
元大学教員の高校教諭が総務省「情報II」教材を利用した機械学習の授業案を考えてみた|第6回:画像認識AI構築・前編

こんにちは。ヒューマノーム研究所 次世代先端教育特命研究員の辻敏之と申します。普段は中学・高校の教員をしながら、ヒューマノーム研究所のお手伝いをさせていただいています。
この連載では総務省から発表された「高等学校における「情報II」のためのデータサイエンス・データ解析入門」を授業で活用するアイデアについて共有します。
無理なくデータ解析全体の流れを学ぶことに主眼を置き、授業内でプログラミングレスな初心者向けノーコードAI構築ツール Humanome CatData とHumanome Eyes を利用することで、生徒がより楽しくデータサイエンスが学べます、という提案です。
これまでの連載は以下のリンクよりお読み下さい。
今回から2回に渡って、ノーコード画像検知AI構築ツール Humanome Eyes(以下 Eyes)を用いて、画像検知AIを作成していきます。テキストでは、いろいろな国のテーマパークを修学旅行で訪ねた美緒さんが思い出の写真を整理するのにニューラルネットワークを用いることはできないかな?と考えるところから始まります。
本稿内の全ての図は、後編・第7回の最後にまとめてPDF形式で無料配布します。授業でスライドとして示すなどしてご活用下さい。
1. データを確認する
総務省で公開されているデータセットは3つのフォルダ(ディレクトリ)からなっています。3つのフォルダは地域に対応していて、オーストラリア 11枚、イタリア 21枚、アメリカ5枚、合計37枚の画像データが含まれています。思い出と写真の枚数が比例しているのかどうかわかりませんが、ある意味リアルな状況なのかなと思いました。
本当は美緒さんの手元にもっと多くの写真があって、そこから無作為にサンプリングされた小さなデータだと考えることができます。テキストではこのデータを学習データとテストデータに分割して、ニューラルネットワークによって学習と予測を行っています。
本稿ではこの流れに沿って、Eyes を用いて実際にAIを作成してみたいと思います。Eyes の内部でニューラルネットワークを用いた機械学習が行われ、AI(学習モデル)が構築されます。
はじめにデータセットを学習するためのデータとテストするデータに分けましょう。アメリカのデータが5枚ありますので、1枚をテストデータに回すことにして、全体を4:1の割合で分割することにします。TrainningData とTestData というフォルダを用意して、それぞれのデータを入れておきましょう。図1にトレーニングデータのフォルダを示しました。中身のファイルはこの通りである必要はありません。
