
ワクワクから始めるAI・データ解析(5.AIモデル構築編)

この記事は初心者向けのノーコードAI構築ツール「Humanome CatData」(以下「CatData」)を使い、まずデータをさわってAIづくりをはじめよう、という連載の第5回となります。これまでの記事は以下のリンクからお読みいただけます。
前回まで2回にわたり、データをさまざまな角度から確認し、解析の方向性をブラッシュアップする行程「可視化」についてお話しさせていただきました。
今回からいよいよAIモデルの構築に入ります。
AIモデル:データ解析方法のひとつ。人間が自然に行う「学習する」過程をコンピュータが実現する一つの方法で、計算機が最終的に見つけ出す具体的な計算式・計算方法を指します。作成されたAIモデルは入力されたデータから評価すべき本質を計算し、評価や判定結果を結果として出力します。

CatDataではクリックだけでAIモデルを作成できます。実際に作ってみていただければ、AI構築自体は意外とカンタンなんだな、と思っていただけるはずです。
今回はAI構築や機械学習の専門用語が多く登場するため、都度説明しながら進めます。一部有料機能の説明が入りますが、無料プランで最後まで学習できますのでご安心ください。
(1) テーブルの削除
前回同様、ペンギンデータを利用して「くちばしや水かきの長さからペンギンの種名を予測するAI」を、CatData を利用して実際に作成します。
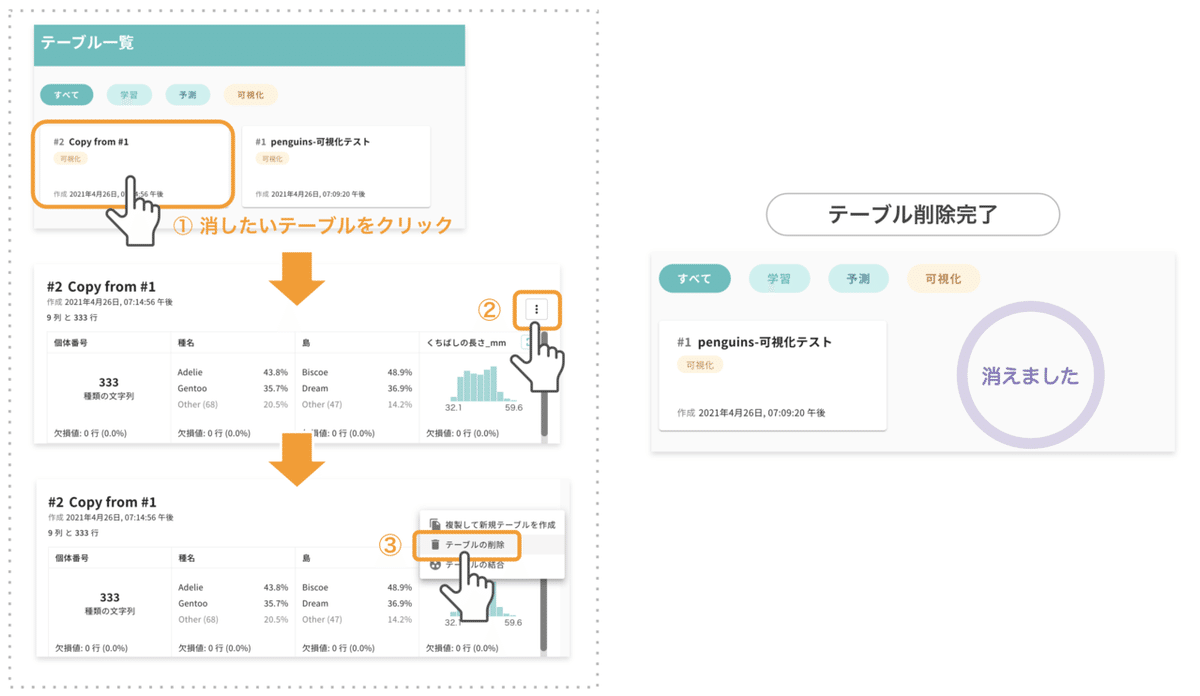
これから学習用のテーブルを作成します。無料プラン(Basicプラン)の方は、作成できるテーブル数の上限に達しているため、最初に上図の手順で可視化用に作成したテーブルをひとつ削除します。
テーブル一覧で「#2 Copy from #1」を押すと「テーブルの詳細」へ移動するので、テーブル右上の「︙」をクリックします。テーブル操作メニューが現れますので、ここで「テーブルの削除」を選んで削除します。
