
ポケモン好きがノーコードでポケモンデータをAI分析してみた | 第1回:種族値によるタイプ予測

こんにちは!株式会社ヒューマノーム研究所でインターンをしている佐藤です!
突然ですが、みなさんポケモンはお好きですか?2021年11月19日にポケットモンスターシリーズの名作「ポケットモンスターダイアモンド」と「ポケットモンスターパール」のリメイクが、そして今年、2022年には、完全新作の「Pokemon LEGENDS アルセウス」が発売されました。ポケモン好きの私としては心が踊ります!
そこで、今回から数回に渡って、当社が開発する表データ解析向けノーコードツール・Humanome CatData(以下「CatData」)を利用して、ポケットモンスターのデータ(以下「ポケモンデータ」)の解析を行い、ポケモンのタイプを予測していきます。
CatDataは無料で利用できますので、お気軽にお試しください!
1. ポケモンデータの説明
今回の解析は、以下の配布データを改変したものを使用します。
ポケモンデータは、”#(図鑑番号)”、” Name(ポケモンの名前)”、”Type1(ポケモンのタイプ1)”、”Type2(ポケモンのタイプ2)”、”Total(ポケモンの総合値)”、”HP(体力)”、”Attack(攻撃力)”、 “Defense(防御力)”、”Sp.Atk(特殊攻撃力)”、”Sp.Def(特殊防御力)”、”Speed(素早さ)”、”Generation(世代)”、”Legendary(伝説のポケモン)”の13列から構成されます。
ポケモンには物理攻撃と特殊攻撃があり、それぞれの攻撃力を「攻撃力」・「特殊攻撃力」、それぞれに対する防御力を「防御力」・「特殊防御力」で表します。これらのステータスのことを種族値と呼びます。
今回の記事では、この種族値を用いてポケモンのタイプ予測をすることを目的とします。
今回のポケモンデータは元のデータを一部変更して使用しています。一部の幻のポケモンの”Legendary”が”True”になっており、区別をつけるために”False”に変更しました。伝説のポケモンと幻のポケモンは、ポケットモンスター内では別のものであると考えられているためです。
元データ(改変前)
変更後のデータ
2. ポケモンデータの可視化
可視化までの操作手順
では、種族値からタイプ予測できるかどうかを確認するために、タイプと種族値の関係を可視化することで確認していきます。
ポケモンには18種類のタイプがありますが、ここでは数が多い順に10種のタイプ(”Water(みず)”、”Normal(ノーマル)”、”Grass(くさ)”、”Bug(むし)”、”Psychic(エスパー)”、”Fire(ほのお)”、”Electric(でんき)”、”Rock(いわ)”、”Ground(じめん)”、”Ghost(ゴースト)”)を対象に解析を進めます。これらのタイプに絞るため、アクションセット(詳しくはこちら)を利用します。
「テーブルの新規作成」からデータを読み込み、「可視化」を選択し保存をクリックすると、「前処理:アクションの詳細設定」まで自動で移動します (図1)。
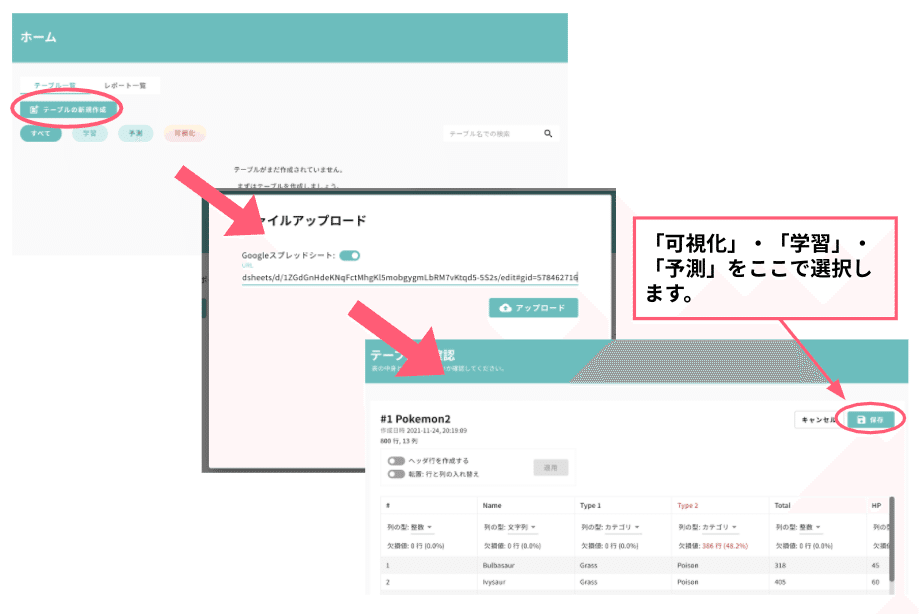
ここで、“Type1” の列→「上記であげた10個のタイプを選択」→「追加」と操作することで確認したいタイプを絞ることができます。全ての編集が終わり次第、「適用」を押すと編集内容が適用されます(図2)。適用すると、表の行数などが変わります。その後、可視化ボタンを押すと、画面にグラフが表示されます。

