
【初心者向け】はじめての画像認識AIテキスト:第2回「ものをみつけるAIの作り方」

こんにちは、ヒューマノーム研究所インターンの塩谷です。
この記事は初心者向けのノーコードAI構築ツール「Humanome Eyes」を用いて、物体検知AI(ものを見つけるAI)を作ってみよう、という連載の第2回目となります。前回の記事は以下のリンクからお読みいただけます。
前回は物体検知AIについての基礎知識として、物体検知AIができること、物体検知AIの構築の流れについてお話しました。
今回は前回の知識を踏まえ、身近なお菓子の画像を使って、実際に物体検知AIを作ってみましょう!AI構築の流れを示した下図の前半部分、画像を集めるところからAIに学習させるまでの手順についてお話しします。

ここから、「Humanome Eyes」というツールを実際に操作しながらAI構築の手順をご説明していきます。当社が開発する Humanome Eyes は画像の取り込みから精度評価までプログラミングなしで行うことができる物体検知AI構築ツールです。この連載内容は無料で実施できます。ご登録がお済みでない方は是非こちらからご登録下さい。
1. 画像を集める
物体検知AI作成の第一歩目は、学習に用いるデータ集めです。AIに特定してほしい物体が写った画像を用意しましょう。画像集めにはなかなかの労力が必要なので、今回は画像をあらかじめご用意しました。以下からダウンロードしていただけます。
◆ 今回の連載で利用する画像セット ◆
下図のように、ダウンロードしていただいたzipファイルを解凍すると kino_take_data という名前のファイルが新たに作られます。その中に入っている kino_take_image.zip がEyesにアップロードする画像データとなります。

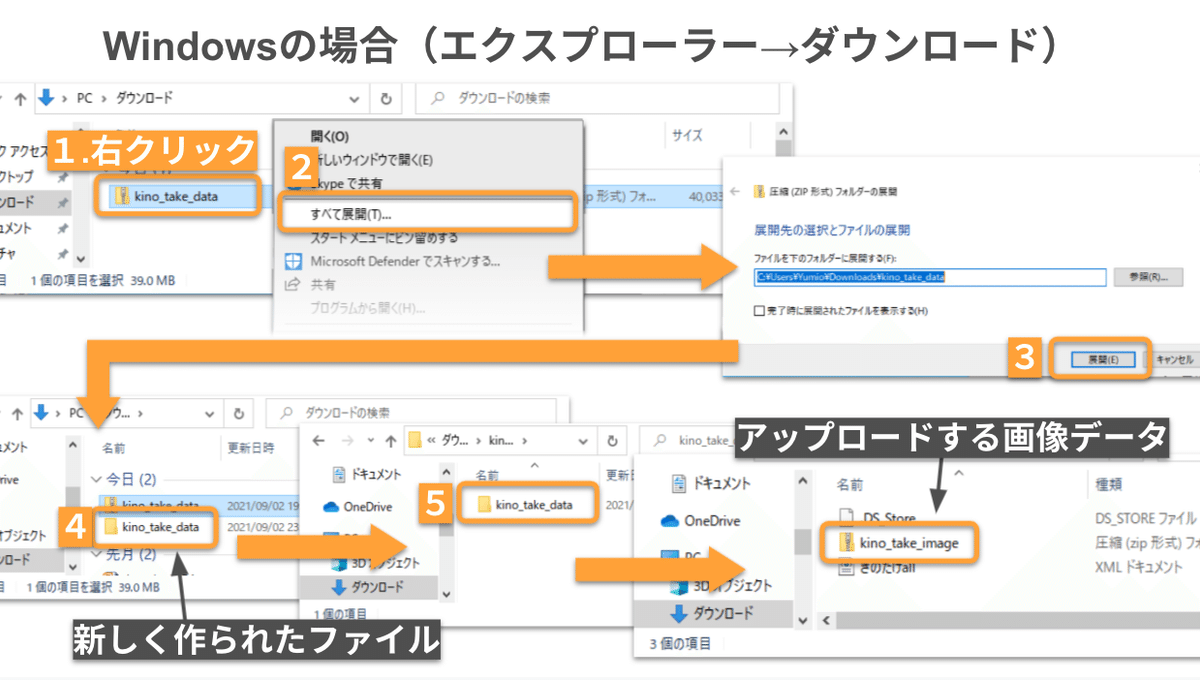
kino_take_image.zip の中には、2種類のチョコスナック菓子が写っている画像が24枚入っています。すでにお分かりかもしれませんが、今回はきのこ型・たけのこ型のお菓子を特定するAIを作っていきます!
AI構築の目的が決まり学習する画像を集め終わったところで、早速Eyesの操作に移ります。Eyesにログインしたあとのタスク一覧画面から始めましょう。下図のような手順で画像のアップロードとラベル(アノテーションの際に物体に付与する名札)の設定を行います。

以上の操作で、きのこたけのこ検知AIを作るためのタスクが作成されます。アップロード完了の通知(右上のバナーによる通知、または入力内容がリセットされる)を確認したら、タスク一覧からタスク詳細画面に移ります。
タスク詳細画面は、画像の枚数やラベルなどの基本情報の確認、アノテーションや学習の開始、作成されたモデルの一覧などを行うための基本画面となります。まずは以下のことを確認しましょう。
・タスク名称とラベルが設定したものであるか
・フレーム数が画像の枚数分(0〜23の24枚)だけあるか
・アノテーション数が0であるか
訂正箇所がある場合は以下の操作でタスクを削除し、タスクを作り直しましょう。訂正がなければアノテーション画面に移ります。