有料プラン(Proプラン)の方はテーブル数の作成が50個まで可能なため、この「テーブルの削除」は不要です。
(2) 学習用テーブルの準備
それでは学習用テーブルの準備に入ります。今回は2.前処理編できれいにしたデータを再利用します。テーブル一覧から「#1 penguins(可視化編②でテーブルの名前を変更した場合はその名称)」 をクリックし、アクションセットの編集画面まで進んでください。
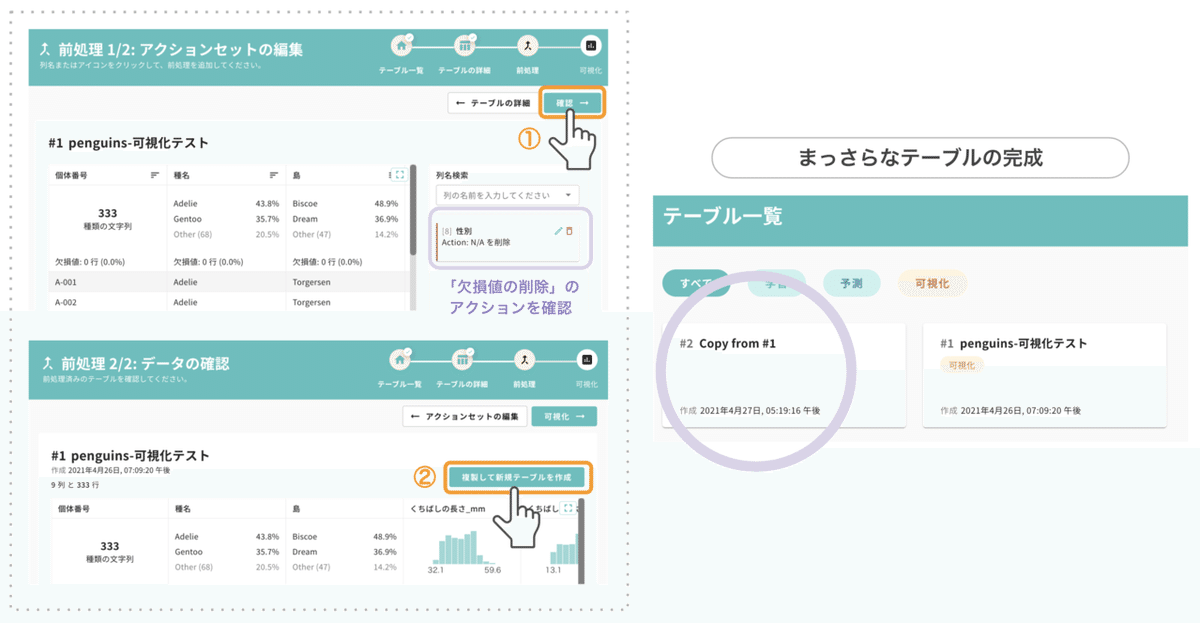
上図の通り「性別の欠損値を削除する」アクションがあることを確認してから、テーブルを複製して保存してください。
欠損値削除のアクションがなかったり、他のアクションが追加されていた場合は前処理編を参考に、欠損値が削除されたテーブルとそれをコピーしたテーブルを作成してください。
わかりにくい場合は、そのまま先に進んでもらっても大丈夫です。後述の通り、CatDataには欠損値を自動削除する機能が含まれているため、この手順を飛ばしても、AIモデルの作成を実施できます。
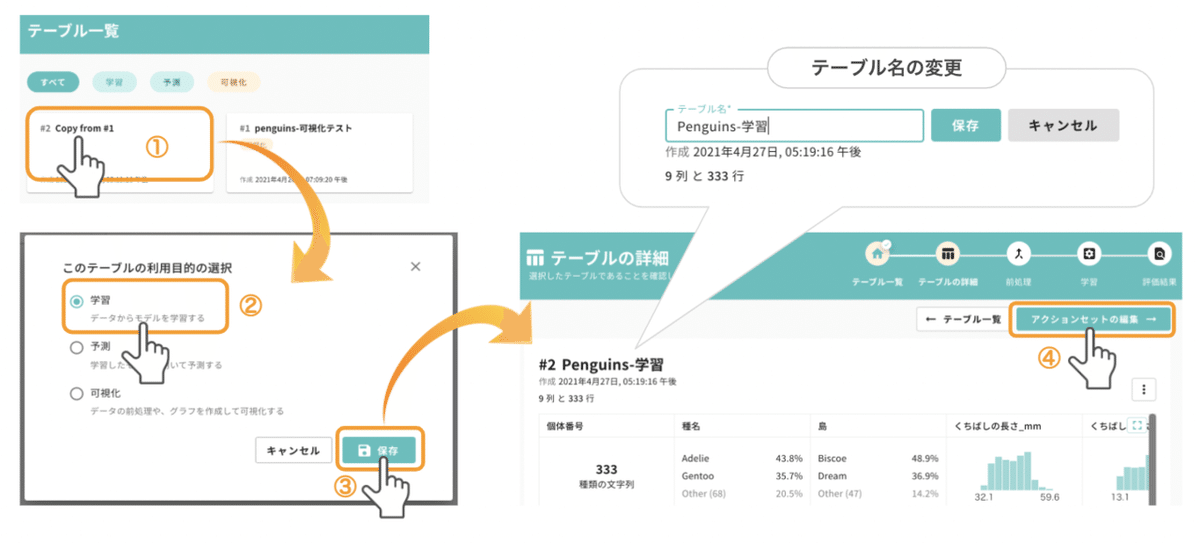
テーブル一覧に戻ると、AI構築で利用する「Copy from #1」ができています。これを選択すると「テーブルの利用目的の選択」のポップアップが現れるので、今回は「学習」を選び、「保存 > アクションセットの編集」と進んでください。
デフォルトのテーブル名が少々わかりにくいので、ここで名称を「Penguins-学習」に変更しておきます。
テーブル名の変更方法については、可視化編②「(2)可視化の下準備」内で詳しく説明しています。
(3) AI構築開始前の注意事項
今回は前処理済みのデータを用いているので「アクションセットの編集」では何もせず進みます。画面右上「確認」をクリックしてください。
