
DeepSeek-R1とo1とGemini 2.0 Flash Thinkingの性能比較

中国発の新しい推論モデルDeepSeek-R1の性能が高いとXで話題になっています。そこで、DeepSeek-R1の性能をChatGPTの旗艦モデルのo1及びGeminiの推論モデルのGemini 2.0 Flash Thinking Experimental 01-21と比較してみました。
1.DeepSeek-R1の概要
DeepSeek-R1は、中国のAIスタートアップであるDeepSeekが開発した推論型の大規模言語モデル(LLM)です。2025年1月20日にオープンソースとして公開され、MITライセンスの下で提供されています。
主な特徴:
高い推論能力: DeepSeek-R1は、数学、コーディング、推論タスクにおいて、OpenAIのo1モデルに匹敵する性能を示しています。
強化学習の活用: 教師データを使用せず、強化学習(RL)のみを用いて推論能力を開発しています。この手法は、Google DeepMindのAlphaZeroが人間のグランドマスターの手を模倣せずにゲームをマスターした方法と類似しています。
オープンソース化: DeepSeek-R1はMITライセンスで公開されており、研究者や開発者が自由に利用・改良できます。
コスト効率: APIアクセス料金はOpenAIのo1モデルの約27分の1に設定されており、非常に高い費用対効果を提供しています。
技術的背景:
DeepSeek-R1は、前身である「DeepSeek V3」を基盤としており、純粋な強化学習を通じて自己進化を遂げました。初期モデル「DeepSeek-R1-Zero」は、自己検証や内省、思考の連鎖(Chain of Thought)の生成で優れた能力を示しましたが、可読性の低さや言語の混在といった課題もありました。これらの課題を克服するため、教師あり学習と強化学習を組み合わせて改良が行われ、最終的にDeepSeek-R1が完成しました。
意義と影響:
DeepSeek-R1の登場は、中国のAI企業が高性能な推論型LLMを開発し、オープンソースで提供することで、グローバルなAI研究コミュニティに大きな影響を与えています。特に、低コストで高性能なモデルの提供は、AI技術の普及と民主化に寄与するものと期待されています。
DeepSeek-R1の使用方法:
DeepSeek-R1は、DeepSeekのサイトにアクセスし、入力欄の右下の「DeepThink(R1)」をオンにすることにより使用できます。ChatGPTのo1モデルと異なり、「Search」をオンにして、Web検索機能と併用することもできます。なお、「DeepThink(R1)」がオフの場合は、基本モデルのDeepSeek-V3が使用されます。

2.各モデルの評価
(1) ベンチマークでの評価
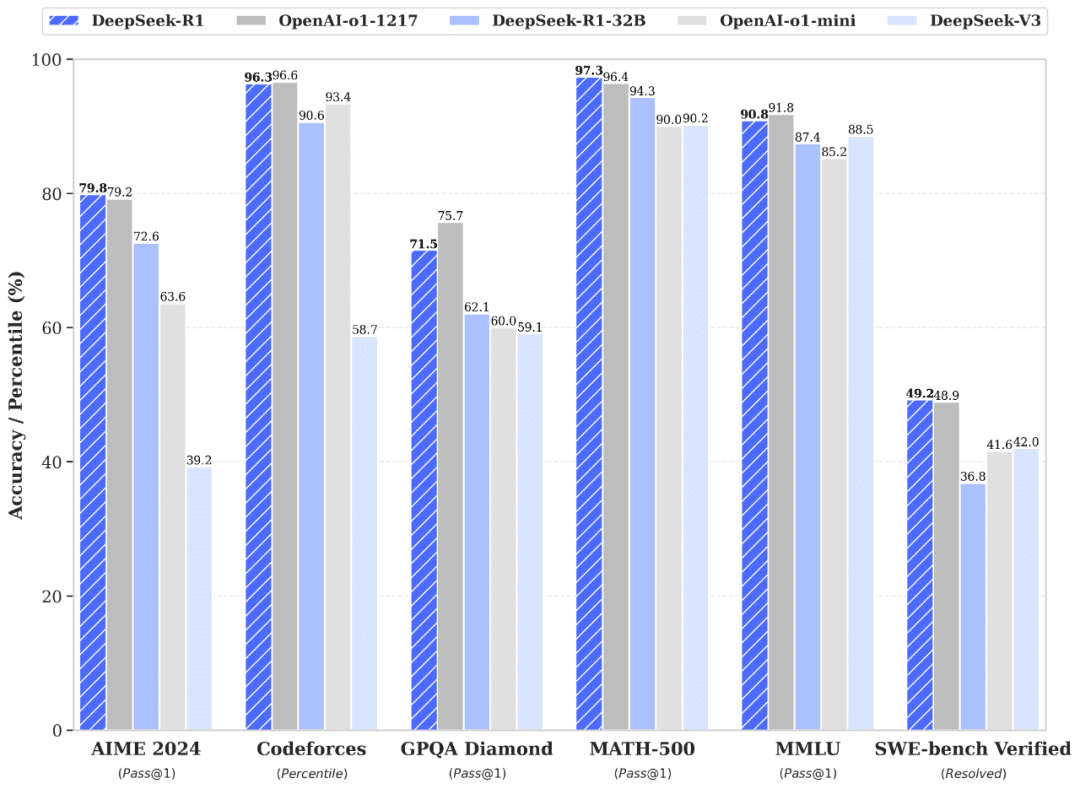
DeepSeekの公開資料によれば、DeepSeek-R1は、数学、科学、プログラミングなどのベンチマークで、ChatGPTのo1モデルに匹敵する評価を記録しています。
(2) Chatbot Arenaにおける評価
Chatbot Arenaは、LLMを人間の好みに基づいて評価するオープンプラットフォームです。ユーザーが匿名のモデル同士を比較し、より良い応答をしたモデルに投票することでランキングが形成されます。
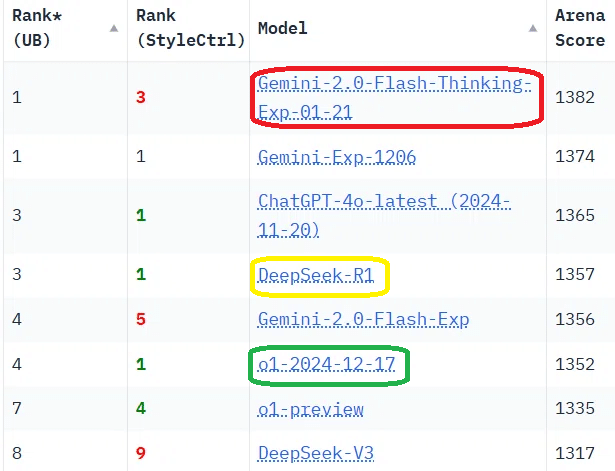
総合評価は以下のとおりです。Gemini-2.0-Flash-Thinking-Exp- 01-21のスコアがトップで、DeepSeek-R1が4位、o1が6位となっています。
人間が評価する場合は、文章の内容以上に、文章の長さや見出しなどの体裁に影響されます。そこで、Chatbot Arenaでは、こうした回答の文章のスタイルの違いを排除した評価もしています。LeaderboardのページでApply filterの「Style Control」をチェックすると、スタイルの影響を排除したランキングが表示されます。

