますか?
イルゲ・アッカヤ: o1モデルシリーズは、思考できるように、あるいは推論と呼んでもいいかもしれませんが、RLで訓練されています。これはLLMで私たちが慣れているものとは根本的に異なります。そして、最近共有したように、多くの異なる推論領域にも本当に一般化されているのを見ています。ですので、このモデルファミリーによる新しいパラダイムシフトにとてもわくわくしています。
推論とは何か?
パット・グレイディ: 今日の言語モデルの最先端にあまり詳しくない人々のために、推論とは何でしょうか? 推論をどのように定義しますか? そしてなぜそれが重要なのか、簡単に教えていただけますか?
ノーム・ブラウン: 良い質問です。推論について考える1つの方法は、より長く考えることで利益を得られる問題があるということだと思います。人間のシステム1とシステム2の思考という古典的な概念がありますね。システム1はより自動的で本能的な反応で、システム2はより遅く、プロセス主導の反応です。そして、いくつかのタスクでは、より長く考える時間は本当に役に立ちません。例えば、ブータンの首都は何かと聞かれても、2年間考えたところで、より高い精度で正解にたどり着くことはできないでしょう。
パット・グレイディ: ブータンの首都は何ですか?
ノーム・ブラウン: 実は知りません。[笑] しかし、より長く考えることで明らかに利益がある問題もあります。私がよく挙げる古典的な例は数独パズルです。理論的には、数独パズルの解答の可能性をたくさん試していけば、正解を見つけるのは非常に簡単です。つまり、理論上は、パズルを解くのに膨大な時間があれば、最終的には解けるはずです。
これが私が考える - AIコミュニティの多くの人々が推論について異なる定義を持っていて、これが正統的なものだと主張しているわけではありません。誰もが自分の意見を持っていると思いますが、私はより多くの選択肢を検討し、より長く考えることで利益が得られる種類の問題だと考えています。生成器と検証器のギャップと呼んでもいいかもしれません。正しい解を生成するのは非常に難しいけれど、正解を認識するのははるかに簡単だという。すべての問題は、生成に比べて検証がとても簡単な数独パズルのようなものから、ブータンの首都を挙げるのと同じくらい検証が難しいものまで、スペクトル上に存在すると思います。
ゲームプレイからの教訓
ソーニャ・ホアン: AlphaGoとノームのバックグラウンド、ポーカーやその他のゲームで多くの素晴らしい仕事をしてきたことについて聞きたいと思います。ゲームプレイからの教訓は、o1で皆さんが行ったことにどの程度類似していますか? そしてどのように異なりますか?
ノーム・ブラウン: o1について本当にクールだと思うのは、より長く考えることで明らかに利益を得られるということです。過去の多くのAIのブレークスルーを振り返ってみると、AlphaGoが典型的な例だと思いますが、ボットについて本当に注目すべきだったのは、当時はあまり評価されていませんでしたが、行動を起こす前に非常に長い時間考えていたということです。1手を打つのに30秒かかっていて、即座に行動させようとすると、実際にはトップの人間より明らかに劣っていました。つまり、その余分な思考時間から大きな利益を得ていたのは明らかです。
問題は、その余分な思考時間に行っていたのがモンテカルロ木探索で、これは碁にはうまく機能する特定の形式の推論ですが、例えば私の初期の研究対象だったポーカーのようなゲームでは機能しません。ですので、より長く考えるための、推論するための多くの方法は、その背後にあるニューラルネット、AIのシステム1の部分が非常に一般的であっても、依然として特定のドメインに特化していました。o1について本当にクールだと思うのは、それが非常に一般的だということです。より長く考える方法は実際にかなり一般的で、多くの異なるドメインに使用できます。そして、ユーザーに提供して、彼らが何ができるかを見ることで、それを確認しています。
ハンター・ライトマン: 言語モデルについて私にとって常に本当に魅力的だったのは、これは何も新しいことではありませんが、そのインターフェースがテキストインターフェースであるため、あらゆる種類の問題に適応できるということです。ですので、私たちにとってこの瞬間が興奮するのは、この一般的なインターフェースで何かを行う方法、つまりこの一般的なインターフェースで強化学習を行う方法があると考えているからで、それがどこにつながるかを見るのが楽しみです。
生成 vs 検証
パット・グレイディ: それに関連して質問があります。生成と検証のギャップについて言及されましたが、物事を検証する容易さにはスペクトルがあります。そのスペクトルのさまざまな点で推論の方法は一貫していますか? それともそのスペクトルのさまざまな点に適用される異なる方法がありますか?
