
Datomic Cloud を一年半運用してきた感想

こんにちは。トレタの CTO の鄧(でん)です。今回はトレタ Advent Calendar 2022 12 月 4 日分の記事で会社の主力サービスの運用の話です。
はじめに
トレタでは O/X (Order Experience) という名で飲食店向けのモバイルオーダーエントリーシステムを提供しており、将来的には POS レジまで作る予定となっております。もちろんお客さんにとってかなり重要な業務なので、その裏側ではデータの変更履歴や監査ログを重要視して Datomic Cloud というちょっと変わったデータベースを使っております。特徴としては以前僕の記事や @t_wada さんの「SQLアンチパターン 幻の第26章」にも紹介された通り、データの上書きも削除もできない「追記型」のデータベースです。
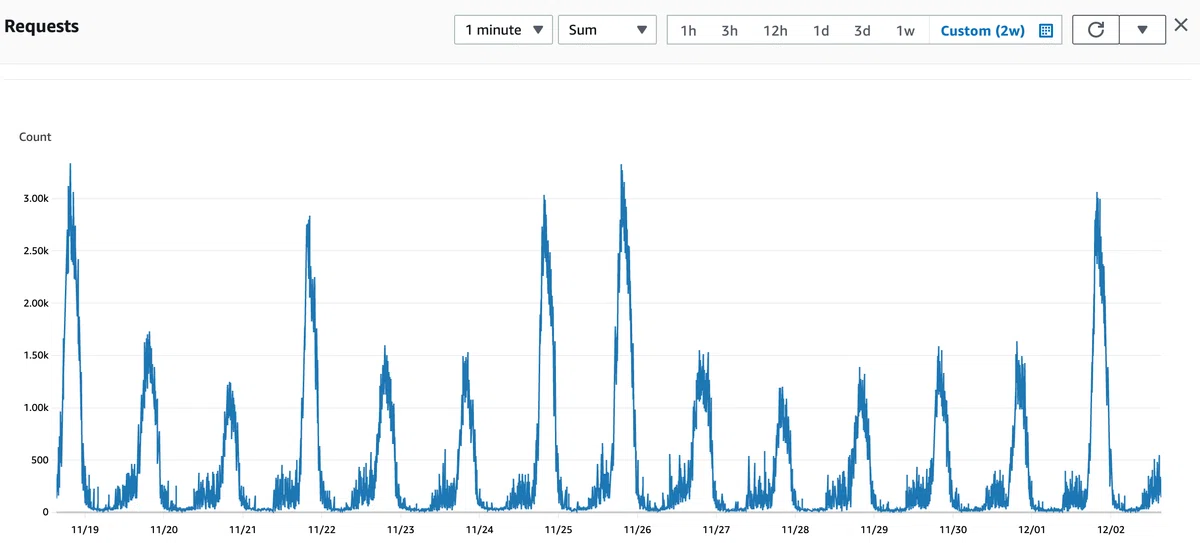
導入初期はかなり楽観的でしたが、その後販売元である Cognitect 社のサポートもあり幾つか試練を乗り越えて国内ではかなり少ない事例になったと考えております。
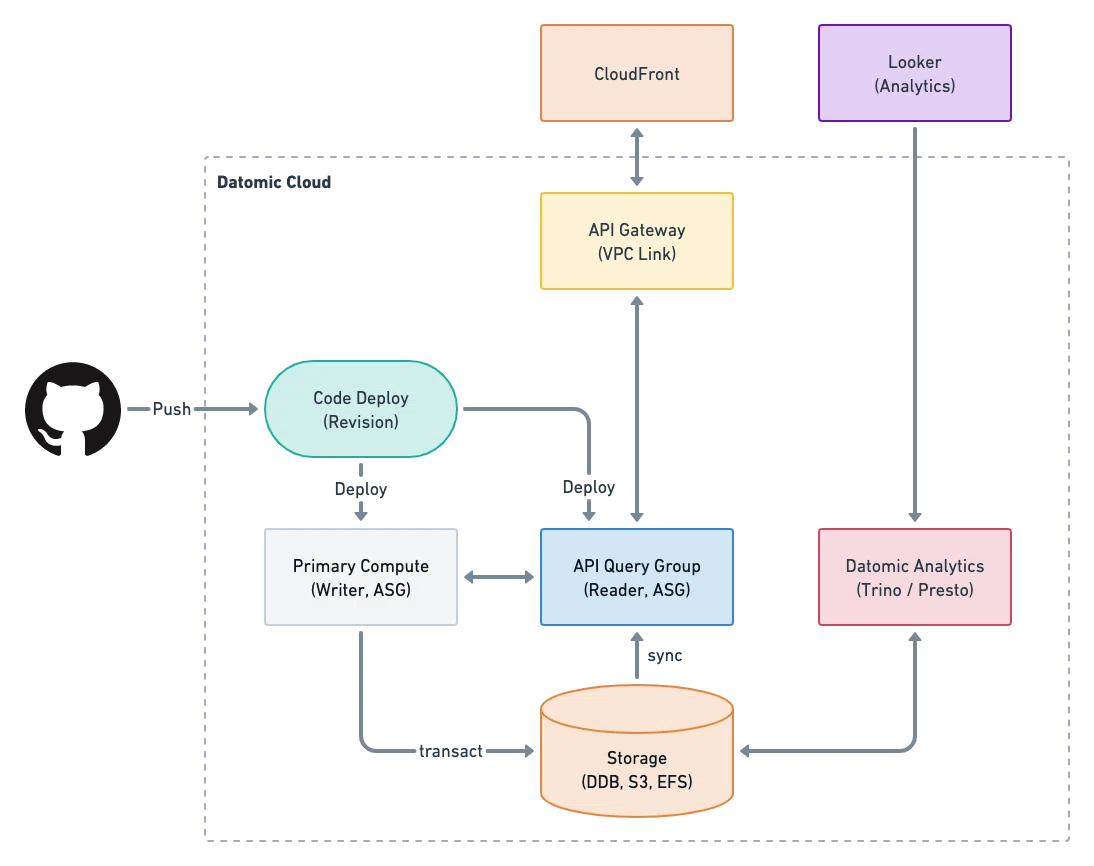
アプリケーションのアーキテクチャ的には reader (Datomic 用語では Query Group) と writer (Datomic 用語では Primary Compute) が分離しており、リクエストの量に応じて reader の horizontal scaling が可能で、用途に応じて複数の違う reader を展開することが可能です。
O/X では主に国内の飲食店むけのユースケースに合わせており、その傾向も分かりやすく土日祝日の夜に負荷のピークが来るのでそれに合わせて Auto Scaling Group (ASG) のスケジュール (Scheduled actions) を組んでおり、保険として突発的なトラフィックにも対応できるように Dynamic Scaling Policies を設定しており、お客さんから信頼できるインフラを目指しております。
ここまではトレタ独特のドメイン知識でしたが、ここ一年半運用してきて、一般的なアプリケーションにも通用するいくつかの tips を共有したいと思います。
1. 定期的に最新のバージョンにアップグレードしましょう
Datomic Cloud は年数回アプリケーションのリリースを行なっており、利用者は配布された CloudFormation のテンプレートを適応する形でアップグレードを行います。
Datomic Cloud は今でも積極的に新機能を開発しており、アプリケーションの運用上極めて当たり前のことですが、定期的に新しいバージョンにアップグレードすることによってバグ修正・セキュリティー強化・パフォーマンス改善・新機能の恩恵を得ることが出来ます。
