Google Colaboratoryで、Chat GPT APIを活用した音声解析の方法を簡単解説!

こんにちは、ひろきです!
最近非常に話題になっているChat GPTについて、私もやっと調査を始めることができました。驚くべき使い方が数多くある一方で、業務で使用する際にはいくつかの課題が見つかっています。これらの課題を適切に整理していくことが重要だと感じています。
さて、まずはどんなことができるか試してみたいと思います。今回は、GPT-4のAPIを活用して、Google Colaboratoryで音声解析の方法をコードベースでまとめてみます。GPT-4では画像も扱えるようになっているとのことです。今後はテキストだけでなく、画像・動画・音声の分野への発展が期待できるため、今のうちにしっかり理解しておきたいと思います!
更新履歴:
[2023-04-3 Sun] 初版
【第1章】まずは、動かしてみることから
早速ですが、Google Colaboratoryで、音声データをテキストに変換するプログラムを動かしていきましょう。
Google Colaboratoryで、音声データをテキストに変換(文字起こし)する方法
Google Colaboratory(通称:Colab)は、Googleが提供するクラウドベースのJupyterノートブック環境です。Pythonをはじめとするプログラムをブラウザ上で編集、実行、共有できるため、特別な設定やインストールが不要です。今回は、皆さんが簡単に利用できるように、このColabを活用します。
まず、最初にpipコマンドを使用して、必要なOpenAIのモジュールをインストールしていきたいと思います。以下のように、コードを記載してください。

!pip install openaiGoogle Driveから音声データを参照するために、まずDriveをマウントしましょう。以下のコードをColabノートブックに入力して実行してください。
実行後、表示されるURLにアクセスし、Googleアカウントを選択して認証コードを取得してください。取得した認証コードをColabノートブックに戻って、入力欄にペーストし、エンターキーを押すことでDriveがマウントされます。
from google.colab import drive
drive.mount('/content/drive')念のため、ファイルが正しく参照できているかチェックしておきましょう。<音声ファイル名>の部分に、自分で作成した音声ファイル名を入力してください。
import os
audio_file_path = '/content/drive/MyDrive/<音声ファイル名>'
if os.path.exists(audio_file_path):
print("ファイルが存在します。")
else:
print("ファイルが存在しません。")OpenAIをインポートし、APIキーの設定を行いましょう。<API KEY>の部分に自分のAPIキーを入力してください。
import openai
openai.api_key = "<API KEY>"APIキーの発行は、OpenAIのウェブサイトで行うことができます。以下の手順に従ってAPIキーを取得してください。
OpenAIのウェブサイトにアクセスし、アカウントを作成またはログインしてください。
ダッシュボード画面に移動し、左側のメニューから「API Keys」をクリックしてください。
「Create an API key」ボタンをクリックし、APIキーが生成されます。
生成されたAPIキーをコピーし、先ほどのColabノートブックの<API KEY>部分に貼り付けてください。
これで、OpenAIのAPIキーの発行と設定が完了します。
ここまでの準備が完了しました。openai.Audio.transcribeを使用することで、簡単に音声データをテキストに変換(文字起こし)することができます。
with open(audio_file_path, "rb") as audio_file:
response = openai.Audio.transcribe("whisper-1", audio_file)
transcript_text = response.text
print(transcript_text)これで、音声データの文字起こしが表示されたはずです。詳細については、OpenAIのドキュメント「Speech-to-Text」(音声からテキストへ)を参照してください。
お金がかからないように、節約が必要! Part.1
私の検証によると、約10分の音声データを文字起こしするのにおおよそ0.05ドル程度の費用がかかります。音声データを扱う際には、知らず知らずのうちにAPIを何度も利用してしまうことがあるため、コストが継続的にかかることがあります。そこで、一度文字起こししたデータをテキスト形式でGoogle Driveに保存し、そのテキストデータを読み込むようにすると、コストを抑えることができるでしょう。
output_file_name = "/content/drive/MyDrive/test_audio.txt"
with open(output_file_name, "w", encoding="utf-8") as file:
file.write(transcript_text)きちんとテキストデータの読み込みができるかも確認しておきましょう。
text_file_name = "/content/drive/MyDrive/test_audio.txt"
with open(text_file_name, "r") as text_file:
transcript_text = text_file.read()
print(transcript_text)先ほどの文字起こししたデータが表示されている場合、openai.Audio.transcribe の関数のコードをコメントアウトしておくと安心ですね。
成果物を評価する審美眼が重要!人とAIの共創にはプロンプトエンジニアリングの習得が必須!