ハンター・ライトマン: このリリースで私が楽しみにしていたことの1つは、o1を多くの新しい人々の手に渡し、それがどのように機能するか、どのような問題が得意で、どのような問題が苦手かを見ることでした。これは、OpenAIの反復的な展開戦略の核心だと思います。私たちが構築した技術、開発した研究を世界に出して、世界がそれとどのように相互作用するか、私たち自身が常に完全に理解していないかもしれない種類のものを見るために、安全に行います。ですので、私たちのアプローチの限界について考えるとき、Twitterが何ができて何ができないかを示すのを見るのは本当に啓発的でした。世界にとって啓発的であり、これらの新しいツールが何に役立つかを皆が理解するのに役立つことを願っています。そして、私たちがその情報を取り戻して、私たちのプロセス、研究、製品をより良く理解するために効果的に使用できることも願っています。
o1について今のところ驚いていること
パット・グレイディ: それに関連して、Twitterの世界で見たもので、特に驚いたことはありますか? 予想していなかったo1の使用方法を人々が発見したものなど。
イルゲ・アッカヤ: 私がとてもワクワクしていることが1つあります。多くの医師や研究者がモデルをブレインストーミングのパートナーとして使用しているのを見ました。彼らが話しているのは、何年も癌研究に携わってきて、遺伝子発見や遺伝子療法のような応用について、これらのアイデアをモデルに投げかけていて、モデルから本当に新しい研究の方向性を得ることができるということです。明らかに、モデル自体が研究を行うことはできませんが、この点で人間と非常に良い協力者になることができます。ですので、モデルがこの科学的な道筋を前進させるのを見るのがとてもワクワクします。それは私たちのチームでやっていることではありませんが、世界で見たいと思っていることです - 私たちの領域外で、このモデルから本当の恩恵を受ける領域です。
幻滅の谷
ソーニャ・ホアン: ノーム、深層強化学習が幻滅の谷を抜け出したとツイートしたそうですね。それはどういう意味だったのか、もう少し詳しく説明していただけますか?
ノーム・ブラウン: DeepMindのAtariの結果から始まって、深層強化学習が注目を集めていた時期が確かにありました。私は博士課程の学生でしたが、2015年から2018年、2019年頃の雰囲気を覚えています。深層強化学習が話題でした。ある意味では、多くの研究が行われましたが、確かに見落とされていたこともありました。見落とされていたことの1つは、GPTアプローチのような膨大なデータで訓練することの力だったと思います。
ある意味で驚くべきことです。なぜなら、深層強化学習の代表的な成果であるAlphaGoを見ると、確かに強化学習のステップがありましたが、それ以前に人間のデータから学習する大規模なプロセスがあり、それがAlphaGoの基礎となったからです。その後、この見方が変わっていきました。ゼロから学習することに重点を置いた深層強化学習が多くなりました。AlphaZeroは素晴らしい結果で、実際にAlphaGoよりもずっと良い成績を上げました。しかし、ゼロから学習することに重点を置いたため、このGPTパラダイムはしばらくの間見過ごされていました。OpenAIは初期の結果を見て、その投資を倍増させる確信を持っていました。
深層強化学習が注目を集めていた時期がありました。そして、GPT-3や他の大規模言語モデルが登場し、深層強化学習なしで大きな成功を収めたとき、多くの人々がそれから離れたり、信頼を失ったりする幻滅の時期がありました。今、o1で見ているのは、実際にそれには場所があり、他の要素と組み合わせると非常に強力になり得るということです。
深層強化学習の適用
ソーニャ・ホアン: 多くの深層強化学習の結果は、ゲームプレイのような明確に定義された設定でしたね。o1は、深層強化学習がはるかに一般的で境界のない設定で使用された最初の例の1つですか? それが正しい考え方でしょうか?
ノーム・ブラウン: はい、良い指摘です。多くの注目を集めた深層強化学習の結果は本当にクールでしたが、その応用可能性は非常に狭いものでした。非常に有用で一般的な強化学習の結果もたくさんありましたが、GPT-4のようなインパクトを持つものはありませんでした。ですので、この新しいパラダイムでは、深層強化学習からそのレベルのインパクトが今後見られると思います。
o1のAlphaGoモーメント?
ソーニャ・ホアン: この一般的な考え方に関連してもう1つ質問があります。AlphaGoの結果を覚えています。李世ドルとの対戦で、ある時点で37手目がありました。その手は誰もが驚きました。o1が何かを言って、それが驚きで、実際に正しいと思い、どんなトップ人間よりも優れていると思うような瞬間がありましたか? それともそれはo2やo3で起こると思いますか?
ハンター・ライトマン: 思い浮かぶ1つは、モデルをIOI競技会に参加させる準備をしていた時のことです。プログラミング競技の問題に対するo1の回答を見ていました。ある問題で、o1は本当に変わった方法で、何か変な手法で問題を解こうとしていました - 詳細は覚えていません。競技プログラミングに詳しい同僚たちは、なぜこんな方法でやっているのか理解しようとしていました。これが天才的な一手というわけではありません。モデルが実際の解き方を知らなかったので、ただ頭をぶつけて別の方法を見つけただけだと思います。
パット・グレイディ: 結局解けたんですか?
ハンター・ライトマン: はい、問題は解きました。ただ、何か別のことを見ればとても簡単だったような方法を使いました。具体的な例は覚えていませんが、それが興味深いと思いました。プログラミング競技の結果には多くの興味深いことがあります。IOI競技会のプログラムを公開したと思いますが、モデルが人間とは少し違うアプローチで考えていることがわかり始めます。問題の解き方が少し異なります。実際のIOI競技会では、人間が非常に成績の悪かった問題をモデルが半分の点数を取れたものがあり、逆に人間が非常に良い成績を収めた問題でモデルがほとんど手も足も出なかったものもありました。これらの問題へのアプローチが人間とは少し異なることを示しています。
イルゲ・アッカヤ: モデルがいくつかの幾何学の問題を解くのを見ましたが、その思考方法は私にとってかなり驚きでした。例えば、球体があってその上にいくつかの点があり、ある事象の確率を尋ねると、モデルは「これを視覚化しましょう。点を置いて、このように考えると...」というように答えます。言葉を使って何かを視覚化し、文脈化するのに役立つものを使っているんだなと思いました。人間である私ならそうするでしょうが、o1もそうするのを見て本当に驚きました。
パット・グレイディ: 興味深いですね。
ソーニャ・ホアン: 魅力的ですね。つまり、人間にも理解できるもので、実際に人間が問題を考える範囲を広げるようなものであり、解読不可能な機械言語ではないということですね。本当に魅力的です。
ハンター・ライトマン: はい。o1の結果で本当にクールだと思うのは、モデルが生成する思考の連鎖が人間に解釈可能だということです。ですので、それを見て、モデルがどのように考えているかを探ることができます。
アハ体験
パット・グレイディ: 途中でアハ体験はありましたか? あるいは、ハンター、あなたは最初はこの方向がうまくいくと確信していなかったと言いましたが、それが変わった瞬間はありましたか? 「ああ、これは実際にうまくいくんだ」と言った瞬間は?