CloudFormation の仕組み上 in-place アップグレードすることもできますが、Datomic Cloud はダウングレードを非推奨としているため万一問題が起こった際にはロールバック出来なくなってしまうリスクがあります。トレタでは安全のために Datomic Cloud が提供している API Gateway の前段に CloudFront を置く事によってアップグレード中は新旧の Query Group が共存するような形にしてます。

この一手間によって新しい Query Group を世に出す前に内部的に QA を実施できるし、リリース後も一定期間古い Query Group を残しているため何か不具合があった場合は速やかに切り戻すことが可能です。
2. Index をちゃんと使おう
どのデータベースでも Index の貼り方は重要なファクターですが、Datomic では特に重要です。
Datomic はリレーショナルですが、一般的なリレーショナルデータベース (RDBMS) と違ってテーブルの概念がありません。すべてのデータが一つの巨大な EAVT テーブルに収納されている状態をイメージするといいと思います。そのため、それぞれの項目に対してできる限りの index を張ってますが、クエリーの内容次第ではどうしてもデフォルトの index が効きづらい場合もあります。
Datomic のクエリーは Datalog というクエリー言語によって構成されておりますが、一般的なリレーショナルデータベースと違ってこの Datalog にはクエリーを書き換えて最適化をするきのう (optimizer) が存在せず、システムは書かれた順番で実行します。例えば特定の店舗の特定の時間帯に登録されたの来店情報を表示する際にこう書いてしまうと
;; Query
[:find (pull ?s [*])
:in $ ?id ?start ?end
:where
[?loc :system/id ?id]
[?s :session/location ?loc] ;; 🌶
[?s :session/created-at ?created-at]
[(>= ?created-at ?start)]
[(< ?created-at ?end)]]該当する店舗のすべての来店情報をその日に限らずすべて処理しないといけないためかなり重たいクエリーになってしまいます。ここで Datomic の標準機能である composite-index を使う事によってより精度が高い index を作ることが可能です。
;; Schema
{:db/ident :session/location+created-at
:db/valueType :db.type/tuple
:db/tupleAttrs [:session/location :session/created-at]
:db/cardinality :db.cardinality/one
:db/unique :db.unique/identity}
;; Query
[:find (pull ?s [*])
:in $ ?id ?start ?end
:where
[?loc :system/id ?id]
[(tuple ?loc ?start) ?lower-bound]
[(tuple ?loc ?end) ?upper-bound]