データを可視化し、解釈する
それでは試しに、列1は「Type1」を、列2は「Sp.Atk」を選択してみます。Sp.Atkでは、”Psychic”が大きめで、”Normal”や”Bug”は小さめであることが分かります。
次に、別の種族値とタイプを比較してみます。列1は先ほどと同じように「Type1」を、列2は「Defense」を選択します。Defenseでは、”Rock”が大きめで、”Electirc”が小さめであることが確認できます。
このことから、タイプごとに種族値に傾向があることが分かり、タイプを予測するときは種族値が重要であることが考えられます。

3. ポケモンデータを学習する
学習開始までの操作手順
では、AIを作成していきます。データの読み込みからアクションセットの編集まで先ほどと同じような手順で進め、学習用のテーブルを作成します。
詳しくは以下のリンクをご覧ください。
テーブルの新規作成から、先程の変更後のデータを読み込み「学習」を選択し保存
前述したものと同様に「Type1」のみ使用する。「前処理:アクションの詳細設定」の ”Type1“ から上記と同じ10個を選択し追加
欠損値のある列を削除して(下記参照)、アクションセットを適用→「確認」→「続行する」
ポケモンの中には1匹に2つのタイプを持つものがおり、そのようなポケモンのことを複合タイプと言います。このデータ内では1つ目のタイプを ”Type1” 、2つ目のタイプを ”Type2” と表現しています。全てのポケモンが複合タイプではないため、”Type2” には欠損値(詳しくはこちら)が存在します。
精度の高いAIを作るには、欠損値が取り除かれたきれいなデータに加工することが重要です。あらかじめアクションセットの編集で、”Type2”の列を削除しておきます。”Type2” をクリックすると、「前処理:アクションの詳細設定」の画面になります。この画面で「高度な操作」→「この列を削除」→「削除」と操作して、列を削除することができます。
また、“#”はポケモンの図鑑番号を表しており、”Type2” 同様、今回の予測では使用しません。上記と同じ方法で”#”の列に対して削除設定を行い、前処理を終えたら、右上「学習」ボタンをクリックし、学習画面へ進みます。


学習の進め方
「学習」画面に移動してきたと思います。画面右「モデルの新規作成」をクリックすると、モデルの作成画面が出現します。下記に項目の設定を箇条書します。
予測対象の列:予測したい項目を選択します。
今回はポケモンのタイプを予測したいので ”Type1”を選択
手法:”Random Forest”を選択
学習データとテストデータに分割:作成したモデルの精度を評価するときに選択→チェックを入れる
学習用データをすべて使ってモデルを訓練し、そのデータを用いて評価しても、モデルの精度の数値は出てきますが、モデルを作成した自分自身のデータで良し悪しを評価してしまうため評価方法として適切ではありません。そのため、データを事前に学習データとテストデータに分ける必要があります。

選択した内容に不備がないことを確認し、「開始」ボタンをクリックします。これで学習が始まりました。学習が終わり次第、評価結果をクリックし「評価結果」の画面へ移動します。
CatData無料版では、学習モデルは1つのみ作ることができます。
作成モデルの評価
評価結果では、学習データとテストデータそれぞれの精度が確認できます。精度とは、与えられた全データ中、正解したデータの割合であり、
精度=(正解数)/(与えられた全体数)
で求めることができます。それぞれの精度を確認すると、学習データでは精度が0.99125なのに比べ、テストデータでは0.28758と低い値となりました(図7)。このように、学習データの精度が高く、予測データの精度が低い状態のことを過学習と言います。学習データに適応しすぎて、予測したいデータに適応できなかったモデルのことを指します。

