
ワクワクから始めるAI・データ解析(1. 導入・目標設定編)

こんにちは、「株式会社ヒューマノーム研究所」代表取締役社長の瀬々です。今回から数回にわたって、前回のお話の続きとなる『実際に作る』からはじまるAI構築の初歩について、実例を交えながらご説明していきます。
この実例はプログラミングを知らない方でも試せます
(いきなり見出しと矛盾しますが)AI構築を含む、データ解析と呼ばれるものにはプログラミングが欠かせません。しかしここ1〜2年くらいでしょうか、「ノーコードツール」と呼ばれる、プログラミングをすることなく、基本的な解析ができるツールが開発されるようになりました。
当社が開発する「Humanome CatData」も、表データの解析やAI構築ができるノーコードツールのひとつです。 初心者もデータ解析の楽しさが気軽に体験できるように、プログラミング・数式の知識いらずで操作できる作りになっています。
次回以降、実際にHumanome CatDataを操作しながら「AIのつくりかた」について解説していきますが、今回はその準備段階についてお話させて下さい。
わからない点がありましたら、お気軽にこの記事へコメントをお寄せ下さい。また、実際に操作しながら一緒にお試しいただけると、より本文説明がわかりやすくなります。ご興味をお持ちいただけましたら、ぜひ、上のリンクよりアカウント登録してみてください!
前段(1):「データ解析」と「AI構築」の違い
「AIを構築してみたい!」とよくご相談を受けます。そんな時、私はいつも「まずはデータ全体を考えましょう」と答えています。AIはデータ解析やデータ活用の流れの一部だからです。
「データ解析」「AI構築」。ともに定義が曖昧な単語です。
データ解析とは、データを取り扱う過程のすべてを対象とし、データを様々な角度から調査し、活用することを指します。対するAI構築はデータ解析で実施する行程の一部にあたり、何らかに特化した予測パートを担います。
データ解析とAI構築の関係は下図のようになります。図中の行程①から⑦について、順番にご説明します。

前段(2):AI構築の基本的な行程
データ解析のプロジェクトでは、一番最初にデータを使って実現したい内容を多数用意し(図中① 仮説設定)、それぞれについて順番に調査します。AIを構築する際は、これらの仮説から本当に予測したい内容を一つに絞ってから、モデルづくりに移ります。
このプロジェクトの流れを「スポーツクラブの会員継続率を上げたい!」というお題に当てはめて考えてみます。
「ずっと会員でいてほしい!」が目標の場合、「退会しそうな人にメールを出したり、声かけをすれば、退会を防げるかも?」という一つの仮説が立ちます。
この仮説を確かめるため「会員継続しない人を予測する」という目標を設定します(図中② 目標設定)。高精度のAIができれば、退会するかも?と予測された人に対してメールを送付するなど、事前に退会を防ぐ方策が取れるようになります。

このように、データ解析の流れは一方通行ではなく、試行錯誤が欠かせません。目標設定後、AI構築のために必要となる行程は以下のとおりです。
③-1 データ収集
文字通り「データを集めること」です。設定した目標を達成するために必要なデータを収集します。複数の表にデータがまたがる場合はひとつの表にまとめてから利用します。
③-2 前処理
集めたデータをそのままAI解析に使えるとは限りません。項目はあるけど値が入っていない、値は入っているけどちょくちょく桁が間違っているなど、思った通りのデータ形式になっているとは限りません。辛いですね。これらのデータを整えたり、除いたりすることを前処理と言います。
④ 可視化
集めたデータは想像通りのものなのか、前処理が終わったあとのデータに予期しない事態が起こっていないかなど、グラフや図にすることで確認することをいいます。可視化するとデータを観察しやすくなるので、次の「AIモデル(※)構築」を行う際の作業難易度の推測にも利用できます。
※ AIモデル:データ解析方法のひとつ。人間が自然に行う「学習する」過程をコンピュータが実現するために必要となる、具体的な計算式・計算方法を指します。入力されたデータから評価すべき本質を取り出し、この評価や判定をモデルが行ったものを結果として出力します。
⑤ モデル構築
AIモデルを選択し、モデルを構築します。AI構築・AI作成とも言われます。詳細は別の記事でご説明します。
⑥ 評価
作成したモデルの精度を評価します。評価の結果、目標を達成できる精度が出ていれば、そのまま運用します。残念ながら精度がイマイチだった場合は、目標設定まで含めて、すべての行程について考え直す必要があります。
---
実際にデータ解析する時は、これらの行程を行ったり来たりしながら、少しずつ目標を達成する方向に進めていきます。得られたデータがどのように使われるのかを想像し、どの切り口が改善や発見につながるか?を考えるのは、苦しくもあり、もっとも楽しいプロセスでもあります。
実践編(1):目標設定とデータの準備
前段が大変長くなりましたが、ようやくここから本編に入ります。
一般的に「AI」は入力されたデータをもとに何らかの予測を行います。そのため、AIを作る場合、まずは何を予測したいか?を決めるところからスタートします。先程のスポーツクラブの例でいうと「利用履歴から会員が継続するか否かを予測する」が目標となります。

