
元大学教員の高校教諭が総務省「情報II」教材を利用した機械学習の授業案を考えてみた|第2回:SVMを用いた2群判別

こんにちは。ヒューマノーム研究所 次世代先端教育特命研究員の辻敏之と申します。普段は中学・高校の教員をしながら、ヒューマノーム研究所のお手伝いをさせていただいています。
この連載では、総務省から発表された教師用研修教材「高等学校における「情報II」のためのデータサイエンス・データ解析入門」を授業で活用するアイデアについて共有します。
本稿第一回の通り、本教材はデータ取得からデータの前処理、パラメータ選択、手法選択、学習、評価といった大きな流れを示す良いテキストですが、そのサンプルコードはひと目で理解できる内容ではなく、あまり初学者向けではありません。
そこで、無理なくデータ解析全体の流れを学ぶことに主眼を置き、授業内でプログラミングレスな初心者向けノーコードAI構築ツール Humanome CatData(以下 CatData)とHumanome Eyes(以下 Eyes)を利用することで、生徒が楽しくデータサイエンスを学べるのではないかと考えています。
本稿内の全ての図は、記事の最後にPDF形式で無料配布します。授業でスライドとして示すなどしてご活用下さい。
それでは第2回、SVMを用いた2群判別についてです。テキスト第3章「機械学習(教師あり)」に沿って進めつつ、第2章、第5章の内容にも触れていきたいと考えています。
美緒さんは携帯電話が壊れる原因を探求するためにサポートベクターマシンを使ってデータ解析を行うことを試みます(テキスト54ページ)。この解析をCatDataを用いて行ってみたいと思います。
CatDataを初めてご利用いただく際は、開始前に以下リンクを参考に無料アカウントを作成して下さい。
1. ログイン〜データインポート
CatDataにログインをします。初期状態ではデータもなにもないので「テーブルがまだ作成されていません。まずはテーブルを作成しましょう。」と表示されていると思います。CatDataではテーブルがデータ読み込みからAI構築までの大きな単位になります。まずは新規テーブルを作成しましょう(図1)。

次にデータの読み込みを行います。総務省のサイトで配布されているサポートベクターマシン用のデータ「SVM.csv」を用います。サイトからダウンロードして、ドラッグアンドドロップしていただいても構いません。しかし、ここでは項目を日本語化した同じデータをGoogleスプレッドシートに用意しましたのでそちらをインポートしてみましょう。
Googleスプレッドシートのスイッチをオンにして以下のURLをペーストしてアップロードします(図2)。授業ではURLが同じなら生徒全員が同じデータを使ってるということが保証されるGoogle スプレッドシートをデータソースとして用いたほうが安心感がありますね。
インポートすると図3のような画面に遷移します。ここではきちんと意図したテーブルが作成されたかを確認し、それぞれの列の値の型(整数、小数、文字列、カテゴリ)を確認してください。確認すべきとCatDataが判断した列が赤く示されるようになっています。特に注意して確認しましょう。0と1もしくは0,1,2で構成されている列は「カテゴリ」と解釈されています。
今回の解析ではSVMを用いて壊れるスマホか壊れないスマホかを判別することが目的になりますので、カテゴリデータは予測したい項目「過去の故障歴」だけにしてください。残りの項目はSVMで扱えるよう「整数」にして右上の「保存」ボタンから保存してください。

2. 学習の事前準備
保存ボタンを押すと図4のダイアログが表示され、このテーブルを何に使うのか聞かれます。選択肢には学習・予測・可視化と3つあって、簡単に言うと以下のような構成になっています。
学習:テーブルのデータを用いて機械学習を実施し学習モデルを構築する
予測:学習によって構築された学習モデルを用いて、データを解析し、予測を実施する
可視化:テーブル内のデータをグラフにし、可視化することでデータを観察する。
ここではSVMを用いた学習を行いたいので「学習」を選んで保存します。