4. 過学習を改善してみる
過学習を改善するために、手法の変更と予測に用いるデータの変更を試してみます。
列の変更
Random Forestで得られた変数の重要度(図8)をみてみると、伝説のポケモンの有無を表す ”Legendary” と世代を表す ”Generation” はタイプの予測のための重要度は低いように見えます。そこで、 ” Legendary” と ”Generation” を除外したモデルを作成してみます。

「評価結果」画面の上部に「学習」というボタンがあります。それをクリックすると、「学習」画面に戻ります。
無料プランの場合は、2個以上のモデルを作成することができません。そのため、学習テーブル内に新たなモデルを作成するときは、既存のモデルを削除する必要があります。そこで、先ほど作成したモデルを「削除」ボタンをクリックし削除します(図9)。

モデルが正常に削除されたことを確認したら、「モデルの新規作成」をクリックし、「予測対象の列以外、全ての学習に使用」の項目のスイッチをオフにします。すると、学習用テーブル内が表示されるので、” Legendary” と ”Generation” の列のチェックを外します。「予測対象の列」は ”Type1” を選択し、「手法」はプルダウンメニューから Neural Network を選択し、「学習を開始」をクリックします。

混同行列を見てみると、学習データが0.99344でテストデータが0.3268になっており、またもや過学習になってしまいました(図11)。モデル構築に利用する列を変更してみたものの、学習データとテストデータの精度差は大きく、過学習は改善されませんでした。

手法の変更
次に、手法の変更により精度が改善するかを確認します。先ほどの学習ではRandom Forestという手法を使用していたので、Neural Networkという手法に変更してみます。
再度「モデルの新規作成」から「予測対象の列」では ”Type1” を選択し、「手法」はプルダウンメニューから ”Neural Network” を選択します。終わり次第、「学習の開始」をクリックします。
それでは学習をしてみましょう。混同行列を見てみると学習データ精度が0.29103でテストデータ精度が0.28758であることが分かります(図12)。学習データとテストデータの精度の差は無くなりましたが、2つとも精度が0.3以下と低く、良いモデルということはできません。

5. 種族値を用いたタイプ予測に関する考察
列を変更すると過学習に、手法を変更すると過学習は改善されましたが精度が低くなってしまいました。今回の解析を通して、タイプの予測は難しいと考えられます。
タイプの予測が難しい理由として3つ考えられます。
1つ目が、複合タイプがいることです。タイプが種族値に依存していると考えた時、2つのタイプを持つポケモンの種族値は、1つしかタイプを持たないポケモンに比べて依存しにくいと考えられます。
2つ目が、このデータにメガシンカのポケモンや伝説のポケモンが含まれていることです。メガシンカとは一部のポケモンしかできない戦闘方法です。戦闘中に発動すると種族値が高くなります。また、伝説のポケモンや幻のポケモンは他のポケモンと比べて種族値が高かったり全て100と特殊に設定されています。このメガシンカと伝説・幻のポケモンはタイプに依存しにくいため、予測がしにくいと考えられます。
3つ目が、ポケモンデータからタイプを予測するために必要なデータ量が少ないことです。データが少ないことでモデルが正しく学習することはできません。特に、今回は図3でみられるように、タイプごとの差が少ないので、タイプを十分に表せる種族値が足りなかったことが影響していると考えられます。
6. おわりに
今回はタイプの予測を行いましたが、テストデータの段階で過学習になってしまったり、精度が低くなってしまいました。過学習という言葉は知っていたのですが、今回初めて目にしたので私自身とても勉強になりました。
次回は、伝説のポケモンの予測をしていきたいと思います!
※ 筆者紹介
佐藤 美結(慶應義塾大学環境情報学部1年):植物の生態に興味があります。好きなものはポケモンです。機械学習、プログラミングを今年から学び始めました。
---
私たちは今年度から当社でインターンシップを始め、ワークショップのTAや機械学習ツールの使い方の紹介記事を執筆しています。今後も、AI構築の実際についてご紹介していきますので、お読みいただけると嬉しいです!
7. 関連記事
表データを利用したAI学習テキスト(Humanome CatData)
画像・動画を利用したAI学習テキスト(Humanome Eyes)
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!