
AWSのパフォーマンス改善について

WebサービスをAWS上で運用していて、利用者から「反応が遅い」と言われることはないでしょうか?
パフォーマンスの改善に必要なのは調査です。
今回はそんなAWSを使用する上でのパフォーマンス(レスポンスに時間がかかる)調査について弊社が取り組んでいる調査方法についてお話しします。
今回は下記の構成で徐々に利用者が増え、EC2からのレスポンス時間が長くなった場合の調査方法を書いていきます。

調査方法
1, 傾向把握
まずELBのレイテンシを確認し、どのようなパフォーマンスの状態になっているか確認します。
※ レイテンシとは、転送要求を出してから実際にデータが送られてくるまでに生じる、通信の遅延時間のこと。
レイテンシの確認は主にCloudWatchで確認できます。
今回のアーキテクチャであれば、メトリクスにあるTargetResponseTimeメトリクス(ALB)を確認します。
傾向は、規則性やどのタイミング、エラーが発生しうるレスポンスタイムかどうかを確認します。
※ Amazon CloudWatchは、AWSで実行されているサービスをリアルタイムでモニタリングできます。
2, どこが原因かを特定
傾向把握をした際に、AWSのインフラ側でパフォーマンス改善が必要だと感じた場合、パフォーマンスが悪くなっているコアの部分がどこかを特定します。
原因の特定には、クライアント側から遠い部分から調査するのが効率的です。
今回のアーキテクチャでは、RDSから確認していきます。
<RDSの確認>
RDSのレイテンシメトリクスは、クエリ種別ごとのレイテンシを確認できます。
レイテンシの値が高ければ、RDSがボトルネックとなります。
<EC2の確認>
RDSのレイテンシが正常である場合、次に、EC2のレイテンシを確認します。
CPUUtilizationメトリクス
Nginxログ、使用しているアプリケーション言語のログ(事前に仕込んでおく必要あり)
CPU使用率が100%付近に到達していた場合、EC2が原因になっている可能性があります。
その他、アプリケーションの実装や設定等も見直してみてください。
3, 原因を深掘りする
主な原因としては、下記のようなものがあります。
こちらの内容をもとに原因を絞り込んで深掘りしてみましょう。
性能が不足している
最もありがちな原因です。以下のようなものがあります。
EC2
インスタンス性能が不十分
EBS
I/Oが多いユースケースであり、Input Output Per Secondが不十分
RDS
インスタンス性能が不十分
リードレプリカの数が不十分
このような場合の解決策としては、基本的には性能をあげることで解決することが多いです。
また、キャッシュを使用して、負荷を下げることも効果的な場合もあります。
性能を出しきれていない
インスタンスの性能は十分ですが、性能を活用できていないケースです。
EC2やRDSのCPU使用率があまり高くないのにパフォーマンスが出ない場合を考えましょう。
このような場合の解決策としては、チューニングが必要です。
コーディングやOSの設定を見直してみましょう。
解決策
1. 性能をあげる
性能が不足している部分に対して、リソースを用意するという対応です。
性能をあげると言っても様々な方法がございます。
調査した内容に合わせて調整するようにしましょう。
EC2 or RDSのインスタンスタイプの性能をあげる(スケールアップ)
インスタンスタイプは、インスタンスの性質を表すインスタンスファミリーと、性質の大きさを表すインスタンスタイプがございます。
CPU/メモリ/ネットワークの性能を包括的に上げたい場合はインスタンスタイプ、いずれかのみを上げたい場合はインスタンスファミリーの変更を検討してください。
※ インスタンスタイプのサイズ比較
nano < micro < small < medium < large < xlarge < 2xlarge < 4xlarge < ...
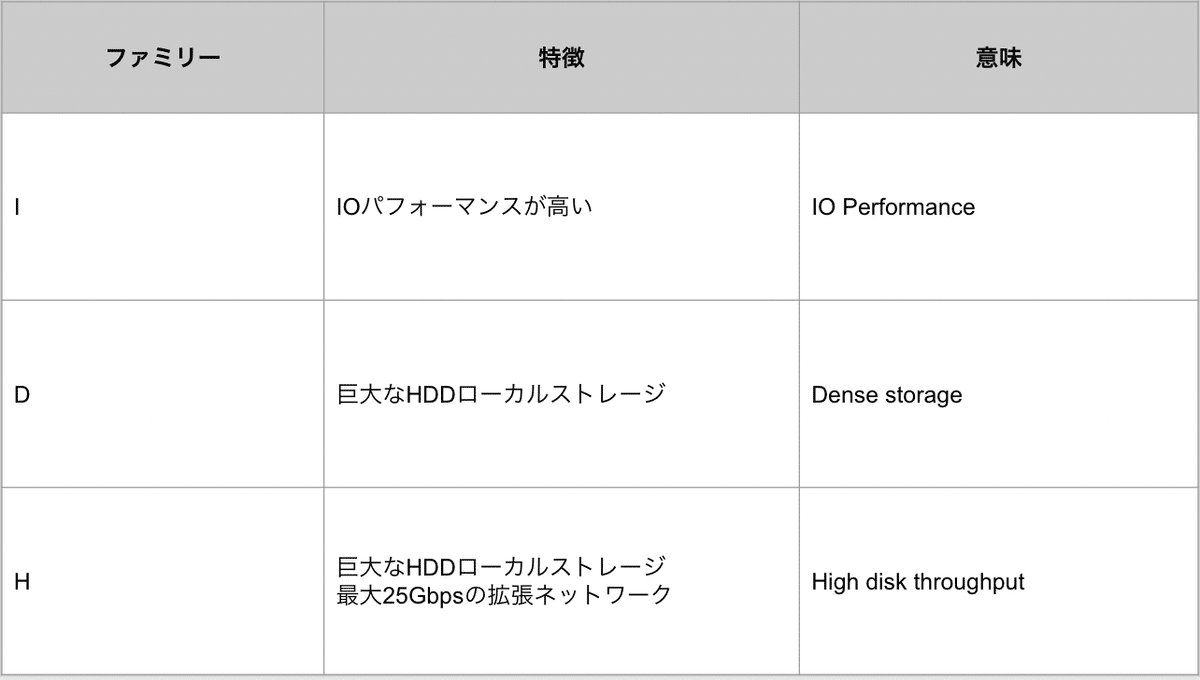
※ インスタンスファミリーの特徴と選定方法
基本的なアプリケーションサーバーの場合、「汎用」インスタンスを使用すると良いかと思います。