今回はペンギン3種 (アデリーペンギン、ヒゲペンギン、ジェンツーペンギン)の大きさを計測したデータを使います。データは以下のリンクからダウンロードして下さい。
■ ペンギンデータ(palmerpenguinsデータを当社で改変しました)
南極大陸のパルマー諸島で集めた、ペンギンの種類・性別・サイズなどのデータです。動物は性別によって異なる性質を持つことが多く見られますが、このデータは、性差によるエサの集め方の違いについて、ペンギンで調査をした際のものです。
「突然のペンギン!?」と思われるかもしれませんが、血液検査の結果から病名予測したり、果物の色や大きさから市場価格を予想したりする時も、ペンギンの解析と流れは同じです。
今回はデータ解析の流れの中から「① 仮説設定」「② 目標設定」「③ データ収集」について進めていきます。

ある日、突然ペンギンが好きで好きで仕方なくなってしまったあなたは、目の前にいるペンギンの種名を教えてくれるシステムがどうしても欲しくなりました。
種によって異なるパーツの長さがわかれば、ペンギンの種類も予想できるのではないか? そう考えたあなたは、くちばしや水かきの長さを入力すると、ペンギンの種名が予測できるAIをつくることにしました。
早速先程のデータで構築してみましょう。
先程のペンギンデータファイルには、下のような表形式で34個体分のデータが収められています。
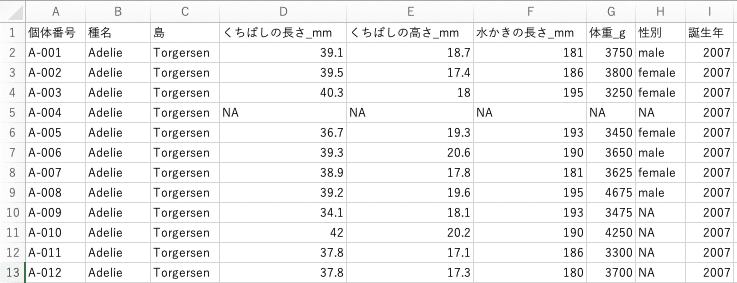
今回つくるAIにおいて予測すべき目標は「ペンギンの種名」です。これらは表の中に含まれている必要があります。
たとえば「満足度の高い顧客」を予想する場合は「顧客満足度」の情報が不可欠です。顧客にアンケートをお願いするなど、定量的(状況や状態を数字で表現すること)な顧客満足度情報を集めておく必要があります。
「そんなの当たり前なのでは?」と思われた方もいらっしゃるかと思います。しかしながら、いざAIを構築しようとしたら、予測すべき項目の定量的な値がなかった、という事態はありがちなことなのです。
正しい目標設定とその達成に必要なデータを集めることは、データ解析のプロセスにおいてとても大切です。
次回のお知らせ
今回はデータ解析の用語説明と全体の流れの確認、その中から「① 仮説設定」「② 目標設定」と行程③の前半戦「 データ収集」についてお話させていただきました。
次回はデータ解析の行程③の後半戦「前処理」についてご紹介していきます。ぜひお読みいただけるとうれしいです。
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!