
レコメンドくらいがAIとの距離感としてちょうど良い

Stockmark Advent Calendar 2022 の21日目の記事です。
内容は上のタイトルとは少ししか関係ないです。今回はこれ。
グラフDBで協調フィルタリングによるレコメンドをさっと試す
ここ半年ほど、社内有志の「推薦システム実践入門」読書会に参加してました(主宰の@kamataに感謝)。Anewsの本質的な価値にあたることもあり、基礎を網羅的に把握できたのがとても良かったので、続きで試したことと、内容の補足を前後編に分けて残しておこうかと思います。
[前編] 試した内容の記録
きっかけ
読書会も終盤に差し掛かった頃、Anewsで読んだこちらの記事でグラフDBを思い出し、協調フィルタリングと相性良いんじゃね?と思い立ちまして。

いずれNeo4j触ろうと考えてたのでグッドタイミング。そしてドンピシャのチュートリアルを発見。
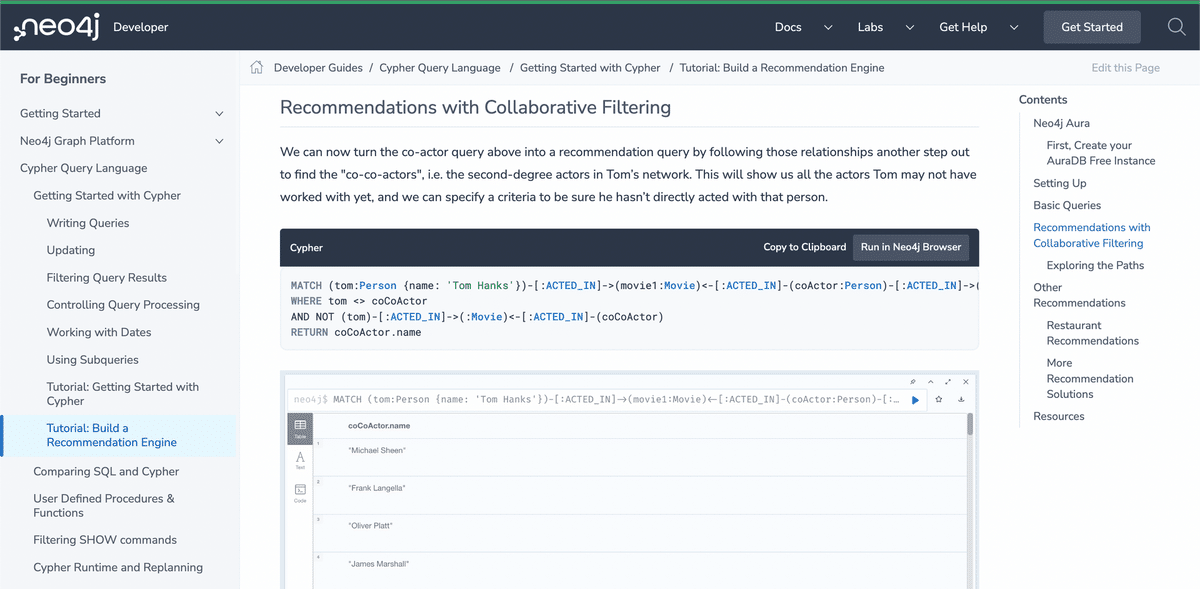
データを決める
せっかくなんで書籍で使われていた映画評価のDataset(MovieLens)ではない、他の推薦に使えそうな(評価データがある)Datasetを探してたら、Kaggleに良さげなものを発見。映画と同じくらいわかりやすい。
Anime Recommendations Database vol.2