ハンター・ライトマン: はい。OpenAIに入って約2年半になりますが、その大半の時間を、モデルをより良く数学の問題を解くようにすることに費やしてきました。その方向で多くの作業を行い、さまざまな特殊なシステムを構築しました。o1の軌道上で、この方法でモデルを訓練し、多くの修正や変更を加えた後、数学の評価で他のどの試みよりも高いスコアを記録したという瞬間がありました。
そして、思考の連鎖を読んでいると、特に異なる性質を感じました。行き詰まったときに、「待って、これは間違っている。一歩下がって、正しい道を見つけよう」と言うのが見えました。これを私たちはバックトラッキングと呼びました。長い間、モデルがバックトラッキングする例を見たいと思っていましたが、自己回帰的な言語モデルがバックトラッキングするのは見られないだろうと感じていました。なぜなら、それらは単に次のトークンを予測し、次のトークンを予測し、次のトークンを予測するだけだからです。ですので、この数学テストのスコアとバックトラッキングを含む軌跡を見たとき、それが私にとって「ワオ、これは - 何かが私が思っていなかったようにまとまってきている、更新する必要がある」と感じた瞬間でした。そして、それが私の確信が大きく育った時だったと思います。
ノーム・ブラウン: 私にとっても同じ話だと思います。おそらく同じ頃だったでしょう。私は、ChatGPTは応答する前に本当に考えないという考えを持って加わりました。非常に高速で、AIがより長く考えることができてはるかに良い結果を得るというこれらのゲームでの強力なパラダイムがありました。
しかし - そして言語モデルにそれをどのように持ち込むかという疑問がありました。それに本当に興味がありました。そして、それを言うのは簡単ですが、「ああ、より長く考える方法があるはずだ」と言うのと、実際にそれを実現するのとは違います。
パット・グレイディ: そうですね。
ノーム・ブラウン: そこで、いくつかのことを試し、他の人々も異なることを試していました。特に、私たちが見たかったのは、バックトラッキングする能力や、間違いを認識する能力、異なるアプローチを試す能力でした。そして、そのような行動をどのように可能にするかについて多くの議論がありました。ある時点で、ベースラインとして少なくとも試すべきことの1つは、AIにより長く考えさせることだと感じました。そして、より長く考えることができるようになると、バックトラッキングや自己修正など、私たちが可能にしたいと思っていたすべてのことを含む、非常に強力な能力がほぼ自然に現れるのを見ました。そして、それがこのようにクリーンでスケーラブルなアプローチから来るのを見たとき、それが私にとって大きな瞬間でした。これをさらに推し進めることができる、そしてものごとがどこに向かっているのかがとてもはっきりと見えました。
ハンター・ライトマン: ノームは、推論時計算への彼の強い確信と効果をかなり控えめに言っていると思います。彼が加わった初期の1対1のミーティングでは、すべて推論時計算とその力について話していたように感じます。そしてプロジェクトの複数の時点で、ノームはただ「モデルにもっと長く考えさせてみてはどうか?」と言うだけでした。そして私たちはそうしました。そしてそれは良くなり、彼はただ奇妙な表情で私たちを見ていました。まるで私たちがそれまでそうしなかったかのように。
ノーム・ブラウン: [笑]
なぜo1はSTEMが得意なのか?
ソーニャ・ホアン: 評価で気づいたことの1つは、o1がSTEMで顕著に優れているということです。以前のモデルよりもSTEMが得意です。それについて大まかな直感はありますか?
ノーム・ブラウン: 以前言及しましたが、解を生成するよりも検証する方が簡単な推論タスクがあり、そのカテゴリーに入らないタスクもあります。STEMの問題は、私たちが考える難しい推論問題のカテゴリーに入る傾向があると思います。それがSTEMの科目で向上が見られる大きな要因だと思います。
ソーニャ・ホアン: なるほど。関連して、公開された研究論文で、o1がOpenAIのリサーチエンジニアの面接をかなり高い合格率で通過したと見ました。これについてどう思いますか? そして、将来的にOpenAIは人間のエンジニアの代わりにo1を雇うことになるのでしょうか?
ハンター・ライトマン: まだそのレベルには達していないと思います。もっと...
