
レンタサイクルの利用者数を予測するAIをノーコードで作ってみた|第3回:レンタル数を予測するモデルの学習

こんにちは!ヒューマノーム研究所でインターンをしている佐藤です。
今回の連載では、レンタサイクルのデータを当社が開発する Humanome CatData(以下CatData)を用いて分析し、自転車のレンタル数を予測するモデルを学習します。
前回の記事では、AIの作成に向けた事前準備として、時系列データを分割しました。今回は、前回作成した 2011/01/01〜2012/10/31 分のデータを使って、自転車のレンタル数を予測するモデルを学習します。
CatDataを使うと、プログラムを1行も書くことなくデータの前処理とモデルの学習ができます。無料で試せますので、気軽にお使いください!
利用者数を予測するモデルの作成
それでは、さっそくモデルを作成していきます!
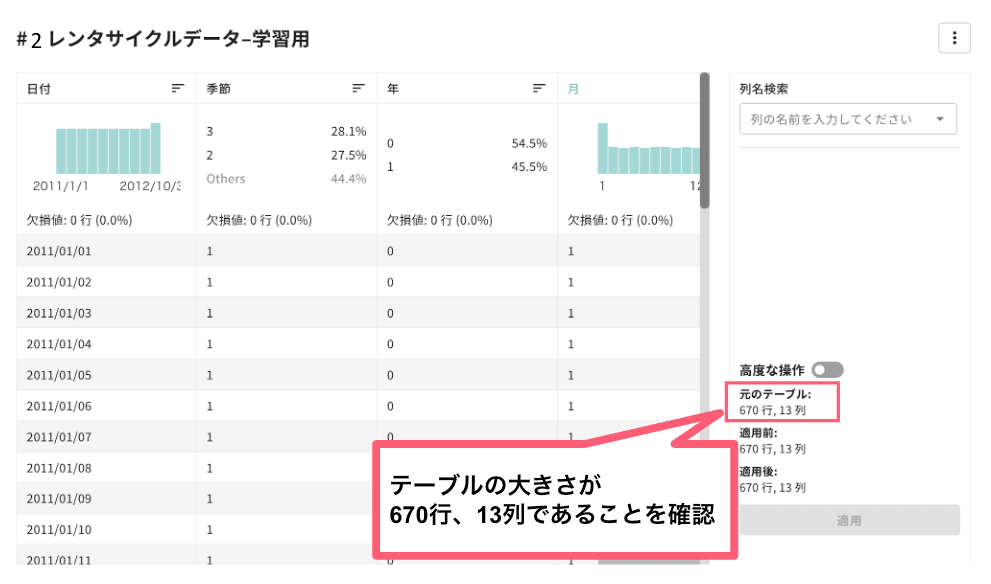
まず、「テーブル一覧」で、前回の記事で作成した 2011/01/01〜2012/10/31 のレンタサイクル利用者数に関するテーブル「レンタサイクルデータ–学習用」を選択します。利用目的の選択では「学習」を選択します。
「レンタサイクルデータ-学習用」を削除してしまった方は、以下に同じデータを用意しましたので、前回の記事を参考に、このデータをCatDataにアップロードしてください。
前回、2011/01/01〜2012/12/31のデータを使って学習用のデータを準備した時は、以下の前処理を行いました。
16列のデータから、”instant”、”臨時ユーザー利用数”、”全ユーザー利用数”の3列を削除
2011/01/01〜2012/12/31 の期間に観測した731日分(731行)のデータから、2011/01/01〜2012/10/31の期間に観測した670日分(670行)のデータを抽出
「レンタサイクルデータ–学習用」のテーブルは、これらの前処理を実施した後のものを複製したテーブルなので、今回は「前処理:アクションセットの編集」の画面では、前処理を実施する必要はありません。テーブルの行数と列数を確認したら、右上の確認ボタンをクリックします。
すると「欠損値と文字列および日時型の列の削除」と書かれている注意が表示されるので、「続行」をクリックしてください。「前処理:前処理結果の確認」に移動し、学習ボタンをクリックすると「学習」に移動します。
「学習」では以下の操作を行います。
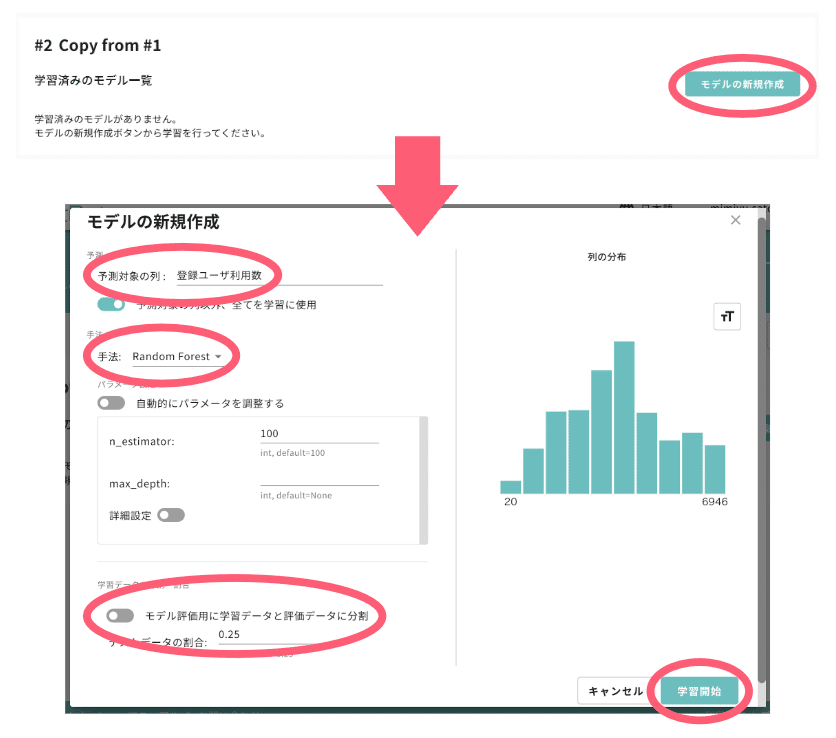
「モデルの新規作成」をクリック
「予測対象の列」は、今回予測したい「登録ユーザー利用数」に設定
「手法:Random Forest」であることを確認
「モデル評価用に学習データと評価データに分割」のチェックを外す
「学習開始」をクリック
今回の解析では、あらかじめ 2012/11/01〜2012/12/31 のデータをモデルの評価に使うデータとして準備しています。改めて評価データを準備する必要がないので、手順4で「モデル評価用に学習データと評価データに分割」の機能をオフにしています。
作成したモデルの評価
モデルの学習がはじまると、状態が「実行中」になります。学習が完了すると表示が「終了」になるので、「評価結果」をクリックして学習したモデルの詳しい結果を確認します。