これからの時代、人には、AIにより成果物の品質を見極める審美眼が不可欠です。人とAIが共創してより良いアウトプットを生み出すために、プロンプトエンジニアリングのスキルを身につけましょう。これにより、AIの潜在能力を最大限に活用できる可能性が広がります。
プロンプトエンジニアリングは、OpenAIの言語モデルを使用する際に、正確で有効なプロンプトを作成するための方法論です。
言語モデルに対して特定のタスクを実行するための指示を与えることで、モデルがより適切な回答を生成できるようになります。プロンプトエンジニアリングは、AIの「巨大言語モデル」による回答の質を高めるための手法として注目されています。プロンプトエンジニアリングは、ChatGPTをはじめとする言語モデルに対して効率的に意図を伝えるための手法として、最近では需要が高まってきています。
具体的には、プロンプトエンジニアリングでは、問いかけの仕方や情報の与え方に工夫を凝らすことで、言語モデルにより適切な回答を生成させることができます。
なお、プロンプトとは、言語モデルに与える入力文のことを指します。プロンプトには、特定のタスクを実行するための指示が含まれており、適切なプロンプトを作成することで、言語モデルがより適切な回答を生成できるようになります。
今回抽出した文章に関して、簡単な要約を出してみましょう。ここでは、OpenAI APIのText completion機能を利用します。
OpenAI APIのText completion機能は、APIのエンドポイントの一つで、自然言語処理モデルを使用して、テキスト補完を行います。この機能では、入力したテキストのコンテキストやパターンに基づいて、自動的に次のテキストを補完することができます。
ここでは、text_summaryという関数を定義し、text-davinci-003を使用して要約を生成したいと考えています。