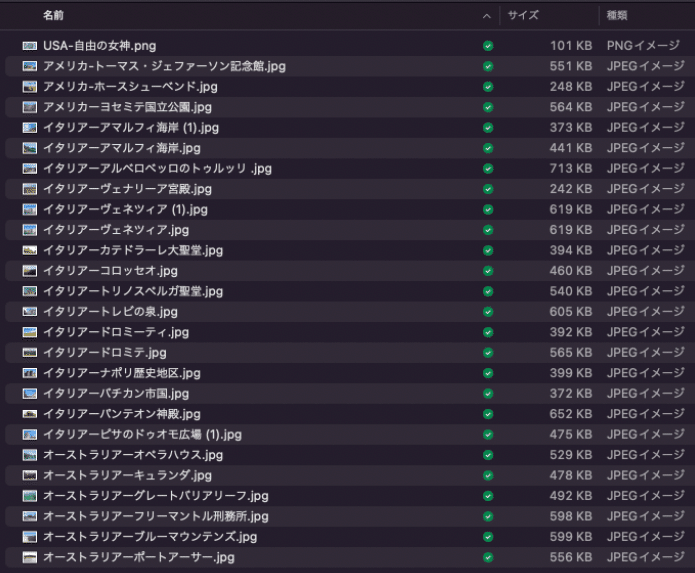
さて、賢明な読者の方は「はて? なぜフォルダの画像をわざわざ掲載したのかな?」とお考えのことかと存じます。この記事を読みながら実際に手を動かしていらっしゃる方はお気づきになったかもしれません。まだの方は是非、データを解凍してみてください。
実はこのデータ、Australiaというフォルダの中にオーストリア(ヨーロッパのドイツの南東にある国)の写真が3枚含まれています。とても分かりづらい弱い弱いボケなのですが、AI構築という視点からみると、これはコンタミネーション(通称コンタミ)です。誤ったデータが混入したデータセットなんですね。
この連載を読んでいただいている読者の皆さんはこういった状況を憶えていらっしゃるかもしれません。第4回で「常連」である人のラベルが「0」になっていることを指摘しました。今回も同じような「総務省のワナ」が仕掛けられていたわけです。
この総務省テキストの裏テーマは「生データをよく観察すること」であることに気づいてしまったのではないか。そんな気すらしてきますね。もしそうであるならば、担当者の方は本当に良い仕事をなされているなと感じます。
安定したデータ解析を進めるためには、コンタミを取り除く必要があります。ここではコンタミしていたオーストリアの画像はとりあえず無視して進めていきます。
生徒たちとこのデータセットのなにがおかしいか、一緒に考えてみるのは面白いと思います。まさか総務省からダウンロードしたデータがおかしいとは思わないでしょうから、いい教材になると思います。
2. ノーコードで物体検知AIを作る
2-1. タスクの作成
画像を学習データとテストデータに分けたら Eyes にログインして新しいタスクを作成しましょう(図2)。ここからは Eyes の使い方をメインに進めます。

Eyesの使い方は重要なタームではありますが、本質的なことは、ツールを通してデータをどう捉えるかです。データからなにを生み出すかという視点はCatDataを使っていたときと全く変わりません。ノーコードで物体検知AIを構築できることの恩恵は、コーディングすることなく、データについて考えることができることです。
タスクを作成したら、「どんな画像検知AIを作るか」を判定するためのラベルを定義し、学習データをアップロードする画面に遷移します(図3)。