EC2インスタンスの台数を増やす(スケールアウト)
インスタンス台数を増やすことも、性能をあげ手段の一つです。
今回の設計ではEC2は1台ですが、性能が不足している場合は、2台、3台、4台….と増やしていきます。
Auto Scalingを使っていれば台数の調整が容易に可能です。
※ Auto Scalingとは、複数のサービス(ここではEC2)を設定したルールに則って自動で拡大・縮小できる技術
RDSのリードレプリカを増やす
RDSインスタンスに対して、Readクエリが多く、SelectLatencyメトリクスが悪くなっていると判断した場合、リードレプリカを増やすことが良いです。
Readクエリを分散することで、インスタンス1台あたりの負荷を軽減することができます。
2. キャッシュを利用する
サーバーやネットワークの性能不足に対して、キャッシュを利用するようにするのも効果的です。
ただし、同じ結果を返す取得系の処理が多いことが効果を発揮できるというのが条件となります。
特に頻繁に結果が変わるデータや、ユーザーの個人情報のようにパラメータで結果が変わってしまうデータの扱いには注意が必要です。
ELBの前にキャッシュを利用する
画像やスタイルシートといった静的データが多い場合、ELBの前にCloudFrontを設置することが効果的です。
※ CloudFrontとは、ユーザーへの静的および動的なウェブコンテンツ (.html、.css、.js、イメージファイルなど) の配信を高速化するウェブサービスです。
RDSの前にキャッシュを利用する
SELECT系のクエリの結果をキャッシュすることにより、RDSへのクエリ実行を省略する手段です。
AWSでキャッシュサーバーを利用するなら、ElastiCacheがいいです。
※ ElastiCacheは、アプリケーションとデータベースとのパフォーマンスを高速化するキャッシングする時に使ったりできます。
3. チューニングを行う
CPU使用率があまり高くないのにパフォーマンスが出ない場合、CPUが適切に使われていない可能性があります。
OS設定やアプリケーション実装などを見直し、適切なチューニングを行っていきましょう。
チューニングの方法としては以下がございます。
EC2
Webサーバーのプロセス数
アプリケーションのメモリ割り当て量
RDS
DBのインデックス
アプリケーションのクエリ最適化
参考:
・WEB+DB val113 2019年の記事
・複数の弊社プロジェクトでの実践内容