
ノーコードAIツールで予測するたこ焼き屋さんの客層|第2回 客層データからAIをつくる

こんにちは!ヒューマノーム研究所でインターンをしている佐藤です。
たこ焼きってなんであんなに美味しいんですかね?
たこ焼きパーティーで、タコじゃないものを入れて焼いて、ロシアンルーレットみたいにした方は結構いるのではないでしょうか。
さて、この連載ではたこ焼き屋の売り上げデータについて、当社が開発するHumanome CatData(以下CatData)を使って分析しています。前回はたこ焼き屋の客層について可視化をし、分析・考察をしました。このデータの傾向については前回の記事をご覧ください。
今回は、前回と同じデータを使ってAIモデルの学習を進めます。 CatDataを使うと、データの前処理からAIモデルの学習まで、プログラムを書くことなく実施できます。このあと、下記の手順でたこ焼きの販売数を予測するモデルを作成してみます。
前処理(モデルの学習に不必要な情報の削除やデータの分割など)
たこ焼きの販売数(n_takoyaki)を予測するモデルの学習
AIレクチャー機能を利用したモデルの評価
CatDataは、無料で大部分の機能が利用できます。アカウントをお持ちでないようでしたら、ぜひお試しください!
学習前の準備:解析に不要なデータを削除する
AIモデルの「学習」は、人間が学習する時と同様、AI自身がデータを学習するプロセスのことを指します。AIは、データの統計的分布から見出した特徴や規則性を学びます。
学習を行う上でのポイントなどについては下記の記事で説明しています。
さて、学習に入る前にデータの編集を行います。ここでは、前回作成した可視化テーブルを元にして、列の削除と学習用テーブルと予測用テーブルに分ける操作を行います。削除する列は以下のとおりです。
“ID”
”n_pack”
”sales”, ”sales_takoyaki”, ”sales_negi”
また、それぞれを削除する理由は以下の通りになります。
“ID”:お客さんのナンバリング。たこ焼き購入数とは関係ないので削除
”n_pack”:ふつうのたこ焼き(”n_takoyaki”)とねぎたこ(”n_negi”)を購入した個数の合計値。どちらかを予測したい時、もう片方の個数が分かると個数がすぐ分かってしまうので削除。