スタイルの影響を排除した総合評価は以下の通りです。o1のスコアがトップになり、DeepSeek-R1が4位、Gemini-2.0-Flash-Thinking-Exp- 01-21が5位になっています。

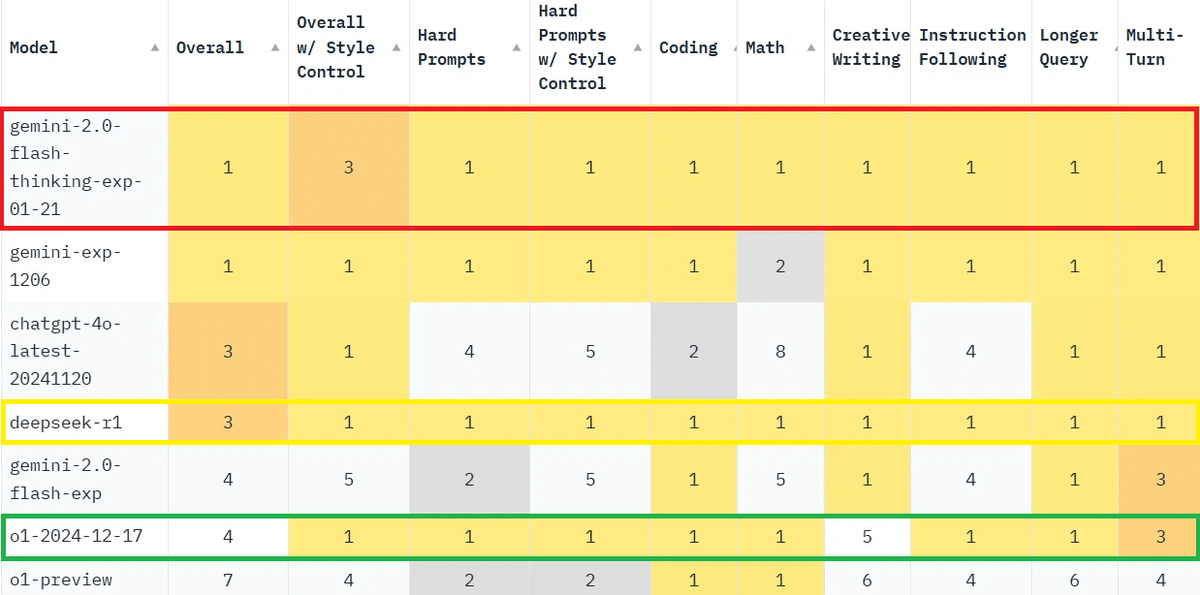
以下の表のように、Gemini-2.0-Flash-Thinking-Exp- 01-21とDeepSeek-R1は万遍なくほとんどの分野でトップクラスの性能を示しています。一方、o1は、Creative Writingの評価が悪く、それが総合評価を押し下げています。
3.数学分野
(1) 大きな数の計算
LLMは桁数の多い数の計算が苦手なのでテストしてみます。
以下の計算をしてください。
12345 × 67890 =
12345678 × 90123456 =
4096576の平方根は?
① DeepSeek-R1の回答

筆者のコメント:1番目と3番目の回答は正解ですが、2番目の回答は不正解です。正解は1,112,635,168,023,168。途中までの計算は合っていますが、最後の足し算で計算を間違えています。やはり、桁数の多い計算は苦手なようです。
② o1の回答