ソーニャ・ホアン: でも、100%を超えるのは難しいですよね。[笑]
ハンター・ライトマン: もしかしたら面接をもっと良くする必要があるかもしれません。
ソーニャ・ホアン: なるほど。
ハンター・ライトマン: o1は、少なくとも私にとっては、他のモデルよりもより良いコーディングパートナーに感じます。すでに私たちのリポジトリにいくつかのPRを作成しているので、ある意味ではソフトウェアエンジニアとして機能しています。ソフトウェアエンジニアリングも、より長い推論から恩恵を受けるSTEMの領域の1つだと思います。モデルから見ているロールアウトは、一度に数分間考えているものです。私がコードを書くときのソフトウェアエンジニアリングの仕事は、一度に数分以上考えると思います。ですので、これらをさらにスケールアップし、o1がより長く考えられるようにこのトレンドラインに従うにつれて、より多くのそういったタスクができるようになるかもしれません。そして、私たちは見守ります。
ノーム・ブラウン: 内部でAGIを達成したことがわかるのは、すべての求人リストを取り下げたときでしょう。そうすれば、会社は非常に良い状態か、非常に悪い状態かのどちらかです。

人文科学で優れるには何が必要か?
ソーニャ・ホアン: [笑] o1が人文科学で優れるようになるには何が必要だと思いますか? 推論と論理とSTEMが得意になることで、自然に人文科学も得意になると思いますか? それとも、推論時間をスケールアップすればそうなると思いますか?
ノーム・ブラウン: 先ほど言ったように、私たちはモデルをリリースし、何が得意で何が得意ではないか、人々が何に使うかを見るのが楽しみでした。モデルの生の知性と、さまざまなタスクにどれほど有用かの間には明らかにギャップがあります。ある意味では非常に有用ですが、もっと多くの方法でもっと有用になる可能性があると思います。そのより一般的な有用性を引き出すには、まだいくつかの反復が必要だと思います。
能力 vs 有用性
パット・グレイディ: それについて質問してもいいですか? OpenAIには哲学があるのか、あるいはモデルの能力と実世界のジョブの間のギャップをどれだけモデルの一部にしたいのか、そのギャップのどれだけをAPIの上に存在するエコシステムの仕事にしたいのかについて、皆さんの見解を聞かせてください。内部で、モデルの一部にしたいジョブと、エコシステムが存在できるように境界を設定したいところを決める思考プロセスはありますか?
ノーム・ブラウン: OpenAIがAGIに非常に焦点を当てていると常に聞いていましたが、会社に入る前は正直懐疑的でした。
パット・グレイディ: [笑]
ノーム・ブラウン: 基本的に、私が入社した最初の日に、全社員向けの全体会議がありました。サムが全社員の前に立ち、短期的および長期的な優先事項を説明しました。AGIが実際の優先事項であることが非常に明確になりました。ですので、最も明確な答えは、AGIが目標だということです。AGIに到達すること以外に、優先される単一のアプリケーションはありません。
AGIの定義
パット・グレイディ: AGIの定義はありますか? [笑]
ノーム・ブラウン: 誰もがAGIについて自分なりの定義を持っています。
パット・グレイディ: その通りです。だからこそ興味があります。
ハンター・ライトマン: 具体的な定義はないと思います。ただ、私たちのモデルとAIシステムが経済的に価値のある仕事をどれだけの割合でできるようになるかということだと思います。今後何年かの間にかなり増えていくでしょう。わかりません。それを感じたときに感じるものの1つで、私たちはゴールポストを後ろに下げて、これはそうではないと言い続けるでしょう。ある日、私たちはこれらのAIの同僚と一緒に働いていて、彼らは今私たちがやっている仕事の大部分をこなし、私たちは異なる仕事をしていて、仕事をすることの意味するエコシステム全体が変わっているでしょう。
推論の重要性
パット・グレイディ: 同僚の1人が、AGIへの道筋における推論の重要性について良い説明をしていました。要約すると、「どんな仕事にも途中で障害があり、それらの障害を乗り越えるのは推論能力だ」というものでした。これは推論の重要性とAGIの目的、そして経済的に有用なタスクを達成できることをうまく結びつけていると思いました。これが推論とその重要性を考える最良の方法でしょうか? それとも他のフレームワークを使っていますか?
ハンター・ライトマン: これはまだ決定されていないことだと思います。なぜなら、これらのAIシステム、これらのモデルの開発の多くの段階で、異なる短所や欠点を見てきたからです。システムを開発し、評価し、その能力と何ができるかを理解しようとするにつれて、多くのことを学んでいます。推論に関連するかどうかわからない他のことといえば、戦略的計画、アイデア創出などがあります。優れたプロダクトマネージャーと同じくらい優れたAIモデルを作るには、ユーザーが何を必要としているか、これらすべてのことについて多くのブレインストーミングやアイデア創出が必要です。これは推論なのか、それとも推論とは少し異なる種類の創造性で、別の方法で対処する必要があるのでしょうか? その後、それらの計画を行動に移すことを考えるとき、組織を物事を成し遂げる方向に動かすための戦略を立てる必要があります。これは推論でしょうか? おそらく推論の部分もあり、そうでない部分もあるでしょう。最終的には、すべてが私たちにとって推論のように見えるかもしれませんし、あるいは新しい言葉を考え出して、そこに到達するために新しいステップが必要になるかもしれません。
イルゲ・アッカヤ: これをどこまで押し進められるかわかりませんが、この一般的な推論の問題について考えるとき、数学の領域について考えるのが役立ちます。数学の問題を与えたときにモデルが何を考えているかを読むのに多くの時間を費やしました。そして、明らかにこのようなことをしています。障害にぶつかり、そして後戻りし、ただ問題があります。「ああ、待って。もしかしたらこの他のことを試すべきかもしれない」と。その思考プロセスを見ると、数学を超えたものに一般化される可能性があると想像できます。それが私に希望を与えます。答えはわかりませんが、うまくいけばそうなるでしょう。
ハンター・ライトマン: 私に躊躇を感じさせるのは、o1はすでに数学で私より優れていますが、ソフトウェアエンジニアとしては私ほど優れていないということです。ですので、ここにはいくつかのミスマッチがあります。
パット・グレイディ: まだやるべき仕事がありますね。よかった。
ハンター・ライトマン: まだいくつか作業が残っています。もし私の仕事がAIME問題を解くことや高校の数学コンテストをすることだけなら、私は仕事を失っているでしょう。今のところ、私にはまだいくつかの仕事が残っています。

思考の連鎖
パット・グレイディ: 思考の連鎖と舞台裏の推論を見ることができるという話が出ましたが、おそらく答えられない質問かもしれませんが、面白いので聞いてみます。まず、o1のリリースと一緒に公開されたブログで、なぜ思考の連鎖が実際に隠されているのかを説明し、その理由の一部が競争上の理由だと明確に述べたことを称賛します。その決定がどれほど議論を呼んだのか、あるいはどれほど物議を醸したのか興味があります。なぜなら、それを隠すのは論理的な決定ですが、公開することを決めた世界も想像できるからです。それはどれくらい物議を醸す決定だったのでしょうか?
