
Humanome CatData|最近の機能追加だより【2022年11月18日号】

はじめまして。ヒューマノーム研究所で研究員をしているはなと言います。
2022年も年末が近づいておりますが、みなさまいかがお過ごしでしょうか。
私はHunanome CatDataとHumanome Eyesの展示会出展に向け、てんやわんやな毎日を過ごしています。当社のサービスを下記の展示会で紹介する予定です。ぜひ、会場へお越しいただけるとうれしいです。
前回、Humanome CatData(以下、CatData)の最新の機能紹介をしてから間があいてしまいましたが、その間もCatDataは日々進化しています。
今回は2022年7月以降のCatDataのアップデートについてまとめてご紹介しようと思います。
機械学習モデルの充実
Kaggleなどのデータ解析のコンペでよく使われている下記の機械学習モデルが、CatDataで学習できるようになりました!
XGBoost
LightGBM
どちらの手法も、下記の記事で使っているRandom Forestと同様に、AIモデルが何を重要視して予測しているのか?がわかる手法です。
モデルを作成するときに「手法」のタブから選択できます(図1)。ぜひ使ってみてください。

モデルを評価する指標の追加
モデルの評価でよく使われる指標の一つ、決定係数(R2)をCatDataに追加しました。2022年8月4日以降に作成した回帰モデルは、R2を評価結果のページに示しています(図2)。
CatDataを使って数値を予測するモデルを構築する方法は、下記の連載でご紹介する予定です。第二回の原稿は鋭意執筆中ですので、楽しみにお待ちください。
これまでは、数値を予測するモデルに対して、CatDataではMSE(平均二乗誤差)という評価指標を計算していました。
MSEは予測値と正解値がどれくらいずれているのか?を測る指標です。全てのデータで「モデルの予測値=正解値」であればMSEは0.0になります。逆に、予測値と正解値の差が大きい、つまり精度が低いモデルであるほどMSEが大きくなります。
MSEは値の上限がありません。個人的には評価指標がMSEだけだと直感的に良し悪しが判断しづらいかな、と思っていました。
今回追加したR2は、予測値と正解値が一致しているほど1.0に近くなり、予測値がはずれていると値が小さくなります。おおよそのケースでR2の値は0.0〜1.0です(予測が全く当たらないモデルだと、値が0.0より小さくなることもあります)。
モデルを評価するときには、「この指標が高いからOK」という状況はほとんどなく、いくつかの指標を参照して総合的に判断することが多いです。MSEやその下に表示している散布図に加えて、今回追加したR2も参考にしてモデルの良し悪しを評価していただければと思います。

対数変換の機能を追加
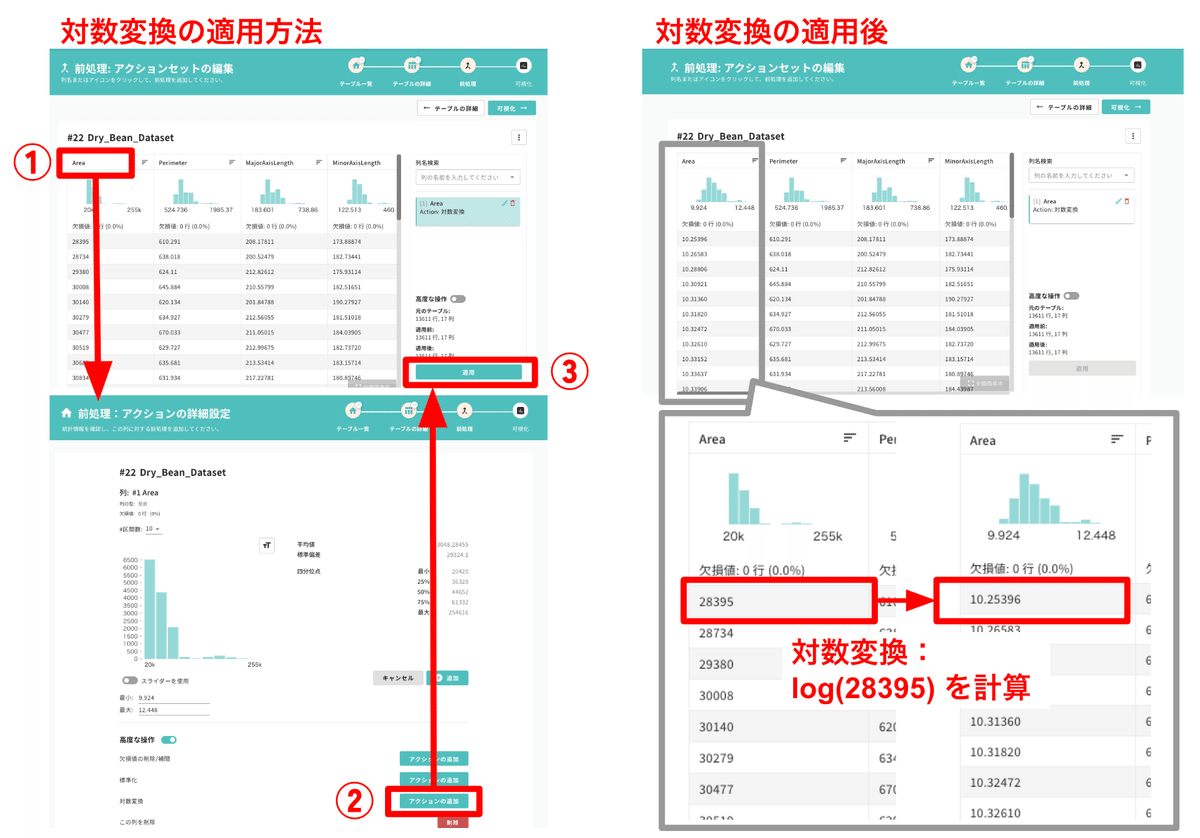
2022年9月28日のアップデートから、CatDataで簡単に対数変換を行えるようになりました。分布に偏りがある場合など、観測した数値に対して対数をとりたいときに使ってみてください。対数変換した後のデータの分布、平均や標準偏差などの統計値もわかります(図3)。

この機能は、利用目的が「可視化」や「学習」となっているテーブルの「前処理:アクションセットの編集」の画面内で利用できます。以下の手順を実施してみてください(図4)。
対数変換したい列の列名をクリック
「高度な操作」を開き、対数変換の「アクションを追加」をクリック
前処理:アクションセットの編集の画面に戻るので、右下の「適用」をクリック
手順3で「適用」をクリックすると手順1で選択した列に対して対数が計算され、緑色のヒストグラムも自動で更新されます。
おわりに
今後も皆様の声を参考にCatDataのアップデートを行う予定です。こんな機能が欲しい!という要望がありましたら、ぜひお聞かせください。
今後とも、Humanome CatDataとHumanome Eyesをどうぞよろしくお願いいたします!