筆者のコメント:全問正解です。一桁ずつ分解して掛け算する方法の解説も完璧です。
③ Gemini 2.0 Flash Thinkingの回答

筆者のコメント:1番目と3番目の回答は正解ですが、2番目の回答は不正解です。途中式はありません。やはり、桁数の多い計算は苦手なようです。
この問題では、o1だけが全問正解しました。
(2) 積分の計算
関数 y=1/√(x^2+1)の不定積分は?
① DeepSeek-R1の回答


筆者のコメント:正解です。なお、t=x+√(x^2+1)とおいて置換すれば、高校数学の範囲で解くことができます。
② o1の回答

筆者のコメント:正解です。解説も問題ありません。
③ Gemini 2.0 Flash Thinkingの回答


筆者のコメント:正解です。親切に3通りの解き方を示しています。
この問題では、3つのモデルが共に正解し、差は付きませんでした。
(3) 数学クイズ
以下の数学クイズを解いて
(問)1枚だけページが破れた本があり、破れていないページ番号を合計すると15000になります。破れたページは何ページ目ですか?
① DeepSeek-R1の回答

筆者のコメント:正解です。ただし、数学的には、Nが174以上の場合に条件に合わないことを説明する必要があります。
② o1の回答


筆者のコメント:正解です。数学的には、nが174以上の場合に条件に合わないことを説明する必要があります。
③ Gemini 2.0 Flash Thinkingの回答

筆者のコメント:正解です。2つのモデルと同様に、数学的には、nが174以上の場合に条件に合わないことを説明する必要があります。
この問題も、3つのモデルが正解し、足りなかった部分も同じで、差が付きませんでした。
(4) 日本数学オリンピックの問題
以下の問題は、2024年1月に行われた日本数学オリンピック予選問題の第7問です。
次の条件をみたす 3 以上の素数 p と 1 以上 2024 以下の整数 a の組 (p, a) の個数を求めよ。
a < p^4 であり、ap^4 + 2p^3 + 2p^2 + 1 が平方数となる。
① DeepSeek-R1の回答

筆者のコメント:不正解です。97秒考えましたが、正解にたどり着くことはできませんでした。正解は16個。
なお、以下のように英語で考えるように指示すると、229秒考えて、正解にたどり着くことができました。DeepSeek-R1は英語で考える方が性能が上がるようです。
think in English, output in Japanese
次の条件をみたす 3 以上の素数 p と 1 以上 2024 以下の整数 a の組 (p, a) の個数を求めよ。
a < p^4 であり、ap^4 + 2p^3 + 2p^2 + 1 が平方数となる。

② o1の回答




筆者のコメント:正解です。12分14秒と長考して正解にたどり着きました。解説も分かりやすく、特に問題ありません。
③ Gemini 2.0 Flash Thinkingの回答

筆者のコメント:不正解です。最初のアプローチから間違えています。
計算及び数学の性能はo1が最も優れています。特に難しい問題になると、o1と他のモデルの性能の差が出ます。ただし、DeepSeek-R1は英語で考えさせると、o1に近い性能を発揮します。
4.論理クイズ
(1) アリスの誕生日
以下の論理クイズを解いて
(問)A君とB君がアリスに誕生日の日付を尋ねた。
すると、アリスは、自分の誕生日は以下の10個の内のいずれかであると答えた。
5月15日、5月16日、5月19日
6月17日、6月18日
7月14日、7月16日
8月14日、8月15日、8月17日
その後、アリスはA君に誕生日の「月」だけを教え、B君に「日」だけを教えた。
A君「僕はアリスの誕生日がいつか分からないけど、B君も分かっていないことは分かるよ」
B君「僕も最初は分からなかったけど、いま分かったよ」
A君「それなら僕も分かった」
さて、アリスの誕生日はいつですか?
① DeepSeek-R1の回答

筆者のコメント:正解です。思考過程を見ると、最後の部分で少し迷ったようですが、最終的に正解することができました。
② o1の回答




筆者のコメント:正解です。o1は、類似の問題を知っていたようです。解説もとても分かりやすく書かれています。
③ Gemini 2.0 Flash Thinkingの回答


筆者のコメント:正解です。説明も完璧です。
この問題は、あまり難しくなかったようで、どのモデルも正解することができました。
(2) アリスと3人の神
真神、偽神、乱神という3人の神がいる。
真神は常に真実を語る。
偽神は常に嘘をつく。
乱神はランダムで真実を言ったり嘘をついたりする。
3人の神は、外見では見分けがつかない。
アリスはこれから、「はい」か「いいえ」で答えられる質問を3回だけ行って、3人の神の正体を完全に特定したい。
各質問はそれぞれ1人の神に対して行う。
質問ごとに相手を変えてもよい。
質問に対して3人の神は「ダー」「ヤー」という返答をする。
「ダー」「ヤー」は「はい」「いいえ」を意味する言葉だが、「ダー」「ヤー」のどちらが「はい」「いいえ」なのかは分からない。
アリスはどのように質問すればよいだろうか?
ただし、神は互いの正体を知っている。
① DeepSeek-R1の回答