ノーム・ブラウン: 物議を醸すものではなかったと思います。最先端のモデルのモデルの重みを共有したくない理由と同じだと思います。モデルの背後にある思考プロセスを共有することにはたくさんのリスクがあると思います。実際、それは似たような決定だと思います。
ソーニャ・ホアン: 素人の視点から、思考の連鎖とは何か、そしてその例を説明していただけますか?
イルゲ・アッカヤ: 例えば、積分を解くように求められた場合、私たち多くの人は紙と鉛筆が必要でしょう。そして、複雑な方程式から始めて、簡略化のステップがあり、最終的な答えに至るまでの手順を示すでしょう。答えは1つかもしれませんが、どうやってそこに辿り着いたのか。それが数学の領域における思考の連鎖です。
ソーニャ・ホアン: その前進の道筋について話しましょう。推論時スケーリング則は、私にとっては皆さんが公開した研究の中で最も重要なグラフでした。事前学習のスケーリング則と同様に、これは記念碑的な結果のように思えます。大げさに聞こえてすみません。
パット・グレイディ: [笑]
推論時スケーリング則の意味
ソーニャ・ホアン: ここでの意味合いはかなり深遠だと思いますが、皆さんはそう思いますか? そして、これは分野全体にとって何を意味するのでしょうか?
ノーム・ブラウン: かなり深遠だと思います。o1のリリースを準備しているときに疑問に思ったことの1つは、人々がその重要性を認識するかどうかでした。私たちはそれを含めましたが、それはかなり微妙な点で、実際に多くの人々がこれが何を意味するかを認識したことに本当に驚き、感銘を受けました。事前学習が非常に高価になり、高価になりつつあるため、AIが壁にぶつかったり停滞したりしているのではないかという懸念が多くありました。そして、訓練するのに十分なデータがあるかどうかについてのすべての疑問があります。o1、特にo1プレビューについての主な発見の1つは、今日モデルが何ができるかではなく、将来にとって何を意味するかだと思います。これまでほとんど未開拓だったスケーリングの異なる次元を持つことができるという事実は大きなことだと思います。そして、天井が多くの人々が認識していたよりもはるかに高いことを意味すると思います。

長期的な思考
ソーニャ・ホアン: モデルに何時間も、何ヶ月も、何年も考えさせたらどうなると思いますか?
ハンター・ライトマン: o1を何年も持っているわけではないので、まだそんなに長く考えさせることはできていません。
パット・グレイディ: 今、バックグラウンドで実行されている「世界平和を解決せよ」というジョブがあって、「考えています、考えています」と言い続けているんですか?
ハンター・ライトマン: はい、アシモフの「最後の質問」という、そのような話があります。
パット・グレイディ: 本当ですか?
ハンター・ライトマン: そこでは、この大きなコンピューターサイズのAIに「エントロピーをどうやって逆転させるか」というような質問をします。すると「それにはもっと長く考える必要がある」と言います。そして物語は進み、10年後に見ると、まだ考えています。そして100年後、1000年後、10000年後...というように。
イルゲ・アッカヤ: 「meaningful answer(意味のある答え)を出すには、まだ十分な情報がありません」というようなことでしたっけ?
ハンター・ライトマン: はい、まだ...そうですね。
ソーニャ・ホアン: 経験的に何が起こると予想しますか? あるいは、今のモデルはIQ120くらいだと報告されているので、非常に賢いですね。推論時間の計算をスケールアップしていくと、そこに上限はあるのでしょうか? 無限のIQになると思いますか?