def text_summary(prompt):
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=500,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0,
)
return response["choices"][0]["text"].replace('\n','')pre_prompt = '''
以下の<場面指定>における文字起こしデータから<主に抽出したいポイント>に関して、1文に要約してみてください。
# 文章
'''
post_prompt ='''
Tl;dr
# 要約
'''
prompt = pre_prompt + transcript_text + post_prompt
print(text_summary(prompt))皆さんが試してみた音声に関する要約の精度はどの程度でしたか?ぜひその高い精度を実感してみてください。
お金がかからないように、節約が必要! Part.2
Chat GPTのAPIサービスは、トークン量に基づいて料金が発生するため、トークン量をできる限り削減することに注力していきましょう。そのため、入力されたテキストをそのまま送信せずに、APIに送信する前に英語に変換して、トークン量を減らすようにすることも可能です。
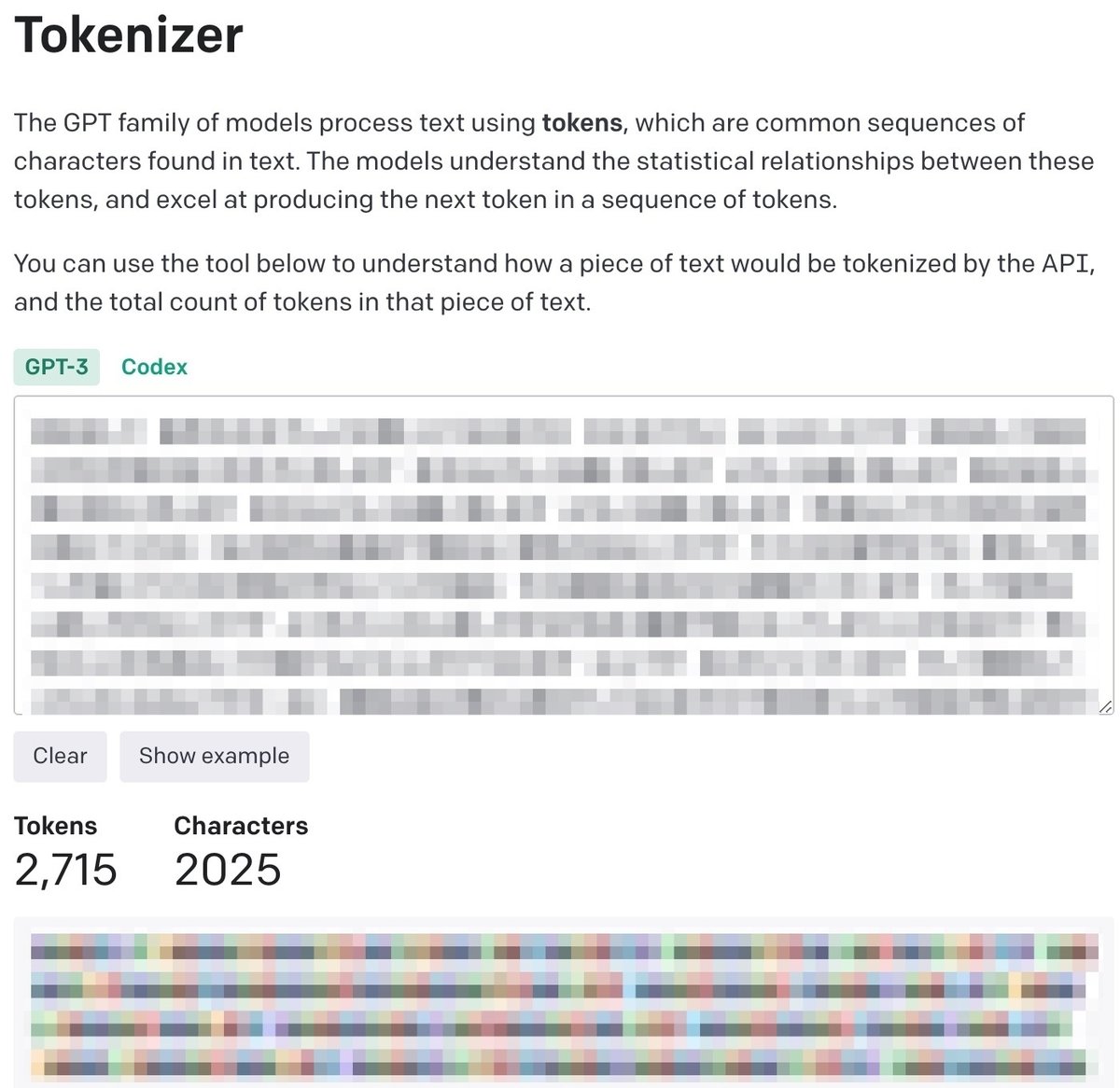
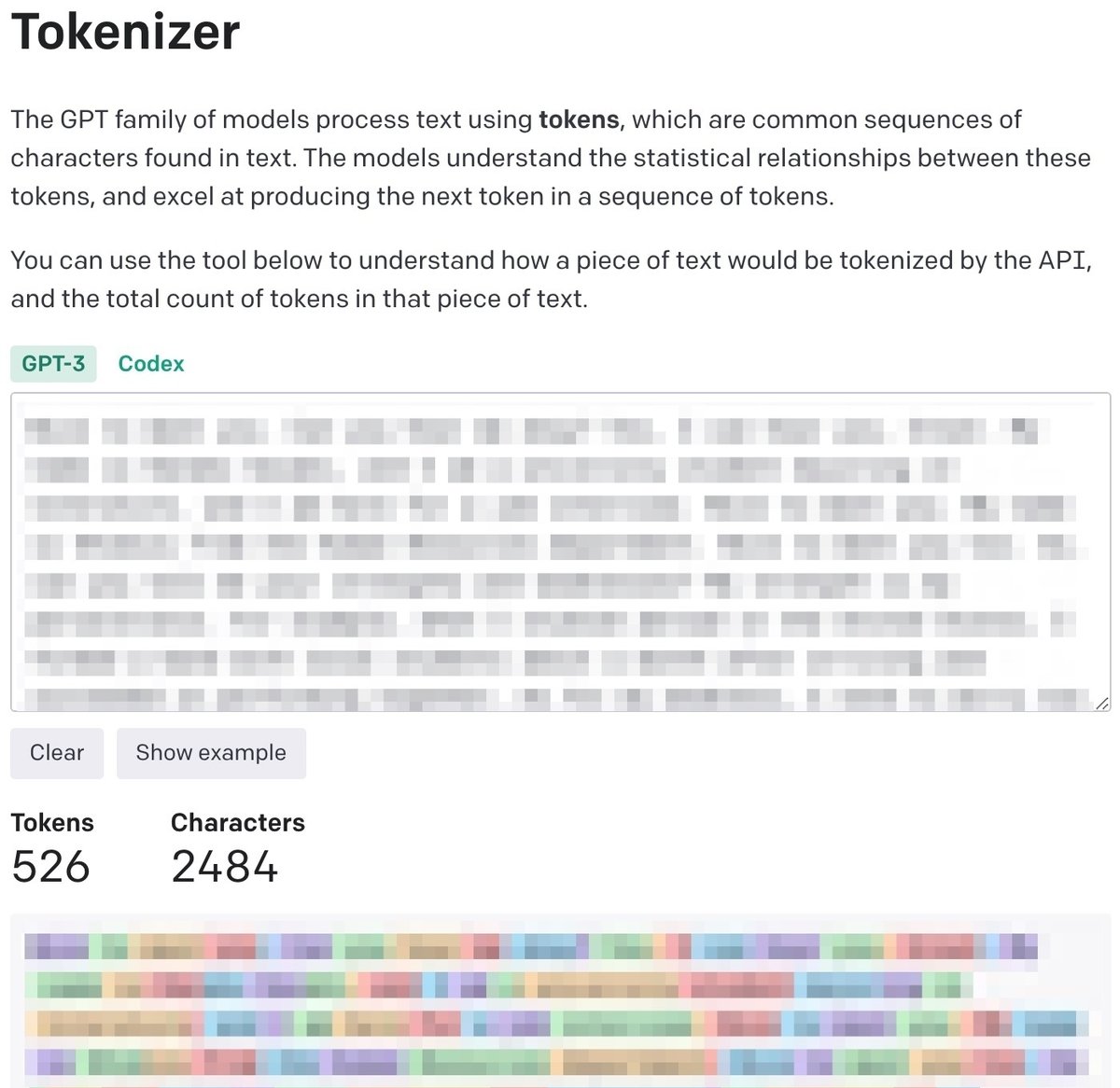
こちらのTokenizerサイトでトークンの計算がシミュレーションできます。たとえば、「こんにちは」という日本語の場合、トークン量は6になりますが、英語の場合は「Hello」という1つのトークンになります。
