
GPT:統計的因果プロンプティングで因果推論

はじめに
以下は、AIDBによる𝕏のポスト。
LLMで因果推論(何が何を引き起こすかの分析)を行うプロンプト手法「統計的因果プロンプティング」が考案されています。
— AIDB (@ai_database) June 8, 2024
滋賀大、東京医科大、京大、広島大、理研、東大、NIIの研究者らによる発表。https://t.co/QmScXHOYFs
実験では気候データや健康データの分析で一定の性能を示しています。
実践的な統計的因果発見(SCD)において、アルゴリズムにドメイン専門家の知識を制約として組み込むことは、一貫性のある意味のある因果モデルを作成するために重要です。
本研究では、SCD手法と大規模言語モデル(LLM)を通じた知識ベースの因果推論(KBCI)を「統計的因果プロンプティング(SCP)」と呼ばれる手法で統合する新しい因果推論の方法論を提案します。
実験により、GPT-4がLLM-KBCIと事前知識を用いたSCDの結果を真実に近づけることができることが明らかになりました。また、公開されていない実データセットを使用して、LLMが提供する背景知識がこのデータセットに対してSCDを改善できることを示しました。
このアプローチは、データセットのバイアスや制限といった課題に対処できることを示し、LLMが多様な科学領域でデータ駆動の因果推論を改善する可能性を示しています。
上記引用は、論文「Integrating Large Language Models in Causal Discovery: A Statistical Causal Approach」のアブストラクト(日本語訳)です。
ちなみに、SCP, SCD, LLM-KBCI は以下です。
SCP :Statistical Causal Prompting(統計的因果プロンプティング)
SCD :Statistical Causal Discovery(統計的因果発見)
LLM-KBCI :Knowledge-Based Causal Inference using Large Language Models(大規模言語モデルを利用した知識ベースの因果推論)
なんだか難しそうですが、ざっくりまとめると、
LLMの背景知識で統計的因果発見を改善するってことかな。
ChatGPTにデータを与えて「因果関係を推論して」ってだけでも、ある程度やってくれそうですが、
まず事前知識なしでデータセットの因果を統計的に探り、LLMから得られた知識を事前知識なしの結果に統合、統合された因果モデルとドメイン知識を使用して、データセットを再構成(再咀嚼)。。。