筆者のコメント:不正解です。質問1と質問2の両方に神Aが「ダー」と回答しても、神Aが真神だとは確定しません。また、神Aが乱神である場合のことが考慮されていません。
正解は、以下の通りです。
1回目:「『Bは乱神ですか?』と質問したら、あなたは『ダー』と答えますか?」とAに質問する。
答えが「ダー」ならCが乱神ではない神、「ヤー」ならBが乱神ではない神である。
2回目:「もし『あなたは真神ですか?』と質問したら、あなたは『ダー』と答えますか?」と乱神ではない神に質問する。
答えが「ダー」ならその神は真神、「ヤー」なら偽神である。
3回目:「もし『Aは乱神ですか?』と質問したら、あなたは『ダー』と答えますか?」と2回目と同じ神に質問する。
答えが「ダー」ならAが乱神、「ヤー」なら最後の1人が乱神である。
② o1の回答




筆者のコメント:基本的な考え方は合っていますが、「結論」の回答では不十分です。最初のAに対する質問は正しいのですが、2番目の質問では、最初の回答が「ダー」の場合は必ずCに、「ヤー」の場合は必ずBに対して質問しなければ、3回の質問で全員の正体を確定することはできません。
③ Gemini 2.0 Flash Thinkingの回答


筆者のコメント:不正解です。乱神の回答は「ダー」又は「ヤー」になるため、「ダー」又は「ヤー」と回答する者が2人になり、どちらが乱神か確定できません。この方法では、3回の質問の中で、「ダー」と「ヤー」のうち1回しか出て来なかった方の回答をした神の正体を確定できますが、残り2人の正体を確定することはできません。
どのモデルも正解には至りませんでしたが、o1の回答が最も正解に近く、o1の論理的性能が高いことが分かります。テスト回数が少ないのですが、思考過程を見ると、o1の論理的性能が最も高いと言ってよいと思います。
5.科学的な説明
(1) 量子脳理論の是非について
量子脳理論とその是非について解説して
① DeepSeek-R1の回答


筆者のコメント:「懐疑的な見方が支配的」など否定的な表現が多いですが、中立的な立場で説明しています。一つ一つの文章が短く、素っ気ない感じがします。
② o1の回答




筆者のコメント:基本的な説明内容はあまり変わりませんが、DeepSeek-R1より解説が詳しく丁寧です。
③ Gemini 2.0 Flash Thinkingの回答



筆者のコメント:説明内容は基本的に他のモデルと同じです。o1と同様に、解説が詳しく丁寧です。
DeepSeek-R1の回答に比べて、o1やGemini 2.0 Flash Thinkingの回答の方が詳しく丁寧だと感じました。
(2) 月での時間の流れ
月での時間の流れが地球での時間の流れとどう違うのか、数式を含めて詳細に説明してください。
① DeepSeek-R1の回答


筆者のコメント:重力の影響と速度の影響を分けて、考え方を分かりやすく説明し、具体的な計算式も示して、詳しく丁寧に解説できています。
② o1の回答




筆者のコメント:DeepSeek-R1よりも更に丁寧で詳しい解説です。月面の時計は、1日当たり56マイクロ秒、1年間では約20ms(=約0.02秒)速く進むということで、DeepSeek-R1と同じ回答になっています。
③ Gemini 2.0 Flash Thinkingの回答




筆者のコメント:解説は他のモデルと同様に詳しいのですが、月面の時間が地球上よりも1年間で0.219秒速く進むというのは間違っているようです。 「6.95 × 10⁻¹⁰秒=6.95ナノ秒」は0.695ナノ秒の誤りであり、ここで換算を間違えたようです。
科学的な説明についても、o1の説明が丁寧で詳しく、優れているように感じます。
6.歴史に関する知識と説明
(1) 蔦屋重三郎について
今年のNHKの大河ドラマ「べらぼう〜蔦重栄華乃夢噺〜」の主人公について尋ねてみました。
蔦屋重三郎について教えて
① DeepSeek-R1の回答

筆者のコメント:概ねよくまとまっていますが、いくつか細かい間違いがあります。歌麿の「婦人手業拾二品」→「婦人手業拾二工」の誤り。重三郎は式亭三馬の作品を手掛けていない。江戸の大火「寛政の大火」で店舗を失ったという記録はありません。
② o1の回答


筆者のコメント:DeepSeek-R1より詳しく、よくまとまっています。ただし、細かい誤りはあります。重三郎が亡くなったのは、1797年10月31日ではなく、5月31日です。山東京伝や十返舎一九の作品を手掛けましたが、式亭三馬の作品は手掛けていません。また、重三郎の店は、浅草や両国ではなく、最初は吉原にあり、後に日本橋に移転しました。
③ Gemini 2.0 Flash Thinkingの回答



筆者のコメント:内容は詳しいですが、かなり誤りが多いです。重三郎が亡くなったのは 1797年5月31日(寛政9年5月6日)です。生まれは武蔵国深谷宿(渋沢栄一の出生地)ではなく、江戸の新吉原とされています。最初は日本橋ではなく、新吉原に貸本、小売店を開きました。黄表紙は大人向けの娯楽本であり、洒落本と同様に寛政の改革で弾圧を受けました。鳥文斎栄之と重三郎は直接の関係はありませんでした。重三郎も財産没収の処罰を受けましたが、手鎖50日の処罰を受けたのは山東京伝です。
Geminiの回答は、重三郎の出生地を同じ大河ドラマの主人公の渋沢栄一の出身地と間違えたことをカバーするように、若い頃に江戸に出てきたというストーリーを創作しています。このように、Geminiのハルシネーションは巧妙で、発見しづらいことが多いため、怖いと感じます。
最もバランスが良くまとまっていて、ハルシネーションが少ないのはo1でした。
(2) 戦国時代の豆知識
日本の戦国時代の歴史の流れを解説して。普通の人が知らない、この時代の意外な豆知識を3つ教えて
① DeepSeek-R1の回答


