
データサイエンス初心者がPythonとノーコードツールで同じデータを解析してみた|その2

こんにちは!株式会社ヒューマノーム研究所でインターンをしている佐藤です。この記事は、プログラミング初心者の私が、当社が開発するノーコードツールHumanome CatData(以下CatData)を用いてAI構築するのとPythonを書くのとで、どのくらい差が生じるのか比較しよう、という連載の第2回目です。第1回目の記事は、以下のリンクからご覧ください。
この連載では、機械学習入門でよく使われる、1912年に氷山に衝突し沈没したタイタニック号事故の乗船客についてまとめたデータセットを使用します。この海難事故の生存者をより高い精度で予測することを目標に設定します。この予測までの道のりを、主に、「可視化」「学習」「予測」の3つに分けてお話しします。
この記事では、Pythonを使ったプログラミング結果とCatDataの結果を比較するため、リンク先のコードを利用させていただきました。CatDataの操作と対応するコードを比較する場合は、こちらを適時参照してください。
また、解析で利用するGoogle スプレッドシート形式のデータは、前回と同じものを利用しています。元データとして、以下のKaggleのデータをお借りしています。
1. 「学習フェーズ」と「予測フェーズ」とは
AIの「学習」と「予測」の関係を下にまとめました。今回と次回は「学習フェーズ」について説明を進めます。

「学習フェーズ」はあらかじめ正解がわかっているデータをAIに学ばせてモデルを作成する段階、予測フェーズは正解がわからないデータを使って、学習フェーズで訓練したAIモデルで予測する段階を指します。
例えば、タイタニックデータの生存状況について予測したいと考えた時は、”Survived”(生存したかどうか)が存在するデータ用いてモデルを作成します。これが学習フェーズです。予測フェーズでは、”Survived”が存在しないデータに対して、学習フェーズで訓練したAIを用いて各乗客が生存したかどうかを予測します。
2. データの前処理:ノーコードツール編
AIに学習をさせ、精度の高い予測を行うためには、欠損値や欠損値が多い列の削除などの処理を施す必要があります。
まず、CatDataを使ってデータの状態をざっと確認します。前回の「可視化」で行った手順と同様に進めていきます。
1. テーブルの新規作成からデータを読み込み「学習」を選択し保存
2. ホームのテーブル一覧から、先ほど作成したテーブルを選択
3. テーブルの詳細にてアクションセットの編集をクリック
以上の操作で「前処理 1/2:アクションセットの編集」の画面に移動します。この画面で表示されているテーブルの中には、空欄になっているセルがあるかと思います。そのような空欄を欠損値と呼びます。

CatDataは、テーブルの確認画面内に各列の欠損値の行数を表示しており、どの列に欠損値があるか簡単に確認できます。タイタニックのデータの場合、”Embarked”, ”Age”, ”Cabin” の3列に欠損値があることがわかります。
