
Explore Package R 〜変数の概要をみる

データ分析をするときは、まず探索的データ分析(EDA: Exploratory Data Analysis)を行いますが、今回ご紹介するExplore packageはこれを簡単かつ迅速におこなえるツールです。
EDA: Exploratory Data Analysisとは
探索的データ分析(EDA: Exploratory Data Analysis)とは、データセットの特性を理解し、パターン、異常、仮説、相関関係などを発見するための分析手法です。EDAはデータ解析プロセスの初期段階で行われることが多く、データの可視化や要約統計量を利用してデータを理解し、さらなる解析やモデリングの方針を決定するための重要なステップです。
EDAの主な目的と手法
データの概要を把握する: データセット全体の構造や分布を理解します。
異常値や欠損値の確認: データに存在する異常値や欠損値を特定し、対処方法を検討します。
パターンの発見: データの中に存在するパターンや傾向を見つけます。
仮説の生成: データに基づいて仮説を生成し、後の分析やモデリングに役立てます。
相関関係の確認: 変数間の相関関係を調べます。
Explore packageとは
Explore packageでできることはたくさんありますが、今回は以下の4つをご紹介します。
データフレームの概要表示: データフレームの基本的な統計情報を簡単に取得できます。
視覚化: 数値データやカテゴリカルデータをさまざまなグラフ(ヒストグラム、ボックスプロット、バープロットなど)で視覚化できます。
相関分析: 数値変数間の相関を視覚化し、相関行列を表示できます。
データクリーニング: 欠損値の確認や処理、異常値の検出など、データの品質を向上させるための機能を提供します。
インストールと読み込み
まずはExplore packageをインストールして、読み込みます。
install.packages("explore")
library(explore)Penguinsデータの読み込み
データはpenguinsを読み込みます。Exploreにはuse_data_から始まる関数が準備されていて、irisやpenguins, diamondsなど有名なデータセットが読み込めます
penguins <- use_data_penguins()概要をみる
それではさっそく概要を見てみましょう。explore()でshinyの別ウインドウが立ち上がり、マウス操作で各変数の分布がみられます
一変数の概要をみる

ここではspeciesの3つの種別 Gentoo、Chinstrap,Adelieの割合が棒グラフで表示されています。naの数やユニークな値の数もわかります。
連続変数の場合はこのように表示されます。分布がわかりやすいですね。