なんかすごそう😁。
ってことでプロンプト(=GPT)を作成してみました。
統計的因果発見とLLMを用いた知識ベースの因果推論を統合するプロンプト
このプロンプトを使うと、以下のことができます:
📊 データセットの解析:
観測データから因果関係を発見します。統計的手法を用いてデータを分析し、隠れた因果関係を明らかにします。
🧠 ドメイン知識の活用:
専門知識を取り入れて、因果関係をより深く理解します。大規模言語モデルが持つ膨大な知識を活用し、データ分析の精度を高めます。
❓ 質問と回答:
データや因果関係に関する具体的な質問に答えます。ユーザーが持つ疑問に対して、明確な回答を提供します。
🔄 フィードバックの反映:
ユーザーや専門家のフィードバックを取り入れて、分析結果を継続的に改善します。フィードバックループを活用し、モデルの精度を向上させます。
🔬 実験結果の検証:
実際のデータ分析や実験結果をもとに、因果関係を検証します。得られた結果の信頼性を確認し、実用的な因果モデルを構築します。
🌐 外部データの利用:
補完的な情報を提供する追加のデータソースを使用して、因果関係を強化します。外部データを統合することで、分析の精度と信頼性を向上させます。
このプロンプトは、これらの要素を統合することで、因果関係を高い信頼度で理解する手助けをします。複雑なデータ解析を効率的に行い、ユーザーがデータに基づいた意思決定を行うための強力なツールとなります。
実行例
このGPTでやってみたかったのは、「顧客の意見」の因果関係の理解。
因果の精度の面もありますが、現実は薄いコンテキストの意見が多いので豊かになることも期待。
この実行例では、ChatGPTに仮想させた以下の意見(ビデオドアインターフォンに関する意見)を与えました。
意見:[「ビデオドアインターフォンは、使いやすくて便利です。しかも、防犯面でも安心できます。」,「ビデオドアインターフォンの画面が小さいため、見づらいと感じることがあります。画面サイズの拡大を検討してほしいです。」,「ビデオドアインターフォンの配線や設置場所がわかりにくかったため、施工に時間がかかってしました。取り付けに関する情報をもう少し充実させてほしいです。」,「ビデオドアインターフォンの設置場所が狭いため、取り付けが難しかったです。もう少しコンパクトなデザインになっていると、施工のしやすさが向上するかもしれません。」,「ビデオドアインターフォンの設置にあたり配線が複雑でした。素人が施工を行う場合は、配線が難しいと感じることがあるかもしれません。」