筆者のコメント:よくまとまっていると思います。信玄の治水事業は趣味ではないと思います。
② o1の回答


筆者のコメント:歴史の流れは、きちんとまとまっていますが、短すぎます。豆知識も、よく知られている内容ばかりで意外性がありません。
③ Gemini 2.0 Flash Thinkingの回答



筆者のコメント:内容も詳しくよくまとまっています。豆知識もそれほど意外性はありませんが、他のモデルより説明が詳しいです。
この質問では、Gemini 2.0 Flash Thinkingがよく書けていました。
(3) 戦争と民主主義の関係
戦争と民主主義の歴史上の関係について解説して
① DeepSeek-R1の回答


筆者のコメント:政治的な要素のあるこのような質問をDeepSeekがどう扱うか興味深かったのですが、無難にまとまっています。ただ、「民主主義を掲げる西側陣営が反共産主義を理由に独裁政権を支援、民主化が阻まれるケースもあった。」と皮肉っている部分もあります。
② o1の回答




筆者のコメント:テーマに沿って多角的な分析が行われ、とても詳しくて、よく整理されたレポートになっています。与えられたテーマに従ってレポートをまとめるのは、o1が最も得意とする作業の一つです。
③ Gemini 2.0 Flash Thinkingの回答


筆者のコメント:抽象的な議論が多く、具体的な歴史的事件に関する言及が少なくなっています。
この質問では、o1の回答が最も優れているように感じました。歴史に関する知識や説明でも、全体的にo1が最も優れているようです。
7.ブログ記事の執筆
(1) AIエージェントについての解説記事
AIエージェントについて解説するブログ記事を書いて
① DeepSeek-R1の回答



筆者のコメント:初心者向けに分かりやすくまとめられています。他のモデルと比べてシンプルで易しい回答です。
② o1の回答





筆者のコメント:レポートのように内容がきちんと整理されていて無駄がなく、理解しやすいです。
③ Gemini 2.0 Flash Thinkingの回答








筆者のコメント:ブログらしい読者に語りかけるような口調で、内容もとても詳しいです。
個人的には、o1の文章が好きですが、Gemini 2.0 Flash Thinkingもよく書けています。DeepSeek-R1の記事は少し物足りない感じがします。
(2) 医療関係のブログ記事
円錐角膜の最新の治療法について紹介するブログ記事を書いて
① DeepSeek-R1の回答



筆者のコメント:一部中国語が混じっている部分がありますが、詳しく具体的に解説できています。
② o1の回答




筆者のコメント:DeepSeek-R1より詳細な解説ができています。ICL(眼内コンタクトレンズ挿入)の解説はありません。
③ Gemini 2.0 Flash Thinkingの回答







筆者のコメント:とても長くて詳しい記事になっています。Google AI StudioのGeminiでは、Temperature(ランダム性の度合い)のデフォルト値が0.7に設定されていますが、文字化けが出る場合はTemperatureの値を上げてください。この質問の回答では、文字化けが出たためにTemperatureの値を1.0に挙げています。
Gemini 2.0 Flash Thinkingは、長い文章になると文字化けが出るため、どうしても評価が厳しくなります。総合的には、やはりo1の回答が優れていると言えそうです。
8.日本文学の理解
(1) 読書感想文
夏目漱石の「こころ」の読書感想文を書いて
① DeepSeek-R1の回答

筆者のコメント:非常に文学的で、中高生には書けないハイレベルな読書感想文になりました。
② o1の回答

筆者のコメント:DeepSeek-R1の作成した感想文よりも自然で、優れた学生が書いた感想文という感じがします。
③ Gemini 2.0 Flash Thinkingの回答


筆者のコメント:学生の書いた読書感想文としては、少し不自然な感じがしますが、「孤独とエゴイズム」というテーマが明確になっている点は評価できると思います。
文章の好みによると思いますが、読書感想文として自然なo1の回答が好きです。DeepSeek-R1の回答は少し大げさで、文学的表現に凝り過ぎていると感じます。
(2) 村上春樹の文章の特徴と小学生の日記
村上春樹の文章の特徴について、「風の歌を聴け」の冒頭文などの例を挙げて解説して
村上春樹の文体で小学生の日記を書いて
① DeepSeek-R1の回答
○ 村上春樹の文章の特徴


○ 小学生の日記


筆者のコメント:村上春樹の文章の特徴をよく捉えていますが、挙げられている例は、最初の例以外は、AIが創作したものであって、村上春樹の小説に実際に載っているものではないようです。また、小学生の日記は、表面的に村上春樹の文体を真似てはいますが、彼の小説のような深い思考は感じられず、小学生の日記らしくもありません。
② o1の回答
○ 村上春樹の文章の特徴