「評価結果」の画面では ”予測値と実測値の比較” と ”変数の重要度” が表示されます。”予測値と実測値の比較” では、このモデルの良し悪しを示すR2とMSEが確認できます。
R2とは決定係数と呼ばれるものです。この値が1に近ければ近いほど良いモデルと言えます。MSEとは平均二乗誤差と呼ばれるもので、この値は0に近ければ近いほど良いモデルとなります。例えば、MSEが1000のモデルAとMSEが3300のモデルBがあった場合、モデルAの方が良いモデルである、と判断できます。
今回の結果は、学習データのR2は 0.98604、MSEが34100.24332 でした。R2の値を見る限り、学習データを利用した場合はかなり精度良く利用者数を予測できるモデルが作成できた、と言えます 。
変数の重要度から、このモデルが予測する時、1番重要視しているのは”気温”、続いて2012年かどうかを示す ”年_1”、”体感温度”、”月”の順に重要な要素であることが分かります。

モデルの精度が十分ではないと感じた場合は、モデルを作成する際に指定した手法やパラメータを変えて、もういちどモデルを作成してみてください。
CatDataの無料(Basic)プランでは、テーブル1個に対してモデルを1個しか作成できません。そのため、削除ボタンをクリックしてモデルを削除してから、改めてモデルを作成する必要があります。Proへアップグレードすると、テーブル1個に対して複数(50個)までモデルを作成できるようになります。モデルの比較も容易になりますので、ぜひご利用ください。
おわりに
今回は、CatDataを使って自転車のレンタル数を予測するAIを作成してみました。学習に使った 2011/01/01〜2012/10/31 のデータを使った場合は、高い精度となるモデルでしたが、このモデルを未来のデータに適用したらどうなるのでしょうか。
次回の記事では、今回作成したモデルを 2012/11/01〜2012/12/31 のデータに適用して性能を評価し、もっとよい性能のモデルが構築できるかどうかを試していきます!
※ 筆者紹介
佐藤 美結(慶應義塾大学環境情報学部2年):植物の生態に興味があります。好きなものはポケモンです。機械学習、プログラミングを昨年から学び始めました。
---
私たちは、ワークショップのTAや機械学習ツールの使い方の紹介記事を執筆しています。今後も、AI構築の実際についてご紹介していきますので、お読みいただけると嬉しいです!
この連載の過去記事
関連記事
表データを利用したAI学習テキスト(Humanome CatData)
画像・動画を利用したAI学習テキスト(Humanome Eyes)
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!