”sales”, ”sales_takoyaki”, ”sales_negi”:
”sales_takoyaki”はふつうのたこ焼きの売上、”sales_negi”はねぎたこ焼きの売上、”sales”は各お客さんの売上
双方ともに、お客さんが買ったたこ焼きの個数(n_takoyaki, n_negi)に準じて値が変動します。
”sales_takoyaki”, ”sales_negi”はお客さんが買った時に分かる要素であり、”n_takoyaki”, ”n_negi”の予測時に入れることができないため削除。
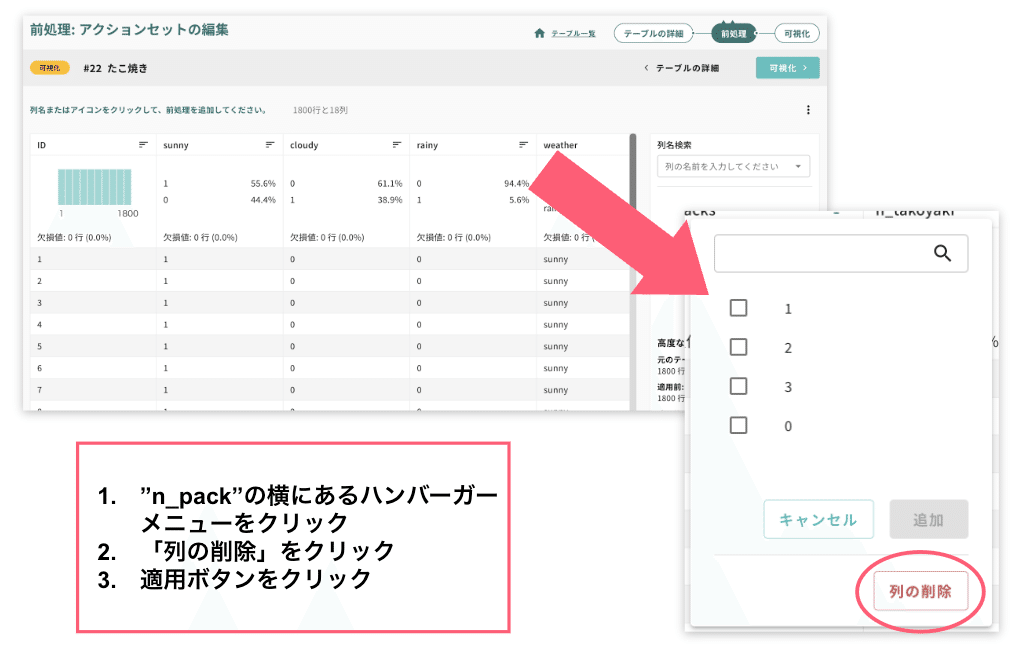
まず、”sales”、”sales_takoyaki”、”sales_negi”、”n_pack”を削除します。操作は以下の通りです(図1)。
前回作成した可視化用テーブルを選択し、前処理:アクションセットの編集の画面を開く
”sales”の横にあるハンバーガーメニュー(3本線の記号)をクリック
「列の削除」をクリック
”sales_takoyaki”、”sales_negi”、”n_pack”も同様の操作をする
適用ボタンをクリック
ハンバーガーメニューをクリックすると、列の削除だけではなく、欠損値の個数、平均値、標準偏差、四分位点を確認することもできます。
学習前の準備:学習用と予測用テーブルを作成する
次は、可視化用テーブル(表データ)を分割し、学習に使うテーブルと予測精度を確認するときに使うテーブルを作成します。今回は、”ID”で範囲を指定し、1〜1350を学習用テーブル、1351〜1800を予測用テーブルとして切り分けてみます。
学習用テーブルの作成方法
”ID”の横にあるハンバーガーメニュー(3本線の記号)をクリック
”ID”の範囲を1~1350に設定し、追加をクリック
1と同様に、”ID”の列のハンバーガーメニューをクリックし、を削除をクリック
「適用」ボタンをクリック
画面右上のプルダウンメニューから「複製して新規テーブルを作成」をクリック
左上の猫のマーク(CatDataのロゴ)をクリックし、ホーム画面に戻る
新たにテーブルが作成されているので、それを選択する
「利用目的の選択」ボタン→「このテーブルの利用目的の選択」→「学習」と順番にクリックし保存しする