とある10分ほどの音声動画をTokenizerで確認すると日本語では2715Tokensで、英語では526Tokensという結果が得られました。
より費用対効果の高いサービスの活用をしていきましょう。
まとめ
Google Colaboratoryを使用することで、簡単に音声データをテキストに変換(文字起こし)できます
音声データはコストがかかるため、その点を意識して扱う必要があります
要約したい内容には、プロンプトエンジニアリングが重要になります
【第2章】Whisperの音声認識精度
先人の方の知恵を拝借しましょう!
音声の認識精度に関する検証は、多くの方々によって行われており、ここでもいくつか参考にさせていただいています。
RevCommのリサーチチームの中田亘さんの記事になります。OpenAIが提供しているbaseモデルおよびlargeモデルの認識精度・認識速度について調査になります。
Whisperの音声認識精度および認識速度の検証
※ こちらのノートも引き続き拡充していきたいと思います。
ご興味いただけた方へ
・キャリアの相談してみたいメンバーの方
・マネジメントで苦悩するマネージャーの方
・組織開発・人材開発でお悩みの経営・人事の方
TwitterのDM、Careenaやストアカと皆さんのご興味に合わせて連絡ください。是非、一度気軽にお話ししてみませんか?
参考書籍
参考記事
Colab へようこそ
「Speech-to-Text」(音声からテキストへ)
【徹底解説】これからのエンジニアの必携スキル、プロンプトエンジニアリングの手引「Prompt Engineering Guide」を読んでまとめてみた
AIの思考を人間が助ける「プロンプトエンジニアリング」、能力の劇的進化に要注目
GPT-3の要約機能を試してみた(Python)
今流行りのChatGPT(OpenAI)のAPIを使った名前ジェネレーターを作った