
符号化とマルコフ連鎖

記憶をもつ情報源発するメッセージを長さ一定の符号で符号化することを考えます。それぞれの記号が独立であるベルヌーイ試行の場合は、情報源のエントロピーが通信能率の限界を決定することを見ました:
今回は状態を2つ(αとβ)もち、各状態で異なる確率で記号a, bを発する情報源を考えます。図式化すると以下の通り。
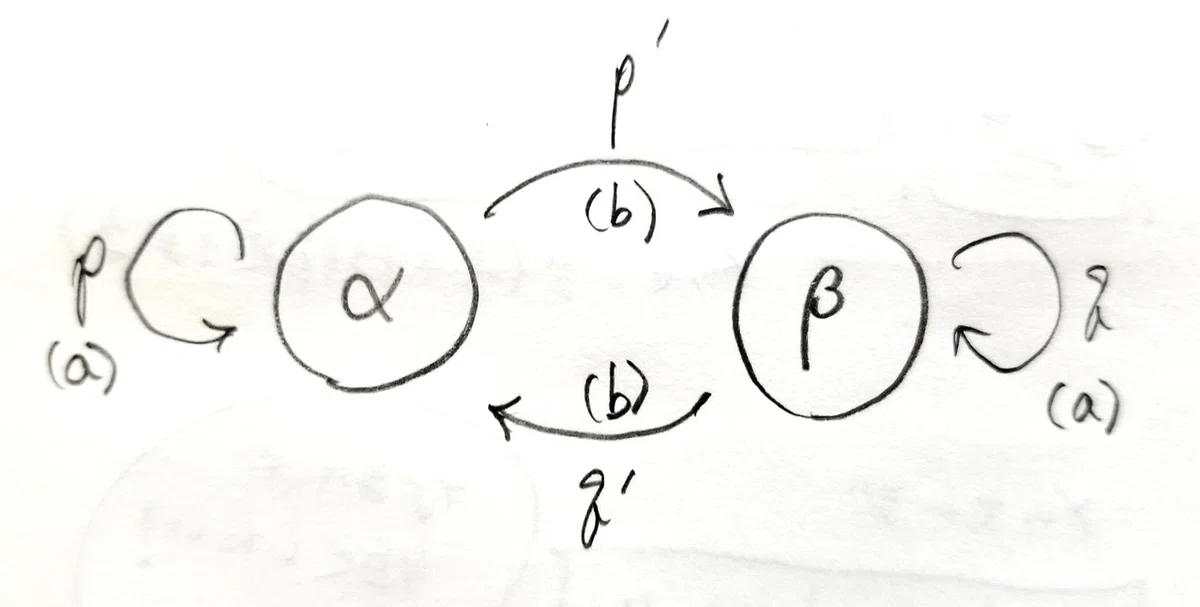
( )の中にある記号が、その遷移とともに発信される記号であると考えます。このとき情報源のメッセージを二値符号化(0と1で符号化)するとしたら、どれくらいの通信能率を達成することができるか。これがいまから考える問題設定です。
ここで今までの議論で得られた結果をまとめておきます。詳細は以下の記事で。
いまのマルコフ連鎖の場合、p, qが同時にゼロになったり、1になることはないと考えています。このときメッセージが長くなるにつれて、各状態α、βに滞在する時間の割合はそれぞれある一定値x, x'に収束するのでした。ここでもちろんx+x'=1です。これらは情報源が各状態にある確率ととらえられ、条件つきエントロピーHを、

で定義すれば、十分長いメッセージについて、p, p', q, q'に対応する遷移をそれぞれほぼxp, xp', x'q, x'q'だけの割合で含むようなメッセージがほとんど確実に起こり、その個数と生起確率はそれぞれexp(LH), exp(-LH)のように増減することが導かれました。ここでLはメッセージの長さです。
さて、ベルヌーイ試行のときと同様に、すべてのメッセージを符号化するのではなく、十分大きくLをとっておいて、典型的なメッセージが生起する確率を十分1に近づけておけば、符号化されていないメッセージが出現する事象は考慮しなくてもよくなります。すると典型的なメッセージを表現するのに必要なビット長NはほぼLH(よりも少し大きい)でしょう。そうするとこのとき通信能率、すなわち一記号あたりの符号長は

となります。
さらにこのとき、符号化システムを情報源としてみれば、各符号(0, 1)が等確率で出現するわけですから、最大エントロピー1に近づいていくことになるわけです。
つまりベルヌーイ試行のときとまったく同じ符号化定理が、マルコフ連鎖の場合でも成立するのです。ただしメッセージは十分大きく、またエントロピーを条件つきエントロピーに読み替えなければなりません。
以上の議論は固定された長さの符号化でしたが、これを可変とした場合はどうなるでしょう。直感的には出現頻度の高いメッセージ(英語ならe)を短い符号で、出現頻度の低いメッセージ(英語ならzなど)は長い符号で符号化すると効率がよさそうです。
ただし符号は復号できなければならないし、実際の符号列は途切れなく入力されるものですから、例えば10と101のような符号が同時にあってもまずい。というのも10という符号を読み取った時点では、まだ101である可能性もあるからです。こういう符号は読み取りに時間がかかって経済的ではない。ではどうしたらこれらの要件を満たす符号が構成できるのか。
この疑問に答えるのがHuffmanの提唱したハフマン符号化アルゴリズムです。次回はこの点を議論します。