欠損値があるとAIが学習できないため、あらかじめデータから欠損値を除く必要があります。
CatDataの欠損値を除く方法には「欠損値の削除」「欠損値の補間」「列の削除」の3種類があります。操作概要は以下の図のとおりです。操作詳細について順に説明します。

2-1. 欠損値の削除の方法
出港地を表す ”Embarked” の欠損値は2行と少ないため、欠損値のある行を削除することで対応します。以下の操作で、欠損値のある行を削除できます。
1. テーブルの列から”Embarked”をクリック
2.「前処理 1/2:アクションの詳細設定」へ移動
3. 以下の順にクリック:「高度な操作」→「欠損値の削除/補間」→「欠損値の削除」→「アクション追加」
2-2. 欠損値の補間の方法
年齢を表す”Age”には177行の欠損値があります。全体の 19.9%にあたる177行分の空欄を削除すると、学習が十分にできない可能性があるため、今回は欠損値を削除するのではなく平均値で補間していきます。欠損値の補完手順は以下のとおりです。
1. テーブルの列から”Age”をクリック
2.「前処理1/2:アクションの詳細設定」に移動
3. 以下の順にクリック:「高度な操作」→「欠損値の削除/補間」→「欠損値の補間」→「平均値」→「アクション追加」
2-3. 列の削除の方法
客室番号を表している”Cabin”には欠損値が687行あり、項目全体の77.1%の割合を占めています。この欠損値を全て消すと、全体の22.9%のデータしか残りません。これでは、十分に学習できない可能性が高くなってしまいます。
このような場合は、”Cabin”の列ごと全て消してみましょう。列自体を消す方法は以下のとおりです。
1. テーブルの列から”Cabin”をクリック
2.「前処理1/2:アクションの詳細設定」に移動
3. 以下の順にクリック:「高度な操作」→「この列を削除」→「削除」
また、乗客者IDを表している”Passenger ID”は乗客を区別するためにつけられた番号です。各乗客の生存予測では使わない項目なので、先ほどと同じ手順で”Passenger ID”の列を削除します。
2-4. 登録した欠損値処理の実行
これまでに「出港地の欠損値の削除」「年齢の欠損値の補間」「客室番号列の削除」「乗客者ID列の削除」、以上4つのアクションの実施内容を登録してきました。この登録内容をテーブルに反映させるために、「アクションセットの編集」の画面右下にある「適用」ボタンをクリックします(下図)。
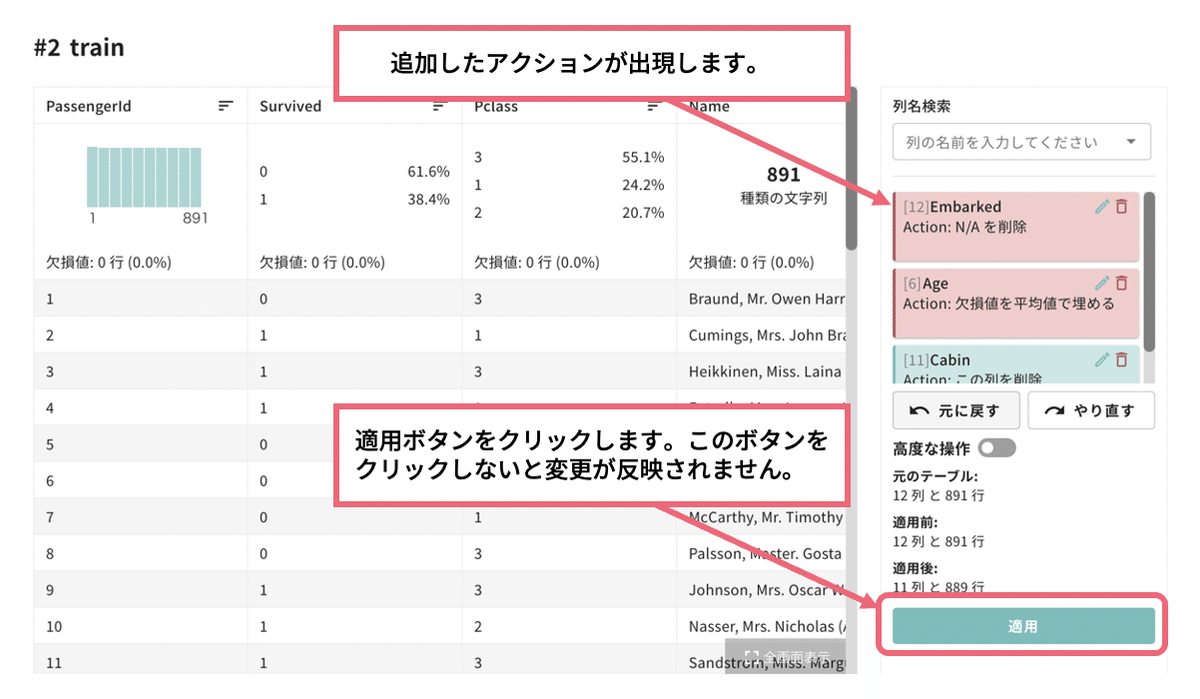
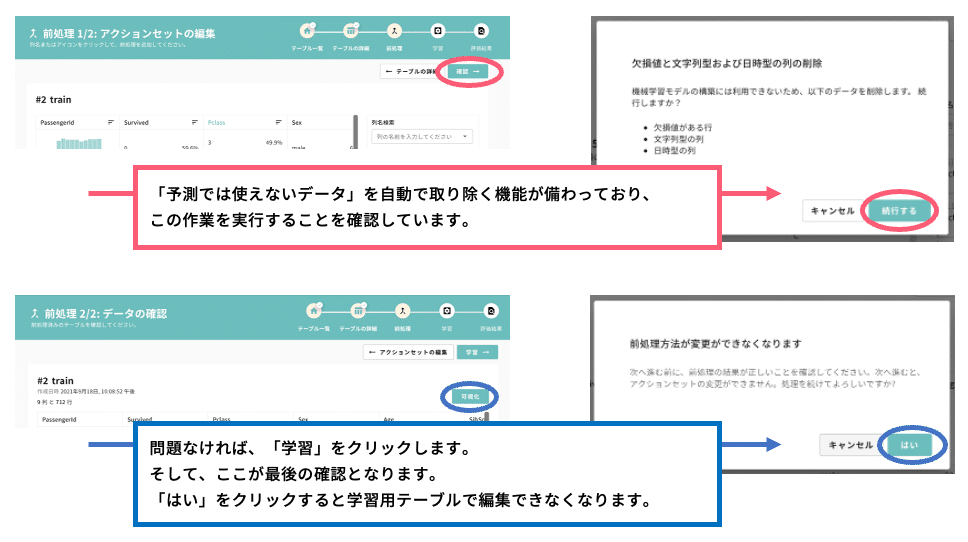
その後、画面上部の「確認」ボタンをクリックすると、「欠損値と文字列型および日時型の列の削除」についての確認が出てくるので「続行する」をクリックします。CatDataには「予測で使えないデータ」を自動判定して取り除く機能があり、この操作で当該機能の実施確認をとっています。