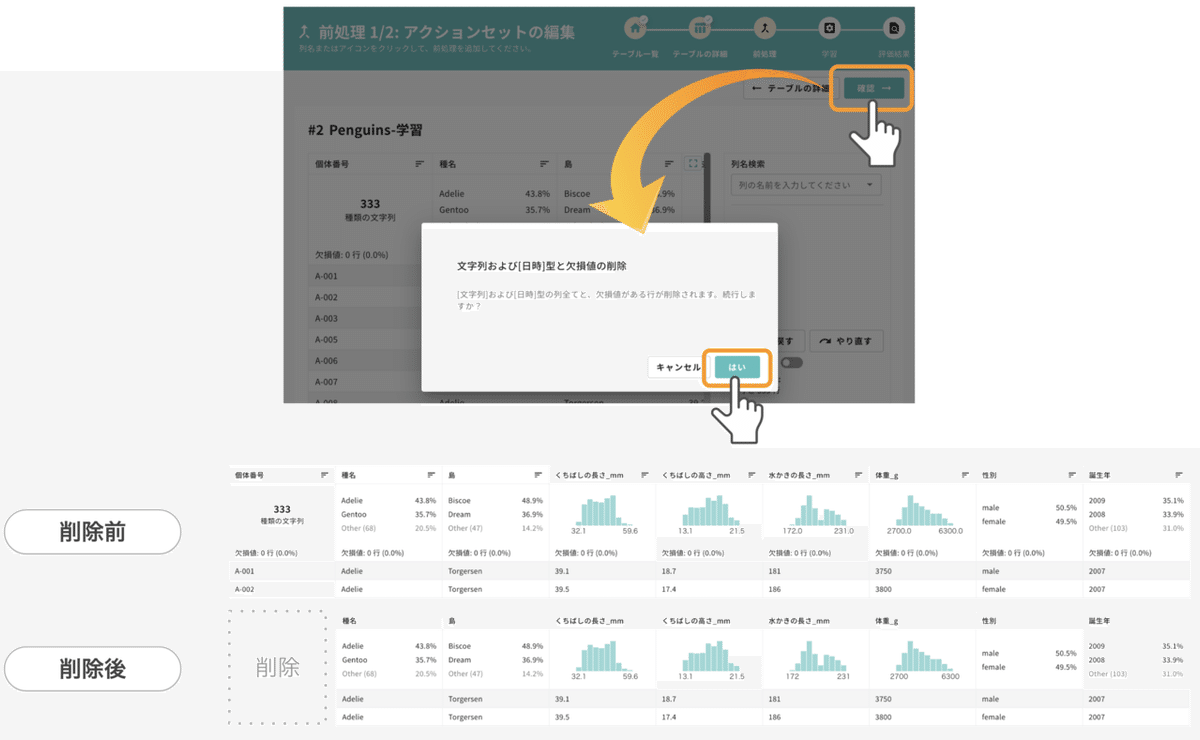
すると「AI構築に使えないデータを削除してもよいか?」を確認するアラートが出ます。前処理編でもふれましたが、AIを構築するためには、利用できないデータを削除するか補完し、キレイなデータに整える必要があります。
CatDataには、予測とは明らかに関係しない「個体番号」のようなデータや、欠損値のような「予測には使えないデータ」を自動で取り除く機能が搭載されています。AI構築に入る前に、この処理を実施するタイミングでお知らせしています。
アラート内の「はい」を押すと「データの確認」へ移動し、不要なデータが削除されたテーブルが現れます。
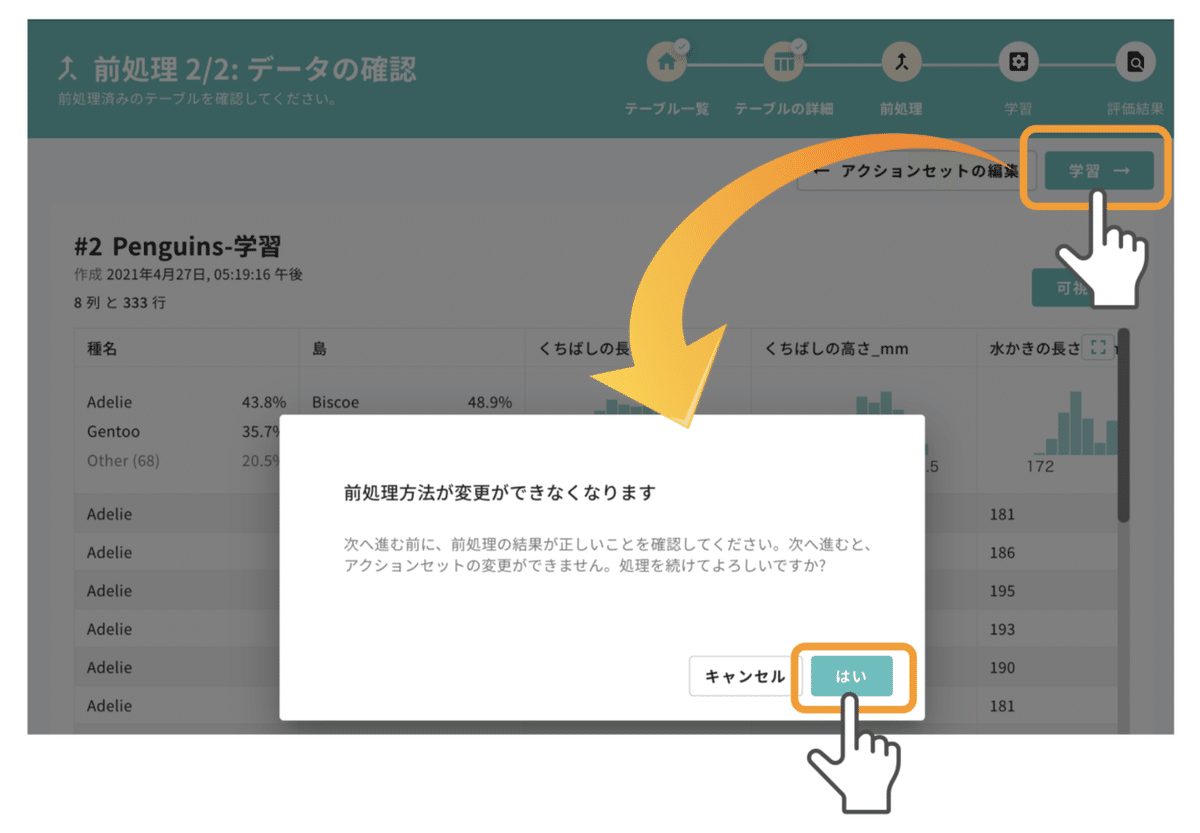
先程のテーブルと見比べると、学習に利用できない個体番号の列が削除されているはずです。予想外のデータが消えていなければ、上図右上の「学習」を押してください。
AI構築は多くの場合、一つのテーブルからAI構築の条件(モデル・パラメータ)を変えたAIを複数作り、精度の比較検討を行います。前処理方法が異なると、元になるテーブルの内容も変わるため、同じ条件下で比較することができなくなってしまいます。
CatDataでは同じ条件での精度比較を促すため、学習に入る前にテーブルの前処理方法の変更操作は終了し、フェアな条件で精度比較ができるようにしています。問題なければ「はい」を押し、次に進みましょう。
(4) 「予測したい項目」と「予測に利用する項目」の設定

それでは実際にモデルを作成します。上図「① モデルの新規作成」を押すと、モデル作成時の設定を入力する「モデルの新規作成」という画面が現れます。
それでは、構築時に設定する項目を順に説明します。
■ 予測したい項目の設定
「予想対象の列」はAI構築で予測したい目標となる項目を入力する欄です。今回は「ペンギンの種名」を予測したいので、ここでは「種名」を選びます。
