
平常時の時系列数値データを学習!?企業システムの障害を早期に検知!①

今、企業収益の増加や企業の差別化、顧客からの支持獲得などで、ビジネスにおいて優れたアプリケーションの重要性が非常に高まっています。
その一方で、企業活動を支えるアプリケーションと、それを支えるインフラ環境は非常に複雑化して、運用・監視の観点でも同様に複雑化してきていることは共通の認識ではないでしょうか。
多くのIT 部門が直面している主要な問題は、現代の企業が絶えず処理しているさまざまなソースからの膨大なデータを、従来の監視方法やデータ分析の手法では十分に監視できないことです。
この問題に対してIBM では、企業システムにおける最新のさまざまな運用・監視ソリューションをご提供しています。この記事では、そのうちの1つのアプローチとして、単変量解析(ベースライニング)、多変量解析(多変量間相関分析)、の統計数学モデルから異常な挙動を検知する仕組みについてご紹介したいと思います。
従来の監視と言えば、ログ監視やプロセス監視などが挙げられると思いますが、今回ご紹介する監視方法は、IT 資産から出力される”時系列の数値データ”を活用して、グラフ解析からシステム監視をするアプローチになります。”時系列数値データ”の例として、タイムスタンプとCPU使用率、メモリー使用量、inOctets などの数値が挙げられます。
単変量解析と多変量解析は統計に詳しい方は既にご存知かと思いますが、それぞれどのように異常検知する仕組みなのか見ていきたいと思います。
①単変量解析による検知
システムから出力されるデータの中から単一の変量(メトリック)の挙動に着目するアプローチで、下図の通り、正常値域を確率分布に基づいてベースライン(下図の緑部分)を導き出して、このベースラインから逸脱した時に障害検知する仕組みです。

通常の閾値監視と比較して何が良いか?
「閾値監視」の場合、常に閾値を超えるようなピークに差し掛からないと、異常を検知することができない仕組みになっています。例えば、夜中と昼間では監視する数値データの動く範囲は異なると思います。通常、データの値が低い時間帯に、通常時と異なる値で推移していた場合、閾値になるまで検知することができません。
また、閾値は人がこれまでの経験から考えなければならないこともポイントです。
一方で、単変量解析(動的な閾値)は過去の傾向を元に、ベースラインから逸脱した段階で検知して、障害が顕在化する前に、異常な挙動を検知することができる仕組みになっています。
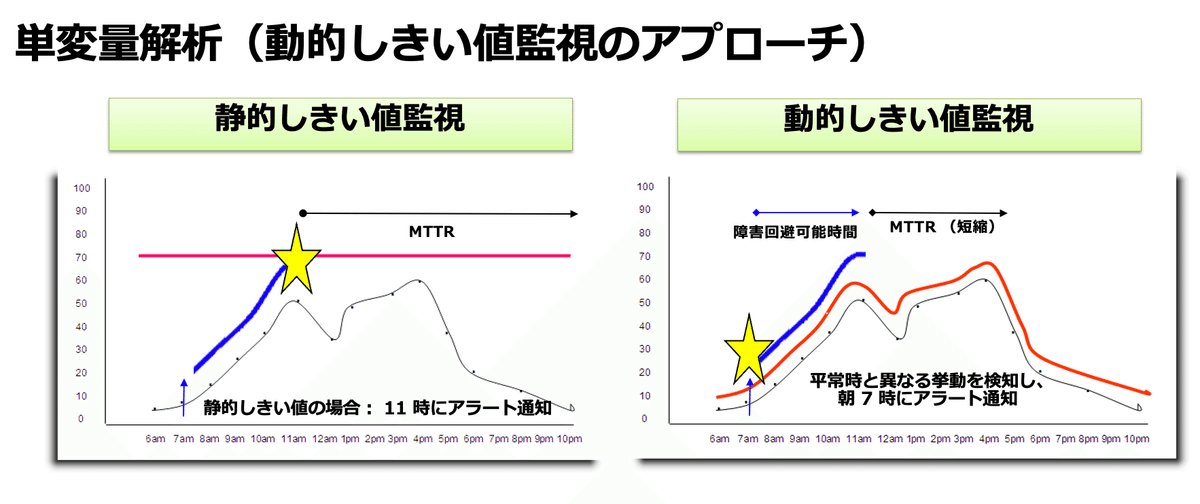
絶対止められないシステムなのに「閾値監視」しかしていない、ということはないでしょうか!?単変量解析(ベースライニング)とこの後にご紹介する、多変量解析(多変量間相関分析)、から異常な挙動を検知する仕組みを取り入れることで、障害を未然に防ぐことができるかもしれません。
単変量解析の主な異常検知パターンをこちらの通り。
主な異常検知パターン①:ベースライン
過去のデータを学習させて、平常時のメトリックの変化のパターンからベースライン(下図の緑部分)を作成し、ベースラインから逸脱した時に障害検知する。閾値を動的に設定することで、アラートの精度を向上させることができます。

主な異常検知パターン②:変動量の縮小
ベースラインに収まっているが、変動幅が減少した場合に異常として検知する仕組み。
検知例:以下はメモリリークによりメモリ領域が開放されないためJVMメモリ使用量が低下する例。

主な異常検知パターン③:フラットライン
データの変動がなくなった場合に異常として検知する仕組み。
検知例:サービス停止やボトルネックなど

この続きの多変量解析やIBM のソリューションの詳細については、別の記事で改めてご紹介していきたいと思います。
IBM Cloud Pak for Watson AIOps
IBM では、企業システムの平常時の”時系列の数値データ”の挙動を学習させて早期に多くの障害を検知することが可能なソリューションとして、"
Metric Manager" をご提供しています。
監視ツールやファイルから性能情報を読み込み、平常時の挙動(パターン)学習を行うことで、人間が気付くことができないシステム異常(アノマリー)を早期に検知することができます。
Metric Manager は、IBM Cloud Pak for Watson AIOps のコンポーネントの1つとして提供しています。単体で利用いただくこともできますし、他の運用監視のコンポーネントと組み合わせて運用高度化を進めることもできます。IBM Cloud Pak for Watson AIOps については、こちらで紹介されています。ぜひご覧になってみてください。
当記事に少しでもご興味お持ちいただき、さらに詳しい情報をお知りになりたい場合は、ぜひ下記アンケートよりお気軽にお問い合わせください。
ご記入いただいた方には、貴社の今後のDX変革にお役立てできるIBM の最新情報をお届けします!
どうぞよろしくお願い申し上げます。フォロー&記事のシェアをしていただけますと幸いです。