Animeデータは15,221件。Ratingデータをみたら86,954ユーザーによる11,039,694件もの評価があったので、上位1,000IDまででカットしました。
ということで準備OK。
シンプルな協調フィルタリングの例
環境としてはAuraDBを使ってクラウド上で動かしました。
細かい手順は省略しますが、初めてでも数十分程度でクエリの結果をグラフで表示できるようになりました。
とりあえず「鬼滅の刃」が好きという体で試してみますー
「鬼滅の刃」を評価している人: 45人
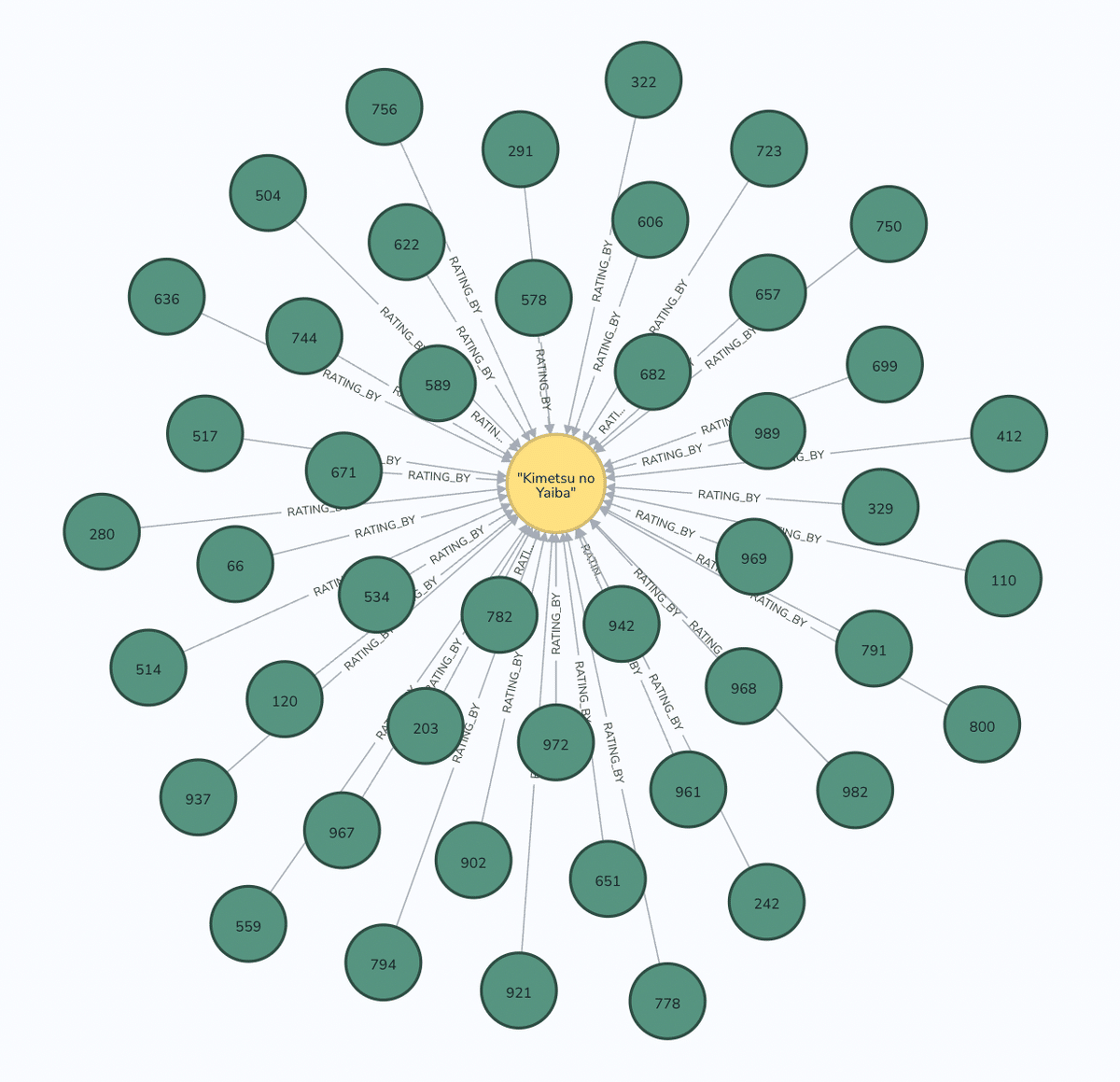
評価値(Rating)の分布: 10点評価したユーザーが10人