ここまで「種名」を予測することを意識して前処理や可視化を進めていますが、どの項目を予測したいのか、CatDataに対して伝えるのはここが最初となります。予測したい項目を指定することで、はじめてAIモデルの構築が可能となります。
■ 予測に利用する項目の設定
今回のAI構築の目的は「くちばしの長さや体重などを計測することで種名を予測できるか?」です。しかし、ペンギンデータには「誕生年」など、今回の予測では利用しない項目も混ざっているため、それらを外します。

「予測対象の列以外、全てを学習に使用」のスイッチをオフにすると、予測に利用する項目を任意で設定する「説明変数」の選択画面が現れます。
説明変数:学習や予測に利用する項目(列)を指します。AIモデルは説明変数の値を複雑に組み合わせて予測を行います。
ここでチェックを入れた項目が予測に利用されます。「くちばしの長さ」「くちばしの高さ」「水かきの長さ」「体重」だけにチェックを入れ、他のチェックは外してください。説明変数の横にある数字が「④」になっていればOKです。
「AI構築にはどんなデータも使える」と考えがちですが、必ずしもそうではありません。例として、誕生年が2007〜2009年のデータから構築したモデルを利用して、翌年2010年に生まれたペンギンの種名を予測する場合を考えます。
予測を実施するAIモデルには、2010年のデータは含まれていません。そのため、誕生年をAIモデルに含めた場合、2010年の情報を学習していないAIは「そんなデータ知らない!」と、適当な予測を返す可能性があります。このため、予測する項目を決める際は、AIが学んでいる情報の範囲まで含めて考えなくてはなりません。
(5)モデルとパラメータの設定

上図は、予測に利用するモデルとパラメータの設定画面になります。いずれの項目も、最初からCatDataオススメの設定になっています。まずは値を変更せずに「開始」を押して、そのまま実行してみてください。選べるモデルの詳細やパラメータの種類などについては、別の記事でご説明します。