,「ビデオドアインターフォンの取り付けにあたって、工具や器具が必要でした。」,「ビデオドアインターフォンの操作が複雑で、使いにくいという声がある。特に、年配の方や技術に疎い方にとっては、操作が難しい。」,「ビデオドアインターフォンの画質が悪く、顔がはっきりと見えない場合がある。特に、暗い場所での映像が見づらい」,「現行の製品では、映像・音声が荒く、聞き取りづらいことや正常に通話できない場合がある。」,「ビデオドアインターフォンは、玄関ドア横の壁に取り付けるため、配線の引き回しや設置場所を施工前に確認する必要があります。」,「既存の配線との調整が必要な場合があります。」,「本体の取り付けは、壁掛け式や取り付けブラケット式などに対応して欲しい。」,「ビデオドアインターフォンが正しく取り付けられているか、映像や音声が問題ないかを確実にしたい。」,「他社のビデオドアインターフォンと比較して、この製品は特に耐久性が高い印象を受けました。製品の耐久性に関する情報をもっとアピールしてほしいです。」,「操作性が簡単でわかりやすい製品、明るく鮮明な映像を提供する製品は販売しやすい。」]
この意見で「因果発見の改善」を実行した後、mensionで「Eraser Diagrams」を呼び出して、因果関係を図化したのが以下です。
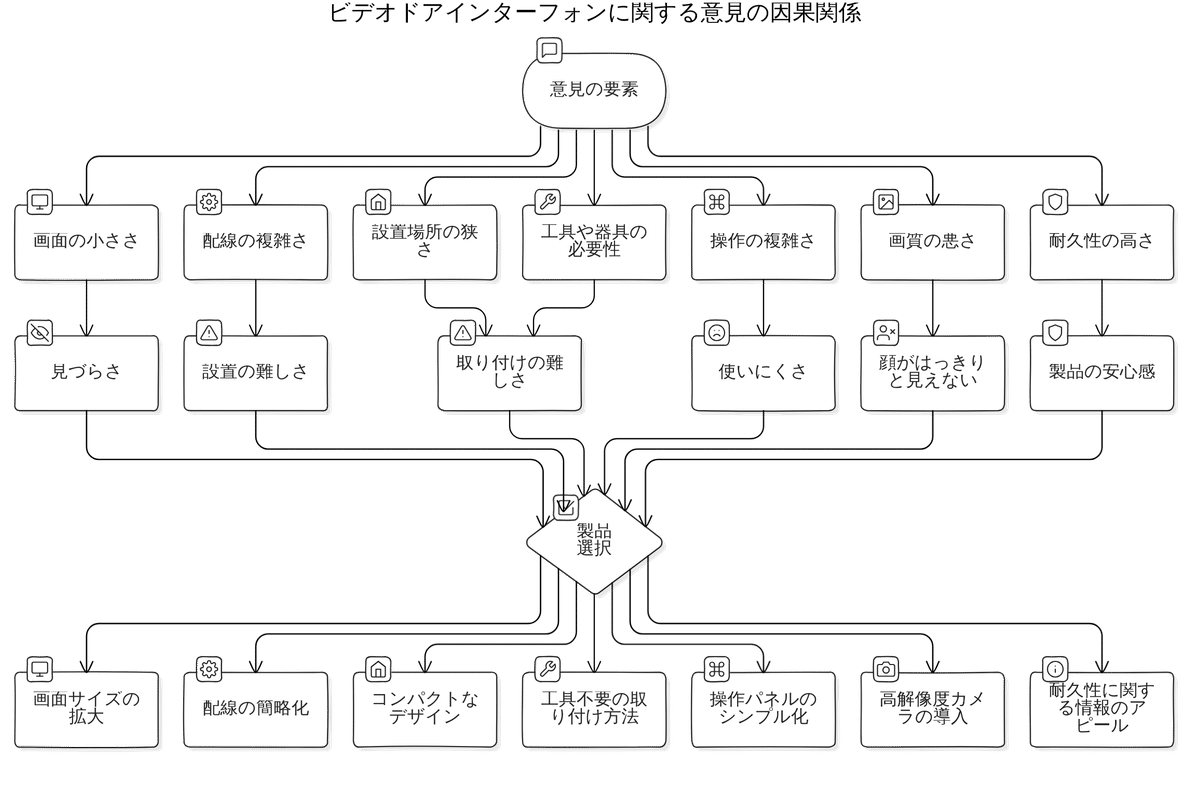
SCPのアプローチにより、
意見からの要素の抽出、LLMによるコンテキストの拡張を実行してくれました。
実行によって吐き出される内容を読み進める過程で、因果の理解が進みますし、意見要素毎の因果のブレも少ないように思いました。
ただ、(私のプロンプトによるところが大きいと思いますが)実行にブレやクセがあるのと、意見全体の因果を如何に表現するか?において、結果が安定しなかったりするので、SCPのステップを噛み締めつつマニュアルで進めた方がよいかもしれません。
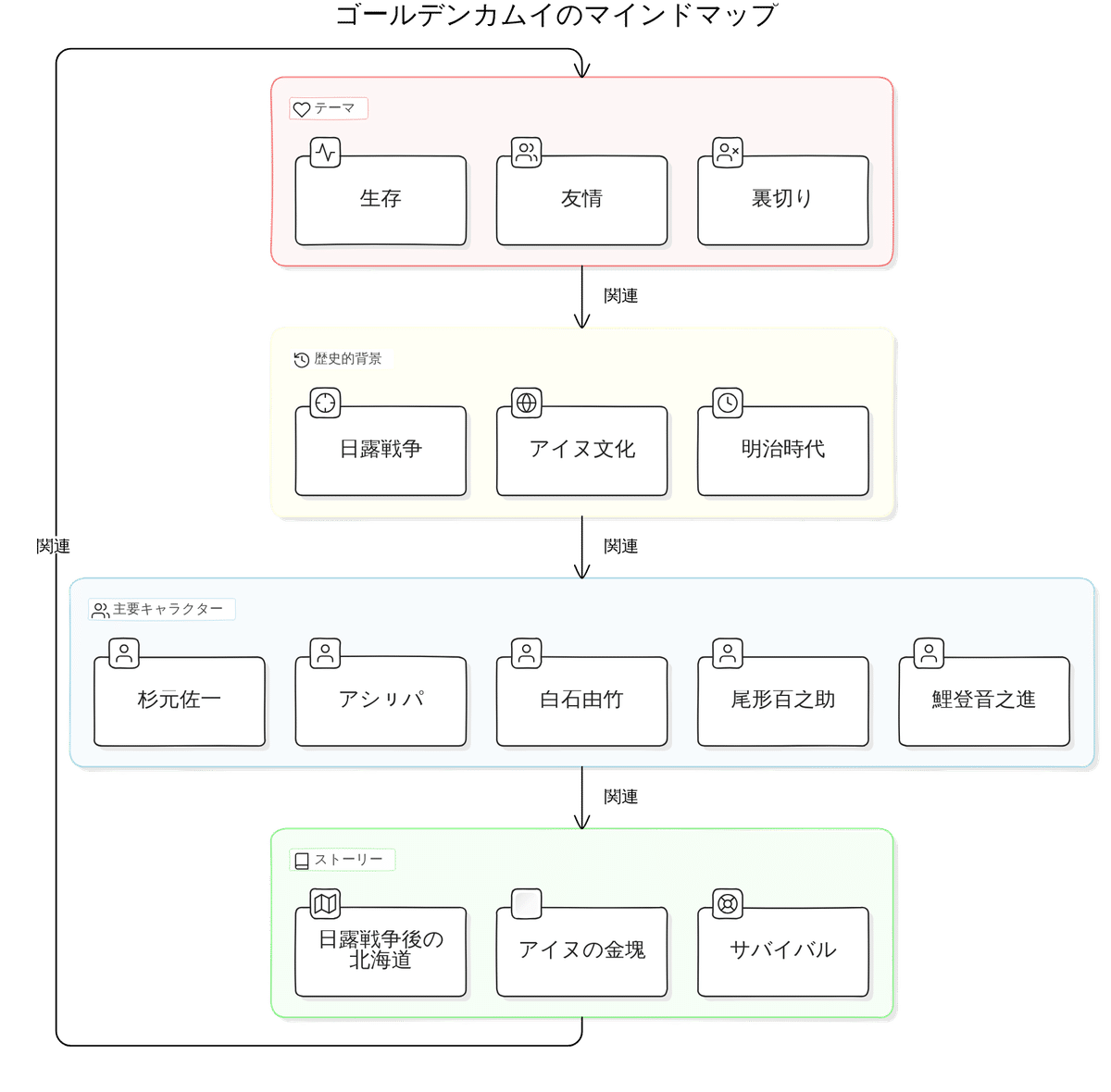
最後に、この記事のテーマではないですが、Eraser Diagramsの表現力はすごいですね😎。以下はEraser Diagramsでゴールデンカムイを描かせたものです… わかりやすい😍。(これはマインドマップじゃないけどね)
SCPアプローチ、とても勉強なりました。
事前知識なしで初期分析した後、LLMの知識も加えて統合… 前提条件を膨らませたあと、よいクエリを与え… このステップがミソなんかなぁ。
参考:具体実行例










































いいなと思ったら応援しよう!