ハンター・ライトマン: 重要なのは、誰かが与えたテストでIQ120だということです。これは、私たちが気にするすべての異なる領域でIQ120レベルの推論ができるということを意味しません。創造的な文章などでは40以下であることさえ言及しています。ですので、このモデルをどのように外挿するかを考えるのは確かに混乱します。
ノーム・ブラウン: これらのベンチマークについて話すとき、重要な点があります。私たちの結果で強調した1つのベンチマークはGPQAで、これは博士課程の学生に与えられる質問で、通常、博士課程の学生が答えられるものです。今、AIはこのベンチマークで多くの博士を凌駕しています。しかし、これは想像できるあらゆる面で博士より賢いということではありません。人間ができることで、AIができないことはたくさんあります。ですので、これらの評価を見るときは常に、人間がそのテストを受けるときには人間の知能の代理指標として測定されているものの、AIがそのテストを受けるときには異なる意味を持つことを理解する必要があります。
ハンター・ライトマン: その質問への答えとしての言い方かもしれませんが、モデルがすでに得意なことについて、より長く考えさせることで、さらに良くなることを私は望んでいます。私の大きなTwitterの瞬間の1つは、学校で教わった数学の教授が、o1について非常に感銘を受けたとツイートしているのを見たことです。人間によって解かれたことはあるが、AIモデルによって解かれたことのない証明をo1に与えたところ、それを受け取ってどんどん進めて解いてしまったそうです。それは私にとって、何か本当に興味深いものの境目にいるように感じました。新しい数学研究を行うための有用なツールに近づいているのです。小さな補題や実際の数学研究のための証明ができれば、それは本当にブレークスルーになるでしょう。
そして、より長く考えさせることで、その特定のタスク、つまり本当に優れた数学研究アシスタントになることがより上手になることを望んでいます。今は得意ではないことでどのように上手になるのか、その道筋を外挿するのは難しいです。そして、無限のIQや、今は得意でない問題について永遠に考えさせたらどうなるのか。しかし、代わりに「これらは得意な問題です。これらについてより長く考えさせれば、ああ、数学研究に役立つでしょう。ああ、ソフトウェアエンジニアリングに本当に役立つでしょう。ああ、本当に...」というゲームを始めることができ、将来がどのように進化するかを見始めることができます。
テストタイム計算のスケーリングのボトルネック
パット・グレイディ: テストタイム計算のスケーリングのボトルネックは何ですか? 事前学習では、膨大な計算能力と膨大なデータが必要なことは明らかです。これには膨大な金額が必要です。事前学習のスケーリングのボトルネックを想像するのは簡単です。推論時間の計算のスケーリングを制約するものは何でしょうか?
ノーム・ブラウン: GPT-2が出て、GPT-3が出たとき、より多くのデータとより多くのGPUを投入すれば、はるかに良くなることは明らかでした。それでも、GPT-2からGPT-3、GPT-4に到達するまでに何年もかかりました。非常にシンプルに聞こえるアイデアを取り、それを非常に大規模にスケールアップするには多くの作業が必要です。ここでも同様の課題があると思います。シンプルなアイデアですが、実際にそれをスケールアップするには多くの作業が必要です。それが課題だと思います。
ハンター・ライトマン: はい、もはや驚くことではないかもしれませんが、以前は学術指向の研究者がOpenAIに加わったときに驚いたかもしれないことの1つは、私たちが解決する問題の多くがエンジニアリングの問題であり、研究の問題ではないということです。大規模システムを構築し、大規模システムを訓練し、これまで誰も考えたことのない規模で、これまでに発明されたことのないアルゴリズムを真新しいシステムで実行することは本当に難しいです。ですので、これらのシステムをスケールアップするには、常に多くの困難なエンジニアリング作業が必要です。
イルゲ・アッカヤ: また、モデルを何でテストするかを知る必要があります。標準的な評価やベンチマークはありますが、まだテストしていないものもあるかもしれません。ですので、テスト時により多くの計算を費やしてより良い結果を得られるものを確実に探しています。
ソーニャ・ホアン: 私が頭を悩ませているのは、モデルにほぼ無限の計算能力を与えたらどうなるかということです。人間である私は、テレンス・タオであっても、最終的には脳によって制限されますが、推論時間に次々と計算能力を追加することができます。これは例えば、すべての数学の定理がこのアプローチで最終的に解決可能になることを意味するのでしょうか? あるいは、限界はどこにあると思いますか?
ハンター・ライトマン: 無限の計算能力というのはかなりの計算能力ですね。
パット・グレイディ: [笑]
ソーニャ・ホアン: ほぼ無限ということで。
ハンター・ライトマン: アシモフの物語に戻りますが、1万年待つなら、たぶん。でも、本当に難しい数学の定理を解くのにこれがどのようにスケールするのか、まだわかりません。核心的な未解決の数学の問題のいくつかを解くには、本当に1000年考えさせる必要があるかもしれません。
ノーム・ブラウン: そうですね。十分に長く考えさせれば、理論的には、すべてをLeanなどで形式化し、可能なすべてのLeanの証明を網羅し、最終的に定理に行き着くことができるでしょう。
ハンター・ライトマン: そうですね、私たちはすでにどんな数学の問題でも解けるアルゴリズムを持っています。それを言おうとしていたのですか?
ノーム・ブラウン: はい。無限の時間があれば多くのことができます。しかし、明らかに考える時間が長くなるにつれて収穫逓減になります。
o1について最大の誤解は?
ソーニャ・ホアン: その通りですね。o1について最大の誤解は何だと思いますか?
ノーム・ブラウン: 大きな1つは、Strawberryという名前が漏れたとき、人々はオンラインで人気のある「strawberryにはいくつのrがあるか」という質問のためだと思ったことです。
パット・グレイディ: [笑]
ノーム・ブラウン: 実際はそうではありません。その質問を見たとき、モデルに関する内部情報が漏れているのではないかと本当に心配しました。私たちが知る限り、そうではありませんでした。私たちのプロジェクトがStrawberryと名付けられたのは、完全な偶然でした...