[?s :session/location+created-at ?index]
[(>= ?index ?lower-bound)] ;; 👍
[(< ?index ?upper-bound)]]
;; 場合によっては直接 datomic.client.api/index-range
;; 関数を使うのもいいでしょう実際トレタでは結構負荷が高かったクエリーを解析してサーバーのパフォーマンス改善をしております。結果として CPU 負荷がかなり減り、クエリーのレスポンスも改善されました。
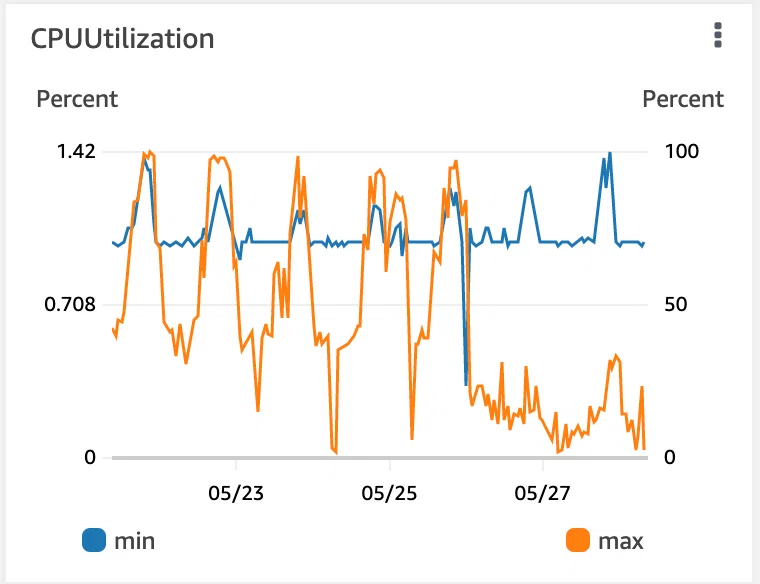
3. テストと staging 環境も忘れなく
Datomic Cloud には dev-local という開発ツールを用意しておりますその名の通りローカル環境や CI 環境で使えるものです。加えて dev-local は in-memory モードを搭載しており、必要であればテストごとに使い捨てる環境を作れるのでトレタでは重宝しております。ただし現状 (2022 年 12 月現在) dev-local と本当の ions の間では少なからず差異があり、ローカルや CI では問題なかったコードが staging に上がった途端エラーを吐くこともしばしあります。Thr 12 factor app では開発と本番一致の重要性を力説しておりますが、これはぜひ Cognitect 側の改善を期待しております (Cognitect には報告済み、Datomic Cloud の PM の方とも会話済み)。
今後の発展と展望
現状トレタでは Datomic Cloud を使って約 100 店舗分のオペレーションを 24 時間 365 日支えており、今後は店舗の要望に沿って蓄積されたデータを分析するサービスを強化しようと考えております。
Datomic では分析ように Datomic Analytics (Preview) を提供しており、トレタでも現状利用しておりますが、これまた index をうまく利用できてないのか、JOIN を複数重ねるとクエリーが重くてタイムアウトする事象が確認されております。
そこで思いついたのが Datomic Cloud の immutable な特性を利用し datomic.client.api/tx-range 関数を使って継続的にトランザクションを監視して差分を使い慣れている BigQuery に継続に同期させる俗にいう CDC (Change Data Capture) の手法を検証しており、今の所 PoC を作っております。

これがもし成功すれば間違いなく今までのデータ資産と連携してより付加価値が高く、且つユーザー体験がいいサービスを提供できると考えております。
さて、Datomic という超マイナーな技術スタックですが、運用していると意外に面白い側面があると思います。最後に、トレタでは Clojure エンジニアを採用しており、もしご興味ありましたらぜひ一緒に面白い仕組みを作っていきましょう。
詳細はこちら。
https://corp.toreta.in/recruit/midcareer/
この記事が気に入ったらサポートをしてみませんか?