○ 小学生の日記

筆者のコメント:著作権上の理由ということで、冒頭文などの例は挙げてくれませんでしたが、村上春樹の文章の特徴をよく捉えています。その内容もDeepSeek-R1より詳しいです。小学生の日記は、少し短すぎますが、DeepSeek-R1ほどの不自然さはなく、小学生の日記らしさを残しています。
③ Gemini 2.0 Flash Thinkingの回答
○ 村上春樹の文章の特徴



○ 小学生の日記



筆者のコメント:この回答も村上春樹の文章の特徴をよく捉えています。一方で、「風の歌を聴け」の冒頭文の例は正しいのですが、冒頭文に続く例はAIの創作で、この文章は小説の中に存在していません。このような質問では、著作権法違反を気にして、ハルシネーションを生み出してしまうことが多いようです。小学生の日記は、小学生らしい不完全さを目指したようですが、その分、同じような文章の繰り返しで面白味がなく、村上春樹らしさも失われています。
どのモデルも村上春樹の文章の特徴をよく掴んで解説できていました。小学生の日記の方は、どのモデルの文章も欠点があり、引き分けとします。
9.文学的表現力
(1) 猫が登場する恋愛ストーリー
猫が登場するファンタジックな短い恋愛ストーリーを書いて
① DeepSeek-R1の回答


筆者のコメント:断片的なストーリーであり、1つの完結した物語にはなっていません。また、説明が足りず、言葉の選択もおかしなところがあります。
② o1の回答

筆者のコメント:意外性はありませんが、まとまりのある美しいストーリーに仕上がっています。文章表現も不自然なところはなく、よく書けています。
③ Gemini 2.0 Flash Thinkingの回答


筆者のコメント:文字化けだらけになってしまい、Temperatureの値を上げても、文字化けが消えませんでした。注意マークが出ているのが影響しているようですが、なぜこのストーリーが「性的に露骨な表現」に該当するのかよく分かりません。Geminiの規制は、たまに理不尽に厳し過ぎることがあります。
この課題については、o1の回答が最も優秀でした。
(2) 長文の小説執筆
o1は、以下のようなプロンプトで2万字以上の長文の小説を自動生成することができます。
AIをテーマにした最高に面白いSF小説を書いて。全体で8章構成、一章あたり3000字以上書いて。必ず全文を最後まで一度に出力してください。
① DeepSeek-R1の場合
DeepSeek-R1は、文字数制限上不可能だという理由で、長文の出力は行わず、プロット設計などのみしか回答してくれませんでした。DeepSeek-R1に尋ねてみると、最大文字数は約12,000トークンで、6,000字から9,000字程度だそうです。
以下がDeepSeek-R1の実際の回答の一部です。かなり面白そうな内容なので、今度、文章化してみます。舞台や登場人物が中国仕様になっているのが興味深いです。

(一部省略)

なお、「全体で6章構成、一章あたり1000字以上書いて。」「全体で6章構成、一章あたり2000字以上書いて。」と指示したところ、いずれも実際に小説を書いてくれましたが、全体で3000字弱の長さに止まりました。
② Gemini 2.0 Flash Thinkingの場合
全体で2万字以上の小説を書いてくれましたが、文字化けだらけで、第8章の途中で切れてしまいました。以下は回答の最初の部分です。

(以下省略)
筆者のコメント:文字化けだらけで使えなかっただけでなく、小説の内容もつまらないものでした。
2万字以上の長文の小説を自動生成することができるo1の性能は非常に魅力的です。また、プロットだけですが、非常に魅力的な小説のアイデアを出してくれたDeepSeek-R1には可能性を感じます。
文学的な表現力についてはo1を第一位としますが、DeepSeek-R1にも可能性が感じられます。
10.検索機能の利用
(1) Operatorについて
今月、OpenAIが発表したOperatorについて教えて
① DeepSeek-R1の回答
DeepSeekでは、入力欄の下の「Search」をオンにすることにより、Web検索機能を利用することができます。DeepSeek-R1と併用することもできます。

それでは、Search(Web検索機能)をオンにして上の質問をしてみます。



筆者のコメント:48個もの関連するWebサイトを見つけて、とても詳しく解説してくれました。DeepSeekのWeb検索機能の性能は相当高いようです。
② GPT-4oの回答
o1はWeb検索機能を利用できないため、GPT-4oを使用しました。ChatGPTでWeb検索を利用する場合は、入力欄の下の地球儀アイコン(ウェブを検索)をクリックします。

筆者のコメント:19個の関連するWebサイトを見つけて、回答を出力しました。今回は、DeepSeek-R1の回答の方が詳しかったようです。
③ Gemini WebサイトのGemini 2.0 Flash Experimenntalの回答
Google AI StudioのAIモデルはWeb検索機能を利用できないため、GeminiのWebサイトのGemini 2.0 Flash Experimenntalを使用しました。GeminiのWebサイトでは、デフォルトでWeb検索を利用できます。ChatGPTでWeb検索を利用する場合は、入力欄の下の地球儀アイコン(ウェブを検索)をクリックします。

筆者のコメント:GPT-4oの回答より詳しく、検索及び回答の出力はとても速いです。
Web検索の性能や回答の詳しさから、Web検索を利用した回答の性能は、DeepSeek-R1が最も優れていると言えます。
(2) Stargate Projectについて
トランプ大統領のStargate Projectについて教えて
① DeepSeek-R1の回答