「アクションセットの編集」に遷移します。学習に用いる項目の決定と、欠損値の処理などを行います。今回のデータに欠損値はないので、その処理については割愛しますが、以下の記事で詳しく解説されているので、気になる方はご覧ください。
今回は特にアクションセットを適用せずに進めましょう。右上の「確認」から前処理結果の確認ページへ進み(図5)、次のページも右上の「学習」から次のステップへと進んでください(図6)。


3. モデルの学習
いよいよ学習です。右上の「学習」ボタンを押して学習へと進みます。「前処理方法が変更できなくなります」というダイアログが出てきますが、迷わず「はい」を選んで進みましょう(図7)。

学習のページでは先程編集したテーブルを用いて学習モデルを構築します。右上の「モデルの新規作成」をクリックして進んでください。
今回はテキスト通り「過去の故障歴(past_falls)」があるかどうかを、SVMという方法を用いて予測する学習モデルを作ります。新規作成すると表示されるダイアログの「予測対象の列以外、全てを学習に使用」という項目のチェックを外してください(図8)。

チェックを外すとテーブルが表示されます。このダイアログ上で学習モデルを構築する条件を設定します(図9)。
テキストに沿って学習に用いる項目の選定を行います。テキストのコードでは「過去の故障歴(past_falls)」を予測するために「利用者の性別(sex)」「利用者の年齢(age)」「リングの有無(ring)」を用いています。
では設定しましょう。図9および図10を見ながら設定してください。
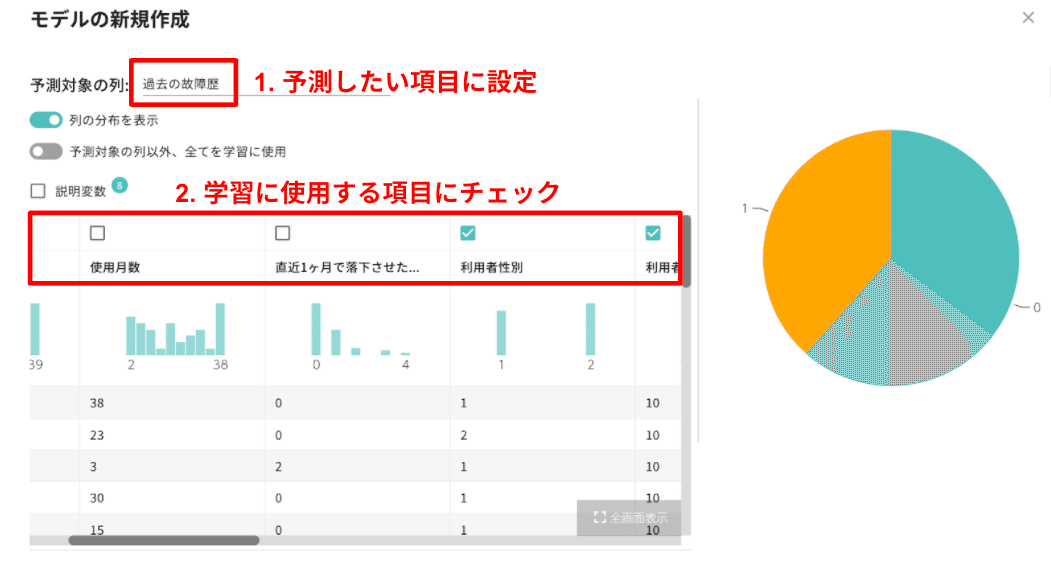

予測対象は「過去の故障歴(past_falls)」をプルダウンメニューから選択します。予測する項目は上記の4つを選択します。下のテーブルから必要な項目にだけチェックを入れてください。手法は「SVM」に設定してください。
このとき一番下の「学習データとテストデータに分割」、テストデータの割合を0.25とデフォルトの設定のままにしておいてください。全体の75%を学習に使って、残り25%を評価データにするという意味です。このあとの評価が簡単になります。
最後に一番下の「学習の開始」を押して学習を開始してください。
学習が終了すると評価結果から結果を見ることができます(図11)。「学習データのスコア」が作成したモデルの精度となります。