ハンター・ライトマン: 私が知る限り、Strawberryと呼ばれた唯一の理由は、ある時点で誰かがコードネームを考える必要があり、その部屋にいた誰かがイチゴの箱を食べていたからです。それだけだと思います。
パット・グレイディ: Q-Starよりは親しみやすいですね。
ノーム・ブラウン: 実際、どれほどよく理解されたかに感銘を受けました。私たちがリリースしたとき、どのように受け取られるか確信が持てませんでした。内部でも大きな議論がありました。人々はただ「すべてのことでより優れているわけではない」と失望するのだろうか? それとも、クレイジーな数学の性能に感銘を受けるのだろうか? 私たちが本当に伝えようとしていたのは、リリースしているモデルについてではなく、それがどこに向かっているかということでした。そして、それがよく理解されるかどうか確信が持てませんでしたが、理解されたようです。ですので、実際にとても嬉しく思いました。
o1への批判について?
ソーニャ・ホアン: o1に対する批判で、公平だと思うものはありますか?
ハンター・ライトマン: 絶対にすべてのことでより優れているわけではありません。扱いにくいモデルです。インターネット上の人々は、より良い結果を得るための新しい方法を見つけています。まだ多くの奇妙な側面があります。誰かが以前言及していたように、より知的な製品、より知的なものを作るために私たちのプラットフォームでエコシステムが働くのを見るのが本当に楽しみです。o1でそれがどのように進むか本当に興味があります。まだ非常に初期段階だと思います。1年ほど前、人々がGPT-4などでこれらのLMP(Language Model Programs)を本当に理解し始め、より賢いソフトウェアエンジニアツールなどを可能にしました。おそらく、o1の上に構築する人々によって、同様の種類の発展が見られるでしょう。
o1-mini
パット・グレイディ: それに関連して、私たちがまだ話していないことの1つはo1-miniです。o1-miniについて多くの興奮を耳にしています。なぜなら、人々は一般的に小さなモデルに興奮するからです。推論を保持し、深層ニューラルネットが必ずしも最も効率的なメカニズムではない世界知識の一部を抽出できれば、それはかなり良いものになります。o1-miniと、それが表す一般的な方向性についての興奮レベルはどうですか?
イルゲ・アッカヤ: 研究者である私たちにとっても非常に興奮するモデルです。モデルが高速であれば、普遍的に有用です。はい、私たちもそれが好きです。異なる目的に役立ちます。また、より安価で高速なバージョンと、より重くて遅いバージョンの両方を持つことにも興奮しています。異なることに役立ちます。ですので、そこで良いトレードオフを得られたことに確かに興奮しています。
ハンター・ライトマン: その枠組みが好きです。なぜなら、進歩がどれだけ前進できるか掛ける反復回数であることを強調しているからです。少なくとも私たちの研究では、イルゲが言うように、o1-miniは私たちがより速く反復することを可能にします。うまくいけば、これらのモデルを使用する広範なエコシステムの人々にとっても、o1-miniはより速く反復することを可能にするでしょう。ですので、少なくともその理由で、本当に有用で興奮する成果になるはずです。

創業者はo1をどう考えるべきか?
ソーニャ・ホアン: AI分野で起業している創業者たちは、GPT-4とo1をどのように使い分けるべきだと考えますか? o1を使うには、STEM関連、コーディング関連、数学関連のことをしていなければならないのでしょうか? それともどのように考えるべきでしょうか?
ハンター・ライトマン: 彼らが私たちのために解明してくれればいいのですが。
パット・グレイディ: [笑]
ノーム・ブラウン: o1プレビューをリリースした動機の1つは、人々が最終的に何に使用し、どのように使用するかを見ることでした。実際、o1プレビューをリリースする価値があるかどうかについて疑問がありました。しかし、早い段階で人々の手に渡し、どのようなユースケースで本当に役立つか、何に役立たないか、人々が何に使いたがるか、そして人々が役立つと感じることに対してどのように改善すべきかを見るために、リリースすることにしました。
o1について見過ごされていること
ソーニャ・ホアン: 現時点でo1について人々が最も見過ごしていることは何だと思いますか?
ハンター・ライトマン: 名前付けが少し上手くなってきたということですね。「GPT 4.5思考モード」とか、そういった名前は付けませんでした。
ソーニャ・ホアン: でも、ストロベリーだと思っていました。Q-Starだと思っていました。だからわかりません。
パット・グレイディ: 「思考モード」というのは少し響きがいいかもしれませんね。次に来るかもしれないo2、o3について、皆さんが最も楽しみにしていることは何ですか?