「続行する」をクリックすると、画面が「前処理 2/2:データの確認」に移ります。右上にある「学習」ボタンをクリックすると、学習開始前の注意として「前処理方法が変更できなくなります」というメッセージが表示されます。これ以上変更する項目がなければ、「はい」をクリックし「学習」画面へ移動します。
3. データの前処理:Python編
これまでに行った欠損値の処理に関する操作をPythonで実行しようとすると、以下の関数を順に適用することになります。
・欠損値の行数を数える:df.isnull().sum()
・欠損値の削除
行の削除: df.dropna(subset=[対象の列])
平均値の補間:①+②
① 平均の計算:df[対象の列].mean()
② 対象の補間:df.fillna({対象の列: 計算した平均の値})
・列の削除: df.drop(対象の列, axis=1)
Pythonを使う場合、「欠損値の行数を数えるコード」と「欠損値を削除するコード」をそれぞれ書く必要があります。コーディングしながらデータを確認したい場合、そのたびに出力して、出力内容を確認して、削除して、また出力するといった流れでコードを書かないといけません。
また、欠損値の削除、補間、列の削除はそれぞれ別の関数を使い、項目ごとのグラフを見たい時は、ライブラリを導入したり、Excelなどの表計算ソフトを別途用いる必要があります。前処理のコーディングは確認事項が多く、私はコーディング中に大変混乱しました。
また、Pythonでは、学習に適さない列が存在する場合、学習前に入るところでエラーが出て、対象となる値を再度削除する操作が必要ですが、CatDataは自動で適さない列を判定した上で削除する機能があり、操作ミスがあってもシステムがフォローしてくれるのは楽だな、と思いました。
次回は学習編の後半、「AIの学習」の流れについて見ていきます。是非お読みください!
このシリーズは以下のリンクからまとめてお読みいただけます。
※ 筆者紹介
佐藤 美結(慶應義塾大学環境情報学部1年):植物の生態に興味があります。好きなものはポケモンです。機械学習、プログラミングを今年から学び始めました。
---
私たちは今年度から当社でインターンシップを始め、ワークショップのTAや機械学習ツールの使い方の紹介記事を執筆しています。今後も、AI構築の実際についてご紹介していきますので、お読みいただけると嬉しいです!
【参考】もっと細かく手順を知りたい方へ
ペンギンについて調べた表データを使って、一連のAI構築・データ解析の流れをCatDataを通して学ぶテキストを無料公開しています。データ解析で使われる用語をイチから知りたい方はあわせてご覧ください。
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!