鬼滅の刃を10点評価している人が、他に10点評価しているアニメ: 481件

上記の評価人数順でのトップ10

上記のクエリ(Cypher)
MATCH (n:anime {title: 'Kimetsu no Yaiba'})-[r]-(m:reviewer)-[r2]-(n2:anime)
WHERE r.rating = 10 AND r2.rating = 10 AND n.anime_id <> n2.anime_id
RETURN n2.title, count(n2) AS frequency
ORDER BY frequency DESC
LIMIT 10という感じで、シンプルに記載でき、処理時間も数秒で出せちゃいました。推薦結果に対してPrecisionやRecallなど数値指標では検証はしてませんが、パッと見では大ハズレはしていないですかね。
前編はここまで。
※ 弊社プロダクトに実装されるとは限りません
[後編] 補足説明
以降はFAQ形式でのお勉強?コンテンツですー
社内のBizやCorpのメンバーに目を通してもらえるとうれしい。
推薦システムって? 検索とはどう違うの?
いずれも「たくさんあるアイテムから価値あるアイテムを選ぶ」仕組みですが、ユーザーの状態や目的が異なり「Pull型」「Push型」として説明されることが多いです。

パーソナライズでは分類しきれず、例えばgoogle検索はユーザーの各種情報から検索結果を変えていますし、推薦には人気度ランキングなどの画一的なものも含まれます。
協調フィルタリングって?
推薦アルゴリズムは大きく「内容ベースフィルタリング」と「協調フィルタリング」の2つに分類できます。
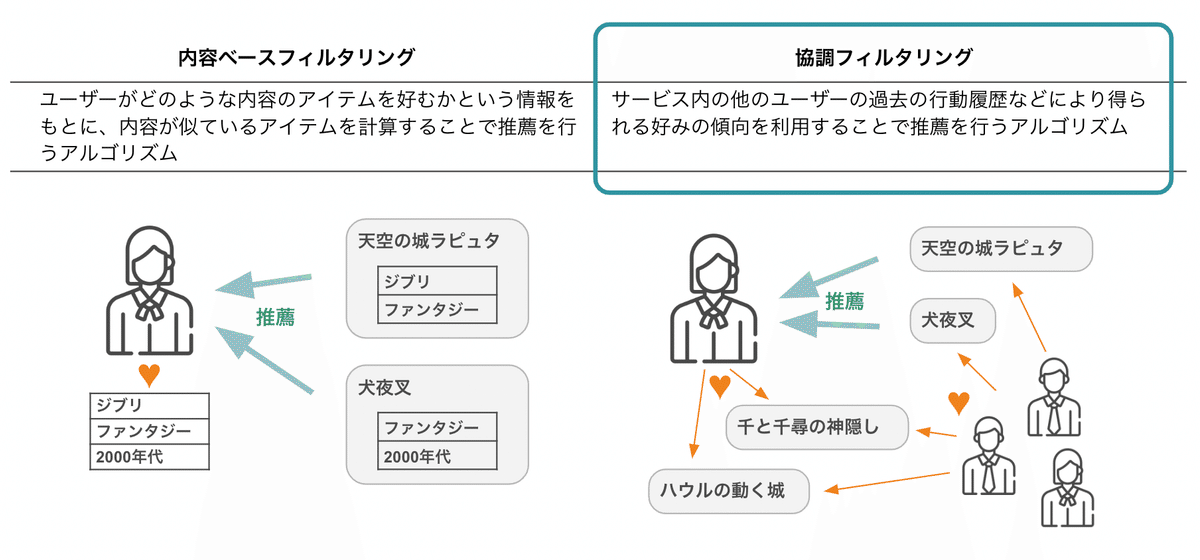
それぞれ得意不得意があり、またアルゴリズムも様々ですが、書籍ではPrecisionやRecallなどの指標を使いながらGoogle Colab上ですぐ動かせるようになっており、深く理解したい人にはおすすめですー
PrecisionとRecallって?
ここではランキング指標として下記のように使っています。