タスクがわかりやすくなる名前を付けて、判別したい画像のラベルを定義します。ここではアメリカ、オーストラリア、イタリアの画像を判別したいので、対応する3つのラベル America, Australia, Itary を定義しました。データのアップロードは用意した学習データをドラッグ&ドロップしましょう。それが終わったらアップロードボタンを押してアップロードします。
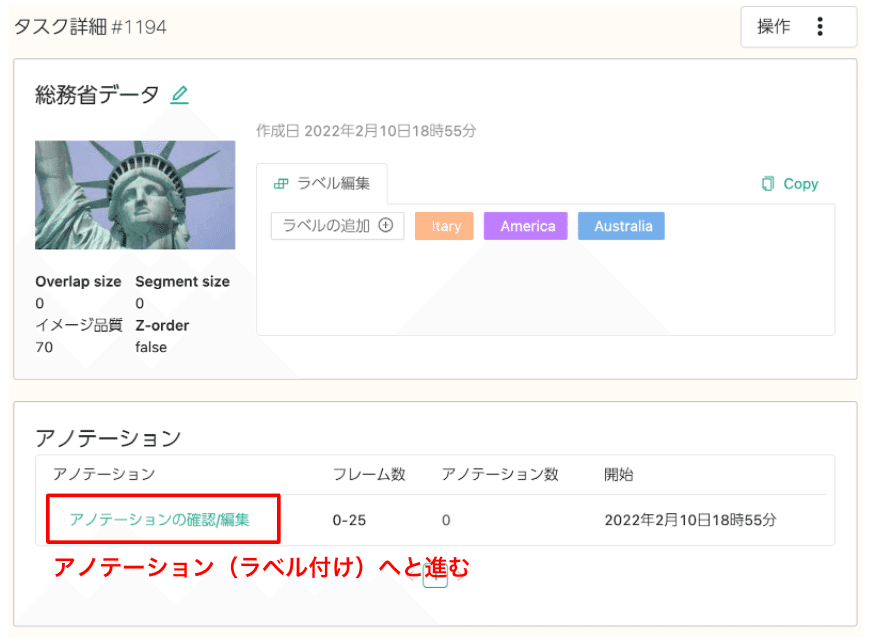
アップロードが終わると、新しいタスクが生成されるのでそちらに移動します(図4)。ご自身で命名したタイトルのタスクができていて、定義したラベルがあることが分かります。アップロードした学習データはその下の「アノテーション」という項目のところに反映されています。
図4に示したタスクでは、「アノテーション」のところにあるフレーム数が0-25となっており、26枚の写真がアップロードされていることが分かります。
2-2. アノテーション実施
次にアップロードした画像にラベル付け(アノテーション)をしていきます。アノテーションとは機械学習を行う前に「この部分がラベルで示した物体だよ」と位置とラベルでマークすることを言います。図4に示した「アノテーションの確認/編集」というリンクからアノテーションエディタへと進みます。
アノテーションは以下の手順で進めます。
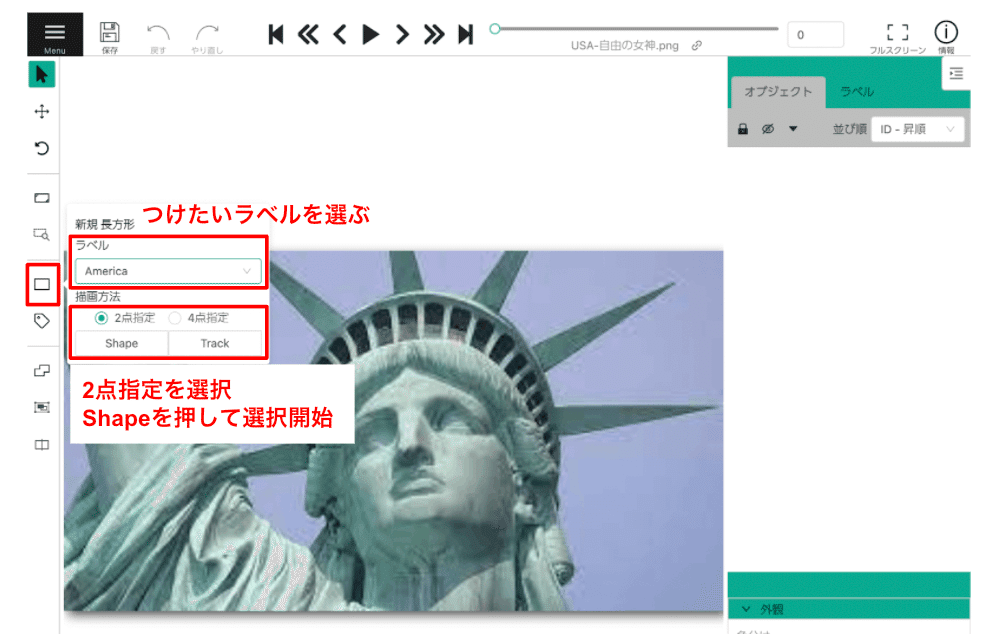
左に並んだアイコンから四角形のアイコンを選択
これから選択する物体のラベルをプルダウンメニューから選択
「Shape」ボタンを押すと、画像の上に四角を描くことができるようになるので(図5)、学習させたい物体の位置を選択していく
同様に残りの画像もアノテーションする
エディタ上部にある「>」を押すと次の画像に進むことができます。
全てのアノテーションが終わったら、左上の「保存」アイコンを押して保存
図5のように2点指定を選択した場合、長方形の対角を2点クリックすることで、四角いエリアを指定します。ドラッグしてもうまく指定することができないので注意してください。
今回の目的は「どこで撮った写真か自動で識別すること」でした。そのためにテキストでは画像全体を学習データとして、国名をラベルにしています。この流れに倣って、ここでは画像全体を「物体」としてアノテーションしていきます。
本来、Eyes で行う物体検知は例えば「自由の女神はこの位置にある」といったことを検知するというものです。想定される Eyes の使い方とは少し違いますが、どうなるでしょうか。試してみましょう。