■ モデルの設定
「手法」は予測に用いるモデルを決める欄です。AIモデルにはいくつかの種類があります。それぞれに得意な分野や苦手な分野があるため、目的に応じたモデルを選択することが大切です。
■ パラメータの設定
パラメータはモデルの挙動を調整する値です。「パラメータ設定」はパラメータチューニング(パラメータを調整すること)する欄です。
■ 学習データとモデルデータの分割割合の設定
AIモデルを構築する時は、もともとのデータを「学習データ(モデルを構築するために使うデータ)」と「テストデータ(できあがったモデルを評価するためのデータ)に分割し、学習データで構築したモデルの精度をテストデータで確認します。
CatDataでは「テストデータの割合」の値で、データの分割割合を調整します。デフォルト設定の場合、テストデータが25%、学習データは75%となるように分割されます。

モデルとチューニングは、楽器と調律の関係性と似ています。同じ曲を演奏するとしても、表現したい世界観に合わせて、弦楽器・管楽器・打楽器など複数の楽器を曲調に合わせて選びます。また、どの楽器も演奏前に調律が必要となります。
同様に、どんなデータでも高性能な結果を出せる万能モデルはなく、また、それぞれのモデルで精度を出すには、パラメータチューニングが不可欠です。

「開始」すると、ポップアップが閉じ、モデルの学習(モデルの計算)がはじまります。状態が「実行中」から「終了」に変わったら、モデル構築は完了です。
次回のお知らせ
今回は前処理の終わったデータを使って、実際にAIモデルを構築しました。次回は今回作成したモデルが実際に使える精度なのか?を評価していきます。引き続き、お読みいただけるとうれしいです。
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!