なお社内での実務上は、ユーザーの集合に対してランキング上位の記事が閲覧されているかを評価するために、MAP@k(Mean Average Precision)を使っています。
グラフDB(データベース)って?
データや関係性の持ち方について、一般的なデータベース(リレーショナルDB)はテーブル(表)構造、グラフDBではグラフ(ネットワーク)構造になっているとざっくりイメージしておけば良いかなと。

技術的な特徴は多数ありますが、1番の利用メリットは、リレーショナルDBでは時間がかかり過ぎてしまうJOINが多発する複雑なクエリも、グラフDBなら高速に実行できる点となります。
DB界隈においても、近年ずっと注目されていたりもします。下記はUSの有名なDB情報サイトの人気度の推移。
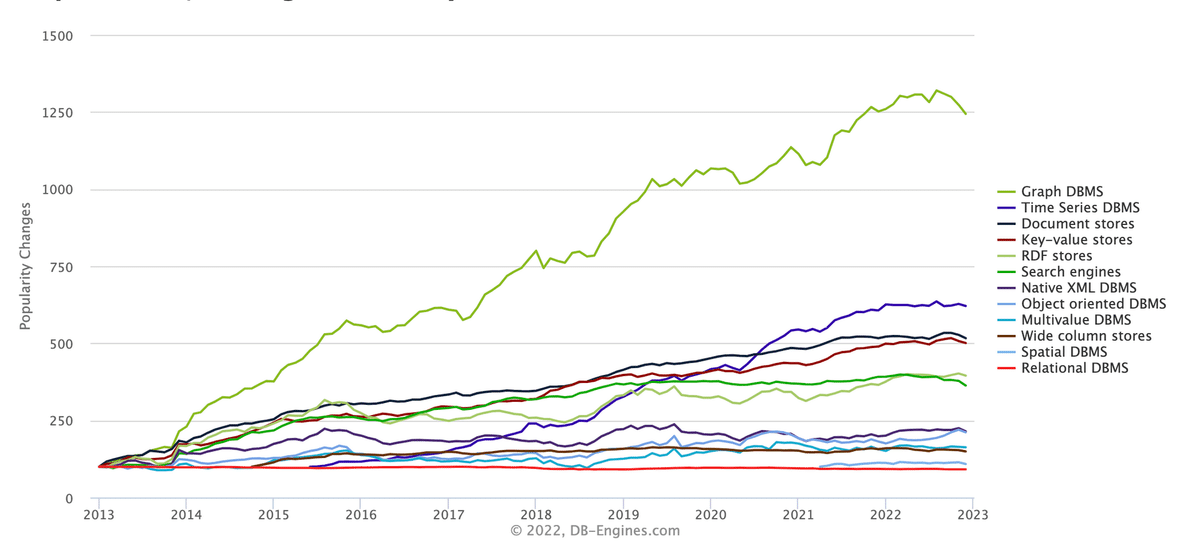
Neo4jって?良いの??
グラフDBとして上記DB情報サイトでも最も人気があり、利用企業やエンジニアの数や情報量の多さ、コミュニティの活発さなどからも、ファーストチョイスになるかなと思います。

ただしグラフDBを何らかプロダクトに実装する場合は、きちんと選定プロセスを踏んでおきたいところ。個人的にはRedisGraphの資料にあるこのグラフがとっても気になってます。

これをみてRedisGraph試そうと思ったんですが、CSVからデータ作る手順が面倒だったので今後にまわしましたw

今回はここまでとなります。
※ 弊社プロダクトに実装されるとは限りません
あとがき
詰め込みすぎましたw
Advent Calendar、他のメンバーの投稿もぜひご覧くださいー