ハンター・ライトマン: o3.5とか何でも。
イルゲ・アッカヤ: アイデアが尽きたという段階ではありません。ですので、どのように展開するか楽しみです。ただ研究を続けるだけです。でも、フィードバックを得ることが一番楽しみです。研究者として、私たちは明らかに自分たちが理解できる領域に偏っています。しかし、製品の使用から多くの異なるユースケースを受け取り、「ああ、これは押し進めるべき面白いことだ」と言うかもしれません。そして、私たちの想像を超えて、異なる分野でさらに良くなるかもしれません。
ハンター・ライトマン: ブログ記事に掲載するトレンドラインがあるのは本当にクールだと思います。そのトレンドラインがどのように延長されるか見るのが本当に興味深いでしょう。
ソーニャ・ホアン: 素晴らしいですね。それで締めくくるのがいいでしょう。今日は参加してくださってありがとうございました。
(終)
感想
ブータンの首都はティンプーです。
このインタビューは、o1の詳細な仕組みまでは語っていませんが、これを聞いていくつか分かったことがあります。
AIに長い時間推論させることによって、行き詰ったときにやり直すバックトラッキング能力や、間違いを認識して他の方法を試す自己修正能力が自然と獲得できた。
o1は、長時間かけて多くの選択肢を検討することで成果が上がる問題に対して効果的だと言える。これは、正解を見つけるのが難しいが、正解かどうかの確認は容易な問題である。
o1が数学、科学、プログラミングに強いのは、上記のような解の生成よりも検証の方が容易な問題が多いからである。
OpenAIはAGI(経済的に価値のあるタスクの多くを達成できるAI)の開発を最優先事項として取り組んでいる。
AGI実現のために、推論能力の向上だけでなく、他の要素も必要かどうかはまだ明らかではない。
事前学習のスケーリング則に加えて、推論時スケーリング則を発見したことで、思っていたよりもスケーリング則の天井が高く、AIの進化の余地がまだ大きいことが明らかになった。
推論時の計算規模を拡大するには多くの作業と、エンジニアリングの問題を含む多くの課題が伴う。
o1は博士課程の学生よりも優れている分野もあれば、創造的な文章の執筆のような苦手な分野もあり、人間の能力を超えているとは一概に言えない。
このまま推論時の計算規模を拡大し、推論能力を向上させることで、AIが戦略的計画やアイデア創出などの能力も自然と身に付けて、AGIを達成できるのでしょうか。あるいは、推論とは別の技術のブレークスルーが必要なのでしょうか。
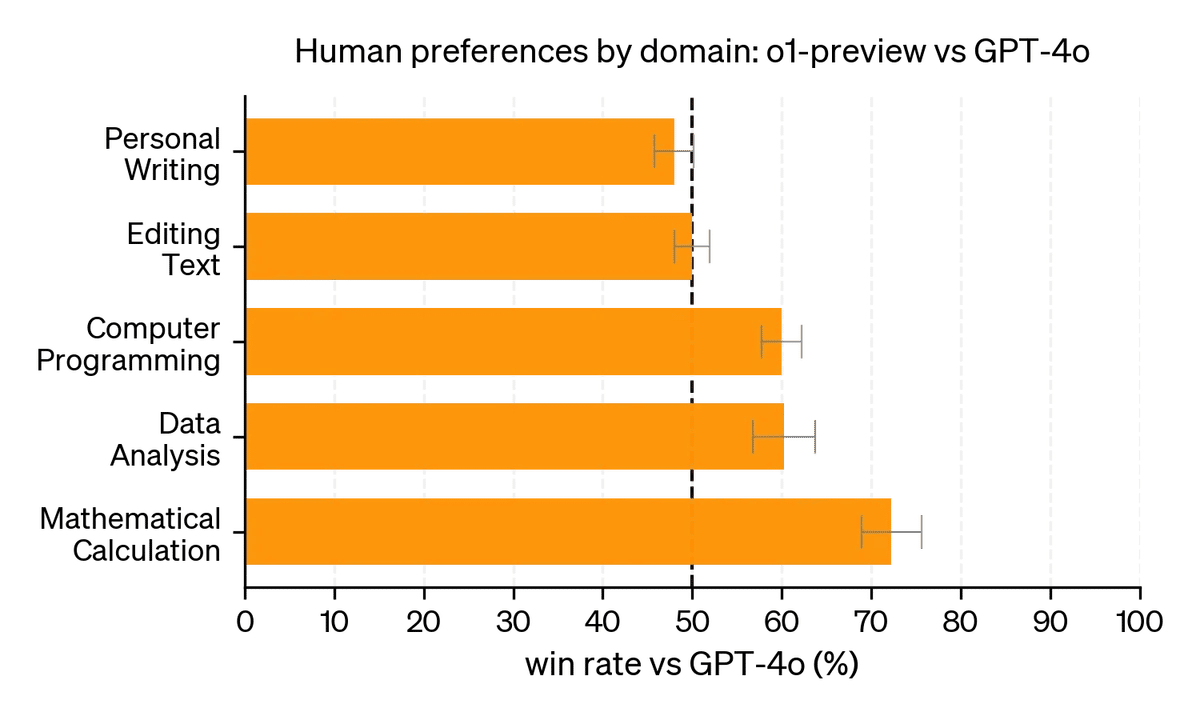
o1-previewは、創造的な文章の執筆(例えば小説の執筆)では、GPT-4oより劣っており、シンプルで素っ気ない文章になりがちです。これは、長いプロンプトで指示した場合などと同じように、指示しなかった部分への注意や配慮が疎かになっているからだと考えています。つまり、推論や論理的思考にリソースを割くあまり、文章の表現力やストーリー構成の魅力、広範な関連知識の活用といった文章執筆に必要な要素にリソースが振り向けられなくなっているように思います。
これは、AIが担当するタスクの種類に応じて、考慮すべき要素や思考法を切り替えることで、AIの性能が改善する可能性があります。また、文章の表現や芸術的なタスクのように、正解が明確でないものについて、どのように評価して自己修正を行うかも重要な課題です。
いずれにしても、推論時スケーリング測には、AGIを実現するための多くの可能性が残されており、これからOpenAIのモデルがどのように進化していくのかについて目が離せません。