データの学習
学習用テーブルを作成すると、自動的に「前処理:アクションセットの編集」と表示されている画面に移動します。画面右上にある「確認」→「学習」の順でボタンをクリックした跡に表示されるアラート「前処理方法が変更ができなくなります。」内で「はい」をクリックすると「学習」を実施する画面に移動します。
「学習」では以下の操作を行います(図3)。学習開始後、しばらく待つとAIモデルが作成されます。
「モデルの新規作成」をクリック
「予測対象の列」を今回予測する「n_takoyaki」に設定
「手法:Random Forest」であることを確認
「モデル評価用に学習データと評価データに分割」がonになっていることを確認
「学習開始」をクリック

AIモデルの評価を確認する
学習が終わったら「評価結果」をクリックします。
遷移先の「評価結果」画面では、”混同行列”と”変数の重要度”、そして”AIに解説してもらう(β)”が表示されます。
混同行列でモデルを評価する
まず、混同行列でモデルを評価していきます(図4)。
混同行列で精度を確認する方法は、こちらの記事で詳しく説明しています。ぜひご覧ください。
混同行列では、予測値と実測値の比較を確認することができます。
学習データの精度は0.85771、テストデータの精度は0.82249となっており、どちらも高い精度であることが分かります。

変数の重要度でモデルを評価する
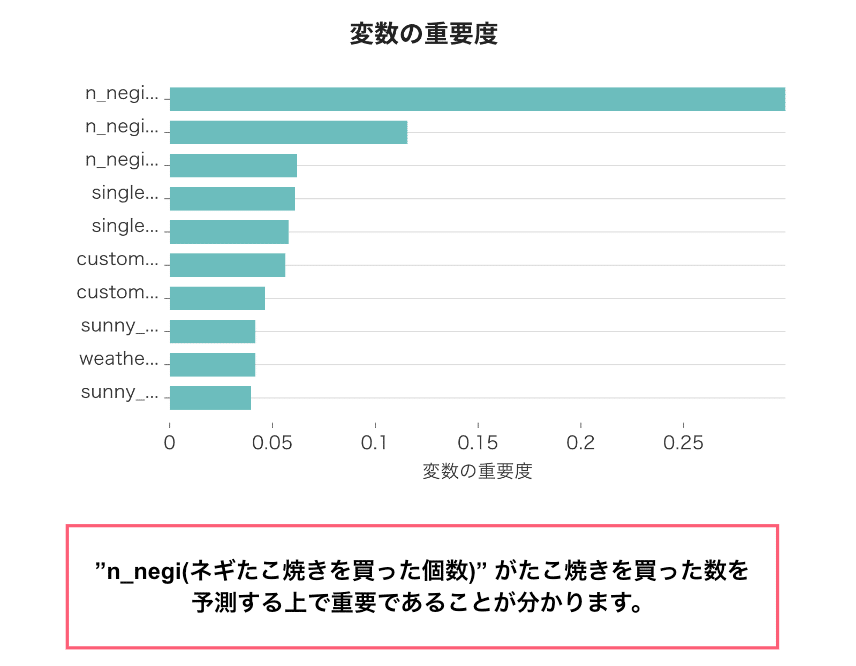
次に、変数の重要度を見ていきます(図5)。
変数の重要度では、学習した時にモデルが何を重要視して学習を行ったのか?について確認できます。”n_negi”が3つ並んでいるように見えますが一部表示が省略されており、正確には上から、ネギたこ焼きを買った個数が1個、0個、3個と表示されています。
このことから、”n_takoyaki”(たこやきの購入数)を予測するAIは、”n_negi”(ねぎたこ焼き)の購入数を重要視しており、その中でもねぎたこ焼きを1個買った時の情報が重要、と判断していることがわかります。
AIによるモデル評価解説
ここで、CatDataに最近追加された”AIに解説してもらう”という機能について紹介します!これの機能を使うためのボタンは、「混同行列」と「変数の重要度」の真下にそれぞれ設置されています。そこをクリックすると各結果に関する「チャートの説明」「チャートの解説」「モデルの改善点」について、AIが解説してくれます(図6)。

たとえば、図7の「チャートの説明」内では、混同行列とはなんなのか?について説明されています(「混同行列は、分類モデルの予測結果と実際のクラスレベルとの一致度を表す行列です」が該当)。
この機能を使えば、AIが図についての解説でサポートしてくれるので、専門用語が分からない方でも安心して結果について考察することができます!
続いて、混同行列の”解説AIによるレクチャー”から、「チャートの考察」と「モデルの改善点」を見ていきます(図7)。

「チャートの考察」を確認すると、正しく予測された件数と誤って予測された件数と、このモデルのスコアの高さについて言及されています。解説AIは、今回作成したモデルは「予測結果の正確さはテストデータに比べて高いことが分かります。」と考察しています。
「モデルの改善点」では、作成したモデルがなぜそのような結果になり、より良いモデルにするためにはどうしたらよいのか?について書かれています。今回作成したモデルについては、「テストデータとトレーニングデータの混同行列を比較すると、モデルが過学習している可能性があります。過学習を防ぐためには、モデルの複雑さを調整する必要があります。」と考察しています。
以上から、このモデルには過学習の可能性があり、モデルを調整することで、より高い精度のモデルができる可能性があることがわかりました。これを参考に調整するのももちろんありなのですが、今回はテストデータに対して十分な精度が出ていると考え、追加調整はせずに予測に移ろうと思います。
終わりに
今回はたこやきの販売数を予測するAIモデルの学習を行いました!
新機能 ”AIによる解説レクチャー”が加わったことで、AIによる考察を参考にしながら考えることが可能となり、より良いモデルをつくりやすくなったのではないかと思います。
次回、第3回は今回作成したAIを使った予測を行っていきます!
※ 筆者紹介
佐藤 美結(慶應義塾大学環境情報学部3年):クマムシの生態に興味があります。好きなものはポケモンです。機械学習、プログラミングを一昨年から学び始めました。
---
私たちは、ワークショップのTAや機械学習ツールの使い方の紹介記事を執筆しています。今後も、AI構築の実際についてご紹介していきますので、お読みいただけると嬉しいです!
データ解析・AI構築の初学者向け自習テキスト
表データを利用したAI学習テキスト(Humanome CatData)
画像・動画を利用したAI学習テキスト(Humanome Eyes)
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!