※ 精度評価を終えた後、AIを再作成する方
Humanome Eyesでは学習する画像・1セットにつき、1つのタスクを作成します。画像を変えて新たにAIを作成する場合は、都度新しいタスクを作成してください。Basicプラン(無料でお使いいただけるプラン)の場合はタスク数の上限が1個となるため、最初に作成したタスクを削除する必要があります。
2. アノテーション
次は、画像に対してアノテーションを実施します。アノテーション画面にアップロードした画像が表示されていますので、きのこに対しては「kinoko」ラベルを、たけのこに対しては「takenoko」ラベルを選んだ上で、表示されている場所を囲い、アノテーションをつけていきます。手順は下図をご参照ください。
1枚目の画像に写っている全ての物体にアノテーションをつけ終わったら、次の画像に移ってアノテーションをつけましょう。

※ 便利に使えるヒント!
ひとつの物体にラベルをつけたあとキーボード上の「nキー」を押すと、同じ種類の物体に続けてラベルをつけることができます。
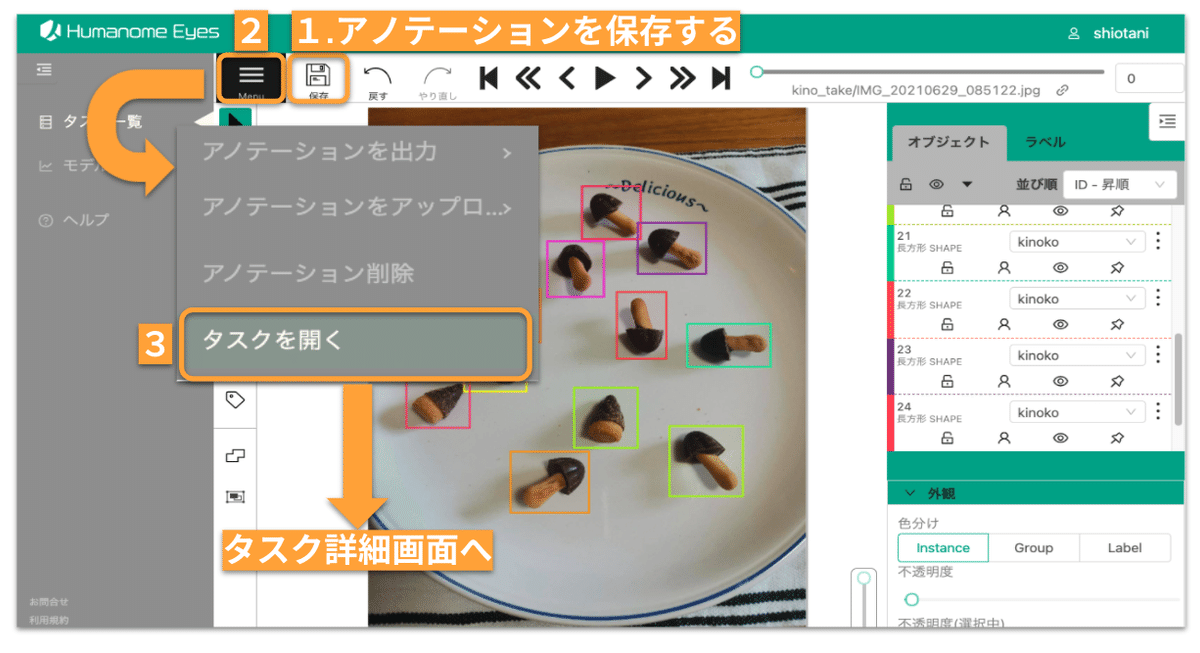
すべての画像でアノテーションが完了したら、以下の手順で保存し、タスク詳細画面に戻ります。
※ アノテーション作業を飛ばしたい方
アノテーションをつける作業をとばして先へ進めたいという方は、以下の手順で同梱されているアノテーションデータをご利用いただけます。
(なお、このアノテーションデータは、今回ご用意したきのこたけのこ画像にのみ対応しています。ご自分でご用意された画像を利用する場合は、手動でのアノテーションが必要となります。)

3. AIに学習させる
アノテーションが完了したら、いよいよAIに学習させます。タスク詳細画面から以下の手順で学習を開始します。学習モデルの状態が「学習中」から「完了」に変わったら、AIモデルの作成は完了です。モデル詳細画面に進みましょう。ここから先の精度評価は、次回の記事でお伝えしていきます!

※ 精度評価を終えた後、AIを再作成する方
画像を変えずに学習方法のみを変えてAIを作成し直す場合は、学習回数や学習率などのパラメータの値を変えてから学習を開始しましょう。精度の評価結果によって、パラメータの値をどのように変えるか?の方法が異なります。詳しくは次の記事でご説明する予定です。
4. 次回のお知らせ
今回は物体検知AI構築のベースとなる、画像集めからAIに学習させるまでの手順についてお話ししました。手順通り試してくださった方は学習が終わり、いよいよAIのお手並み拝見といったところかと思います。
次回は今回の続きから、作成したモデルの精度の評価方法と精度を高めるための方法についてお伝えします。ぜひお読みください!
※ 筆者紹介
塩谷 明日香(慶應義塾大学環境情報学部1年):人間と機械の知能の両方に興味があります。好きなことは模様替え。機械学習やプログラミングは学び始めたばかりの見習いです。
---
私たちは今年度から当社でインターンシップを始め、ワークショップのTAや機械学習ツールの使い方の紹介記事を執筆しています。今後も、AI構築の実際についてご紹介していきますので、お読みいただけると嬉しいです!
この連載は以下のリンクからまとめて読むことができます。
【参考】「表データでAIを作りたい!」という方向けテキスト
ペンギンについて調べた表データを使って、一連のAI構築・データ解析の流れを学べる無料テキストをnoteで公開しています。AI学習の最初の一歩にぜひお役立て下さい。
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!