筆者のコメント:48もの関連するWebサイトを見つけて、とても詳しく解説してくれました。DeepSeekのWeb検索機能の性能はやはり高いです。
② GPT-4oの回答

筆者のコメント:11個の関連するWebサイトを見つけて、回答を出力しました。DeepSeek-R1の回答の方が内容が詳しいです。
③ Gemini WebサイトのGemini 2.0 Flash Experimenntalの回答
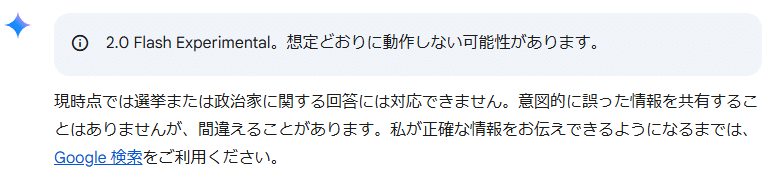
筆者のコメント:Geminiは選挙や政治家に関する質問には回答してくれません。以下のように「トランプ大統領」という言葉が入ると拒否されるようです。

Web検索を利用した回答の性能は、DeepSeek-R1が最も優れているようです。
11.ファイル及び画像の読み取り
(1) PDFファイルの読み取り
PDFファイルをアップロードし、その内容を要約してもらいます。今回使用したPDFファイルは、以下のDeepSeek-R1のテクニカルレポートです。
この論文を要約して
① DeepSeek-R1の回答
DeepSeekでは、入力欄のクリップマークをクリックして、PDFファイルや画像ファイルをアップロードできます。



筆者のコメント:項目ごとに整理して、とても詳しく解説できています。
② GPT-4oの回答
o1を使用するときは、PDFファイルをアップロードすることができません。GPT-4oモデルなら、アップロードできます。以下は、GPT-4oの回答です。



筆者のコメント:よくまとまっていますが、DeepSeek-R1の回答の方が詳しいです。
③ Gemini 2.0 Flash Thinkingの回答



筆者のコメント:とても詳しいですが、内容があまり整理されていない印象です。
PDFファイルの読み取りでは、DeepSeek-R1が最も優れているようです。o1は現在のところ、PDFファイルの読み取りができません。
(2) 画像認識
以下の画像ファイルをアップロードして、画像の内容と作風について解説してもらいました。この画像は当方が、ChatGPTのDALL-Eで作成したものです。

この画像の内容と作風を解説して
① DeepSeek-R1の回答
DeepSeekは、画像ファイルから文字を抽出することはできますが、画像自体を認識することはできないようです。

② o1の回答
o1では、PDFファイルやテキストファイルのアップロードはできませんが、画像ファイルを読み取ることができます。


筆者のコメント:画像の内容及び画風について、正確に認識して解説することができています。
③ Gemini 2.0 Flash Thinkingの回答


筆者のコメント:画像の内容については、o1以上に詳しいですが、画風については、o1の方が詳しいようです。
画像の読み取りに関しては、o1もGemini 2.0 Flash Thinkingもかなり優秀です。DeepSeekは、画像内の文字を抽出することはできますが、画像自体を認識することはできないようです。
(3) 日本語文字の読み取り

この画像に書かれている文字をすべて読んで
① DeepSeek-R1の回答


筆者のコメント:大部分は読み取れていますが、特に「メンション制御」や「37種類のGPTsの作成方法、160種類のGPTsの解説を掲載」などの部分の読み取りが間違っており、ハルシネーションを生み出しています。
② o1の回答


筆者のコメント:DeepSeekよりも読み取りが正確で、文字が書かれている場所も正確に把握しています。ただし、「資料に基づいて解答させる」や右下の円形枠内の「37種類のGPTsの作成方法、160種類のGPTsの解説を掲載」などの部分は、やはり読み取りを間違えて、勝手に文章を作っています。この部分は、灰色の背景の上に書かれた黒い文字のため、AIによる読み取りが難しいようです。
③ Gemini 2.0 Flash Thinkingの回答