4. 作成モデルの評価
評価結果のページでは、作った学習モデルの性能評価結果が混同行列(図12)とROCカーブ(図13)という形式で示されます。
混同行列については以下の記事でも詳しく説明しています。よろしければお読み下さい。

混同行列は学習モデルがどう予測したかを示すものです。横軸に実際の値(今回は過去の故障歴についてあれば1、なければ0)、縦軸に学習モデルによる予測(1か0)という2軸からなる 2x2の表として表されます。図10にある混同行列の赤く囲まれた部分は1のデータを1と予測し、0のデータを0と予測しているため、正しく予測されたデータの数ということになります。
行列の上に書かれている「精度」はデータ総数のうち、いくつ正しく予測されたか、割合を示す値です。 図11に示す結果では、学習データそのものを予測しても41%のデータしか的中せず、テストデータだと20%しか当たらなかったとしています。混同行列の中身を見るとそのほとんどを「故障歴がある」と予測していて、予測器としての質が非常に低いことがよくわかります。
またROCカーブでも評価をみることができます。ROCカーブは横軸に偽陽性率(誤って陽性、この場合だと落としたことがあると予測した割合)、縦軸に真陽性率(ただしく落としたことを予測した割合)を示しています。とても単純化するとグラフが左上に張り付くようになればなるほど性能が高いということができます。図13に示したROCカーブからもこの学習モデルの性能が低いことがわかります。

このことから「過去の故障歴(past_falls)」と「利用者の性別(sex)」「利用者の年齢(age)」「リングの有無(ring)」にはあまり関係がなかったと推測することができます。たしかに性別や年齢より、元データにある使用期間、カバーの有無、今月何回落としたかなどの項目のほうがスマホの故障とは関係がありそうですね。精度が良かったり悪かったりすることで一喜一憂せず、どうしてその程度の精度だったのかをデータを眺めながら考え、次の項目選択や学習に活かすことがデータ分析の本質です。
5. 本稿のまとめ
ここまで、CatDataを用いて総務省が発行する「高等学校における「情報II」のためのデータサイエンス・データ解析入門」第3章 機械学習(教師あり学習) で扱われているSVMによる2群判別を行ってみました。
本編にあるようなコードを書かずに、データ解析の大きな流れを理解することに注力した結果、データ処理から学習、評価までを、見通しよく追いかけることができたのではないかと思います。
しかし、テキスト通りに解析を進めてみたところ、構築した学習モデルの質が低いことがわかりました。次回はこの質を高めるためにできることについて考えてみます。
データ解析には試行錯誤が重要です。1回学習してモデルを構築したから終了というものではありません。前述したように結果をしっかりと観察して、良くなった理由や悪くなった理由を考察する、なにが本質的な要素なのかを考えることが欠かせません。
CatDataを用いてノーコード開発を行うメリットは、データを可視化し、観察しながら試行錯誤ができること、そして手軽に学習を繰り返して学習モデルを作ることができる点です。
なお、今回の記事内で使用した図はPDFにまとめました。以下のリンクよりダウンロードして下さい。授業でのスライド用途などにご利用いただけます。また、本連載は下記リンクからまとめて読むことができます。
次回もぜひお読み下さい。
※ 筆者紹介
辻敏之:機械学習やIoTデバイスを用いた先進的な教育活動に興味があります。好きなことは写真撮影と美味しいものを食べること。普段は中高生に理科を教えたり、研究指導したりしています。
連載第二回図版資料

6. データ解析・AI構築の初学者向け自習テキスト
表データを利用したAI学習テキスト(Humanome CatData)
画像・動画を利用したAI学習テキスト(Humanome Eyes)
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!