
論文の所属機関情報から国名を抽出

Twitterで呟いた下記のデータ処理について詳細をまとめる。
論文の組織名が"Department ***, *** Univ., ***, ***, Israel"のように表記されることが多い。国名を抽出する時、Excelで最終カンマ後の文字列を抽出する関数を組めば良い。ただ、国名が最後にない場合もあるので手直しが必要。その際、固有表現抽出したものを参照しながら確認すると効率良くなる。
— hayataka (@hayataka88) January 13, 2023
Excel関数による抽出
論文の所属機関情報は、基本的には「部門, 組織, 住所, 国」となっていることが多い(下記表のA0001のイメージ)。エクセルで国名を抽出するには、最後のカンマの後の文字列を取得すれば良い。この関数は、「最後の空白(や指定文字)以降の文字を取り出す」というサイトを参考にした。
最後のカンマ以降を抽出するエクセル関数(E2セル)
=TRIM(MID(C2,FIND("★",SUBSTITUTE(C2,",","★",LEN(C2)-LEN(SUBSTITUTE(C2,",",""))))+1,LEN(C2)-FIND("★",SUBSTITUTE(C2,",","★",LEN(C2)-LEN(SUBSTITUTE(C2,",",""))))))

この関数で多くは正常に国名を取得できるが、A0002~A0004のように記載されているケースもある。この場合は手直しをする必要がある。そこで、固有表現抽出によって国名を抽出し、この情報を参考にしながら手直しすると効率的である。
Pythonによる固有表現抽出
Spacyライブラリを使って国名を抽出する。下記コードは、A0004の所属機関名である「Zhuji Agricultural Technology Promotion Center, Zhejiang, 311800, China,」に対して、国・地域名を抽出している。国・地域名にはGPEタグが付与される。結果、Zhejiang(浙江省)とChinaが抽出された。なお、「Spacyで文から国名を取得」を参考にした。
# A0004に対して国・地域名を抽出
import spacy
nlp = spacy.load('en_core_web_sm')
doc= nlp('Zhuji Agricultural Technology Promotion Center, Zhejiang, 311800, China,')
for ent in doc.ents:
if ent.label_ == "GPE":
print(ent.text, ent.label_)# 出力結果
Zhejiang GPE
China GPE# (参考) インストール方法
pip install spacy
python -m spacy download en_core_web_smSpacyだけでは、国と地域名を区別することができないため、geonamescacheライブラリを利用して区別する。A0004で試すと、ZhejiangはOther GPE、ChinaはCountryと判別された。なおコードは「Differentiate between countries and cities in spacy NER」を参考にした。
import spacy
import geonamescache
nlp = spacy.load('en_core_web_sm')
gc = geonamescache.GeonamesCache()
countries = gc.get_countries()
cities = gc.get_cities()
def gen_dict_extract(var, key):
if isinstance(var, dict):
for k, v in var.items():
if k == key:
yield v
if isinstance(v, (dict, list)):
yield from gen_dict_extract(v, key)
elif isinstance(var, list):
for d in var:
yield from gen_dict_extract(d, key)
cities = [*gen_dict_extract(cities, 'name')]
countries = [*gen_dict_extract(countries, 'name')]
doc= nlp('Zhuji Agricultural Technology Promotion Center, Zhejiang, 311800, China,')
for ent in doc.ents:
if ent.label_ == 'GPE':
if ent.text in countries:
print(f"Country : {ent.text}")
elif ent.text in cities:
print(f"City : {ent.text}")
else:
print(f"Other GPE : {ent.text}")# 出力結果
Other GPE : Zhejiang
Country : Chinaこの2つのコードを組み合わせて、Sampleデータに対して国名を出力する。複数国名がヒットする場合は、最後に出現したものを抽出している。

import spacy
import pandas as pd
import sys
import geonamescache
nlp = spacy.load('en_core_web_sm')
gc = geonamescache.GeonamesCache()
countries = gc.get_countries()
cities = gc.get_cities()
def gen_dict_extract(var, key):
if isinstance(var, dict):
for k, v in var.items():
if k == key:
yield v
if isinstance(v, (dict, list)):
yield from gen_dict_extract(v, key)
elif isinstance(var, list):
for d in var:
yield from gen_dict_extract(d, key)
cities = [*gen_dict_extract(cities, 'name')]
countries = [*gen_dict_extract(countries, 'name')]
df = pd.read_csv('sample_data.tsv',sep='\t',encoding='utf8')
country_li = []
i = 0
N = len(df)
for doc in df['affiliation']:
tmp = []
doc = nlp(doc)
for ent in doc.ents:
if (ent.label_ == 'GPE') and (ent.text in countries):
tmp.append(ent)
if len(tmp) != 0:
country_li.append(tmp[len(tmp)-1])
else:
country_li.append('')
i = i + 1
sys.stdout.write('\r{}/{}'.format(i, N))
df['country'] = country_li
df.to_csv('author_country.tsv',sep='\t',encoding='utf8',index=False)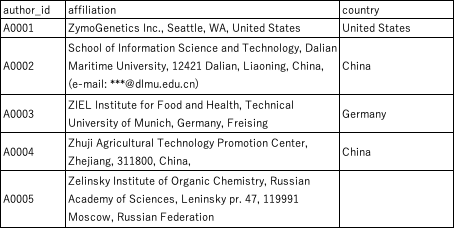
出力結果を見ると、A0005以外はうまく抽出できていることが分かる。Russian Federationについては、spacyの固有表現抽出ではうまく抽出できないようである。他にもうまく抽出できないケースがあるので、そういう物は改めて学習させればできるかもしれない。
2つの手法の結果を組み合わせて修正
最後に2つの方法で抽出した国を組み合わせた表を下記に示す。どちらも得手不得手がある。手動で修正する際は、例えば、Excel関数で取得した国名でおかしいもの(空白や国名以外の文字列)に絞り、修正候補として固有表現抽出したものを利用すると良いのではないか。もちろん、学習させて固有表現抽出の精度を上げたり、国名辞書をちゃんと用意してマッチングさせ、完全自動化を目指しても良い。

最後に
もし、やりたいデータ処理があって、方法に悩んでいる方がいれば、Twitter等でお声がけいただければと思います。可能であれば私も考えてみたいと思います。