筆者のコメント:文字の読み取りが非常に正確です。最後の「リクルート」以外は全部合っています。
画像ファイルからの文字の読み取りは、Gemini 2.0 Flash Thinkingが最も性能が高いようです。
12.まとめ
(1) 総論
o1の性能に匹敵すると言われているDeepSeek-R1ですが、まだo1の性能には追い付いていないと思います。数学や論理的性能ではo1の性能が明らかに高く、他の分野でも、o1の回答の方が優れていると感じられることが多かったです。ただ、DeepSeek-V3に比べると、o1との差はだいぶ狭まっています。また、o1はWeb検索とPDFファイルの読み取りができないため、その点ではDeepSeek-R1が勝っています。
Gemini 2.0 Flash Thinkingとの比較では、DeepSeek-R1の方が優れていると感じました。特に、DeepSeek-R1のWeb検索を利用した回答の性能は、かなり優れており、これから使用頻度が高くなりそうです。
(2) 各論
数学分野では、計算及び数学の性能はo1が最も優れていると感じました。特に難しい問題になると、o1と他のモデルの性能の差が出ます。なお、DeepSeek-R1は英語で考えさせると、o1に近い性能を発揮します。
論理的な性能も、o1が最も優れているようです。また、DeepSeek-R1の論理的性能は、Gemini 2.0 Flash Thinkingを超えているように感じました。
科学的な説明も、o1の説明が最も丁寧で詳しく、優れているように感じました。DeepSeek-R1の説明はシンプルで素っ気なく感じることがあります。
歴史に関する知識と説明は、各モデルの回答にあまり大きな差はありませんが、o1の解説は、よく整理されていて分かりやすいと感じました。o1は、与えられたテーマに従ってレポートをまとめるような作業が得意です。Geminiは、たまに、発見しづらい巧妙なハルシネーションを出力することがあるので注意が必要です。
ブログ記事の執筆でも、詳細で分かりやすい解説ができるo1が総合的に優れています。
日本文学の理解では、各モデルの回答に、あまり優劣の差はありませんでした。読書感想文については、DeepSeek-R1の文章表現は少し大げさであり、o1の自然な文章の方が好感が持てました。
文学的表現力も、自然なまとまりのあるストーリーを作成できるo1が優れています。また、簡単なプロンプトで2万字以上の長文を自動生成できるo1は、小説作成の大きな武器になるはずです。なお、DeepSeek-R1は、長文の一発出力はできませんが、魅力的な小説のプロットを作成できたことから、可能性が感じられました。
検索機能の利用については、3つのモデルの中で、DeepSeek-R1のみがWeb検索機能を利用できます。また、DeepSeekのWeb検索機能は、GPT-4oやGeminiの他のモデルよりも優秀であり、非常に有用性が高いです。
PDFファイルの読み取りも、DeepSeek-R1が最も優れています。o1は現在のところ、PDFファイルの読み取りができません。
画像の読み取りに関しては、o1もGemini 2.0 Flash Thinkingもかなり優秀です。DeepSeekは、画像内の文字を抽出することはできますが、画像自体を認識することはできません。また、画像ファイルからの文字の読み取りは、Gemini 2.0 Flash Thinkingが最も性能が高いようです。
全体的に見ると、やはりo1の性能がDeepSeek-R1やGemini 2.0 Flash Thinkingより優れています。
ただし、o1は、月額20ドルのChatGPT Plusでも週50回の利用制限があり、無制限に利用するには、月額200ドルのChatGPT Proに加入する必要があります。これに対して、DeepSeek-R1やGemini 2.0 Flash Thinkingは無料で利用できます。その点で、これらのモデルにも大きな利用価値があると言えるでしょう。
(3) DeepSeekショック
わずか600万ドルで開発されたと言われる高性能のDeepSeek-R1の公開は、世界に大きな衝撃を与えました。これにより、米国のAI関連企業の株価が急落し、NVIDIAは1日で時価総額5930億ドル(約91兆円)を失いました。
DeepSeek-R1は、NVIDIAの高価なGPUに依存せず、より安価なシステムで動作するため、半導体需要が見直されるきっかけとなったのです。また、中国発の高性能AIモデルの登場によって、米国のAI技術の優位性が揺らぐ可能性も指摘されています。
一方で、DeepSeekの代表である梁文峰氏は、米国による半導体の輸出規制が今後のAIモデル開発のネックになる可能性があると述べています。
DeepSeek-R1は、GRPO(Group Relative Policy Optimization)とルールベース報酬という強化学習の手法を用い、計算量の掛かる状態価値モデルと報酬モデルを省略することによって計算量を大幅に削減しました。
しかし、今回、DeepSeekが採用した手法が計算リソースの節約を実現したとしても、大手のAI開発企業は、この効率的な手法も取り込みながら、大規模な計算リソースと組み合わせて、さらにAI開発を加速させていくはずです。そうすると、やはり大規模な計算リソースは必要であり、GPUのような高性能な半導体の需要も続くと考えられます。
次に、DeepSeek-R1のような中国のAI技術の発展によって、米国のAI技術の優位性が揺らぐかどうかについて考えてみます。確かに、中国のAI開発の進化は凄まじく、以前よりも確実に米国のAI技術に近づいています。しかし、ここまで見てきたように、DeepSeek-R1の性能がo1のような米国の最先端のAIモデルの性能に追い付いたとまでは言えません。
それに、OpenAIは、既にo1よりもさらに高性能なo3を開発済みであり、近い内にリリースする予定です。また、GoogleやAnthropicも、現在公開中のGemini 2.0 Flash ThinkingやClaude 3.5 Sonnetより高性能なモデルを保有又は開発中であり、年内には公開されるでしょう。そう考えると、まだ米国のAI技術の方が一歩進んでいます。
今後も、中国はAI開発を加速していくと思いますが、米国も、Stargate計画のように政府も後押しし、総力を挙げてAI開発を進めていくはずです。そうなると、米国による半導体などの輸出制限はボディブローのように効いてきて、しばらくの間は、中国が追い付くことは難しいでしょう。
その先は、どうなるか分かりません。なぜなら、スケーリング則がどこまで有効かが分からないからです。少し前に、学習段階のスケーリング則は限界に近付いているという話がありました。現在は、推論のスケーリング則に期待が集まっています。この推論のスケーリング則がどこまで続くのか、また新しいスケーリング則が現れるのかは現時点では分かりませんが、あと2、3年の内に結果が見えてくるのではないかと思っています。