上のタブのoverviewを選ぶと、各変数の要約が表形式でみられます。一気に全部見たいときはこちらが便利です。

二変数の関係
penguinsデータセットはくちばしの長さや幅、足の大きさ、体重などからどの種別化を見分けるためのデータセットです。
くちばしの長さと種別の関係を見てみましょう。variableにbill_length_mmを、targetにspeciesを選びます。
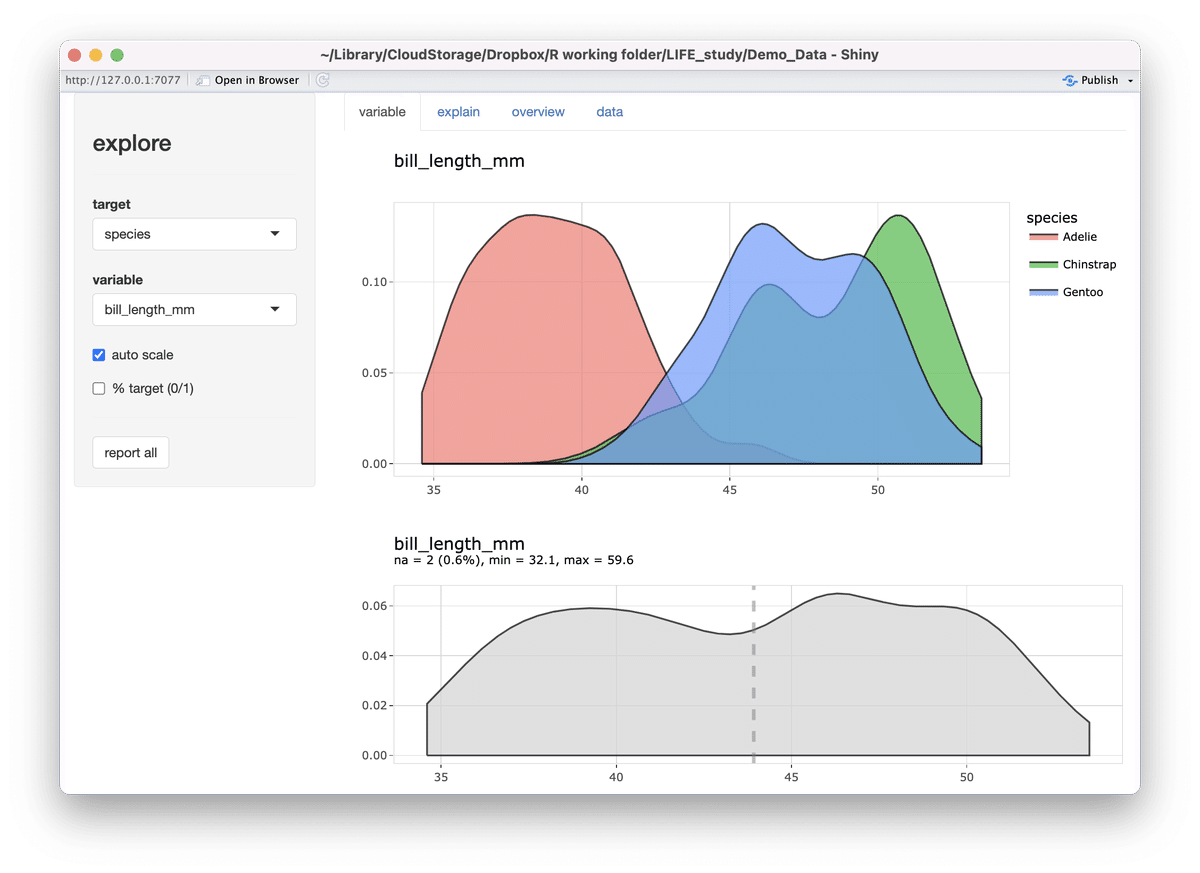
bill_length_mmだけの分布に加えて、種別ごとのbill_length_mmが表示されました。これをみるとAdelieペンギンはくちばしの長さが他の2種より短く、43mmあたりである程度の区別ができそうです。
こんどはくちばしの長さ(bill_length_mm)とくちばしの厚さ(bill_depth_mm)の関係を見てみましょう。
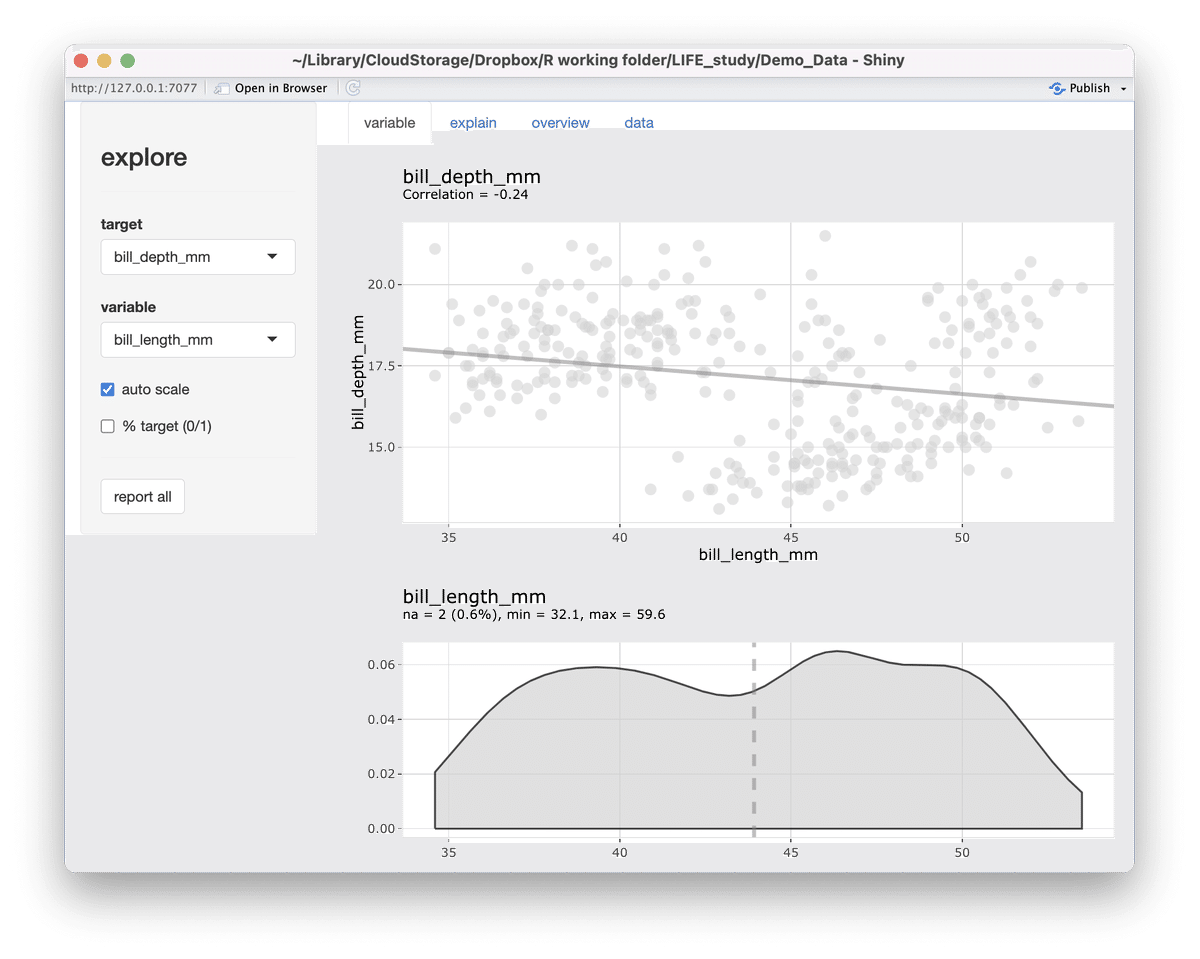
targetにbill_depth_mmwを選びます。すると散布図と相関曲線が示されました。左上に相関係数(-0.24)も表示されています。
次にfactor同士の関係です。varableをisland、targetをspeciesに指定します。

変数islandには3つの島が含まれていますが、ChinstrapペンギンはDream島、GentooペンギンはBiscoe島にしかいないようです。またTorgersen島にはAdelieペンギンしか住んでいないことがわかります。
終わりに
今回はEDAをマウスで簡単に行えるExplore packageで、変数の概要をみる方法を紹介しました。EDAはデータ分析の基本ですが、これがサクサクとできると嬉しいですね。
次回はさらに詳しい分析について説明しますので、お楽しみに!