物体に対してアノテーションを行った場合と比較してみると、Eyes がなにを検知しているのか、どういう学習が行われるのか理解しやすくなると思います。

アノテーションする時は、図6に示したように画像全体を選びます。この画像はアメリカの画像なので "America" というラベルになっていることが、アノテーションした領域の左上、もしくはオブジェクト一覧を示す右のカラムから確認できます。
アノテーション内容を保存したら、左カラムの「タスク一覧」からタスク選択画面に移動します。すると、タスク詳細の画面に戻ります。図7のように「アノテーション」のセクションにある「アノテーション数」が画像数と同じになっていたらアノテーションが正常に完了しています。
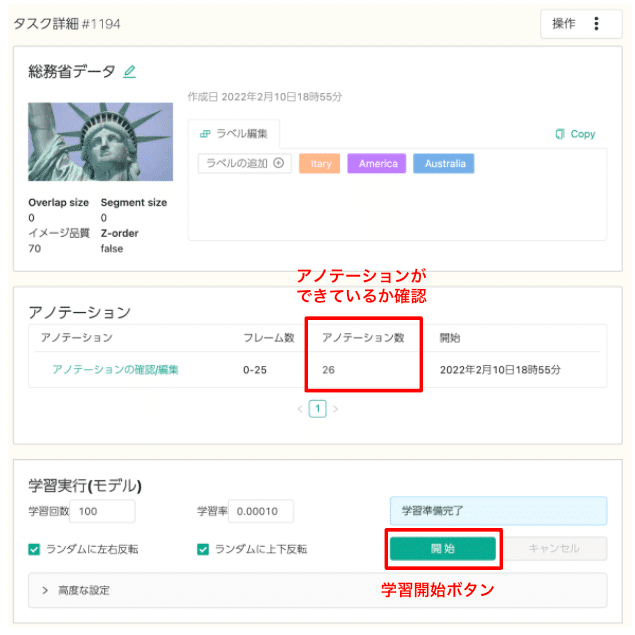
アノテーションが済んだことを確認したら「開始」ボタンを押して学習を始めましょう。先ほどアノテーションした画像とつけたラベルを学習データとして、アメリカ・イタリア・オーストラリアの景色について学習します。
2-3. モデルの学習
学習を開始すると、タスク画面の一番下にある「学習モデル一覧」にモデルが新しく追加され、「待機中」→「学習中」→「完了」と状態が変わっていきます。図8に示したように「完了」と表示されたらモデルのできあがりです。この例では20分ほどかかりました。かかる時間はサーバーの混み具合によっても変化するので、じっくり待ってみてください。

できあがったモデルの名前をクリックして、モデルのページへ移動しましょう。モデルのロスや精度に関する詳しい説明は、Eyes について扱っている下記連載を参考にしてください。
3. 次回予告
本稿では、旅行写真をニューラルネットワークを利用して整理することを目的とし、画像データの内容を確認したあと、Eyesを用いて画像認識AIを作成するところまで触れました。
次回は、今回作成したAIモデルは実際に予測できるのか?について、テストデータを使って確認を進めていきます。
次回も是非お読みください。お楽しみに!
※ 筆者紹介
辻敏之:機械学習やIoTデバイスを用いた先進的な教育活動に興味があります。好きなことは写真撮影と美味しいものを食べること。普段は中高生に理科を教えたり、研究指導したりしています。
4. データ解析・AI構築の初学者向け自習テキスト
表データを利用したAI学習テキスト(Humanome CatData)
画像・動画を利用したAI学習テキスト(Humanome Eyes)
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!