データどれが本命?(ソフトウェア分析)


データの代表は平均値?
収集した多数のデータから代表値として1個だけ選ぶとき、どうすればいいでしょうか。やはり平均を出して、その平均値をデータの代表にすることが多いでしょう。
平均値は小学校5年生で習いますので、代表値として一番なじみがあるのがこの平均値です。だから「平均値でよくね?」となります。この平均値にいちゃもんを言うと、平均的な日本人から平均的に変な目で見られます。
小学5年生で習う算術平均は相加平均とも呼ばれ、データの値を加算した合計数をデータの個数で割って平均値を出します。なお算術平均は、平均的な日本人からは単に平均と呼んでいます。
算術平均はデータの散らばり具合(分散)に偏りがないときは代表値として使えます。逆に言えば分散に偏りがあるときは注意が必要です。
偏りがあるとき平均値はダメ
データに偏りがあるときの代表値は何がいいでしょうか。例えば貯蓄額の代表値を出すときには何を使えばいいでしょうか。
100億円の貯蓄をしている人が一人いるだけで、100万円の貯蓄をしている人が1000人いても、平均は約200万円になります。ほとんどの人が平均の半分しか貯蓄できていません。なぜ?もちろん犯人は100億円です。
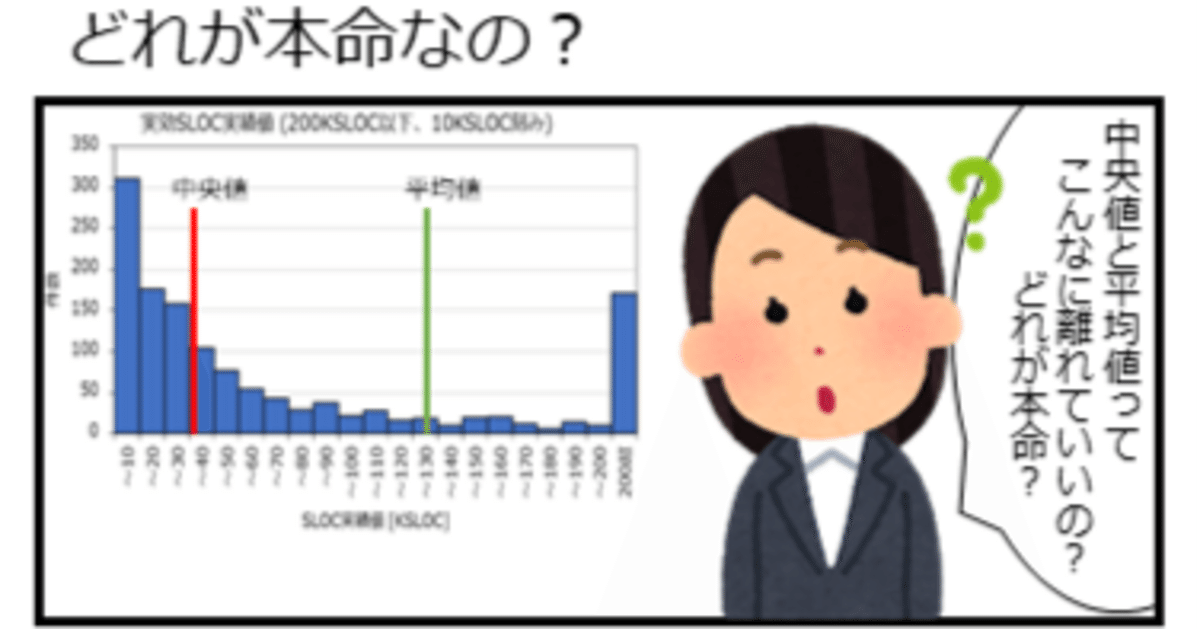
このように平均値はデータに偏りがあるときには使えません。ソフトウェア開発ではバグ数をはじめ、コード行数など規模など、多くのデータがそうなります。なぜならソフトウェア開発の多くはマイナスのデータはなく、プラスは限りなく大きくなってしまいますから。
偏りがあるときの代表値は中央値
ではこのように偏りがあるときは、片方向に伸びるデータのときは、中央値がいいでしょう。中央値はデータを順番に並べたときに中央に位置するデータの値になります。偶数のときは中央の二つの平均を取ります。なんていったって中央なのですから、中心なのは明らかです。
実際にバグ密度(信頼性)や生産性は中央値を代表値にしています。
中央値でもダメなとき
ソフトウェア開発での代表値は中央値でおけまる(o.k.で〇)以上。・・・とはいかないのが残念なところです。そもそも全体の代表値がないような分布、例えば、二山分布(山が2個ある分布)では二つの派閥の各々の代表値は出せますが、全体の代表値は出しにくいです。二派で戦争が起こるかもしれません。なお、このようなときは二派で層別にして、各々で分析するのが平和です。
例えば、スクラッチ開発とノーコード・ローコード開発を一緒くたに分析すると、このような喜劇/悲劇が起こります。気を付けてください。
ということで今日の結論。「データの代表は中央値がベター」以上です。
マンガFAQの引用元:ソフトウェア開発分析データ集2022 | 社会・産業のデジタル変革 | IPA 独立行政法人 情報処理推進機構
いいなと思ったら応援しよう!
