
【Python】ふるさと納税をハックする Part.1

はじめに
ふるさと納税とは
皆さん、ふるさと納税は活用されてますか?
ふるさと納税は、日本国内のふるさと納税制度に参加している任意の地方自治体へ寄付を行うことができる制度です。
手続きをすると、寄付金のうち2,000円を超える分について所得税の還付、住民税の控除が受けられます。また、寄付への返礼品として、寄付額の30%以内の価値のある地元の特産品や体験型のイベントへの招待などを受けとることができます。
つまり、ふるさと納税制度を活用すると、実質2,000円を負担することで、本来納めるだけだった税金により、返礼品を入手できるようになるのです。
「さとふる」「楽天ふるさと納税」「ふるさとチョイス」等のポータルサイトを介せば、通常のネットショップでの買い物と同じような感覚で返礼品を選ぶことができます。
唯一のハードル「確定申告」
実質2000円負担で、納税する代わりに返礼品が貰えるお得なふるさと納税ですが、唯一ハードルとなるのが確定申告です。
「確定申告なんてしたことないからやり方が分からない!」という方は一定数おられると思います。
また、確定申告の経験があっても、面倒でわざわざ手続きしたくないという方も多いのではないでしょうか。
そうした、ふるさと納税活用に際したハードルを取り払ってくれる制度が次に紹介する「ワンストップ特例制度」です。
ワンストップ特例制度
ワンストップ特例制度とは、ふるさと納税による寄付金控除の恩恵を、面倒な確定申告手続きをせずに受けることができる制度です。
ふるさと納税した自治体に対し、必要事項を記入した「寄附金税額控除に係る申告特例申請書」(ワンストップ申請書)を送付するだけで確定申告が免除されます。
最近ではワンストップ申請書すら電子化し、申請書を郵送する手間すら無くしている自治体も出てきています。
ただし、このワンストップ特例制度を活用するには「1年間のふるさと納税の寄付先が5自治体以内であること」が必要です。
確定申告を厭わないのであれば、好きなだけ色んな自治体へ寄付を行えば良いのですが、どうせだったら楽をしたいですよね。
そこで、どの5自治体を選べば満遍なく欲しい返礼品を手にいれることができるのか、事前に計画することが重要になってきます。
制度活用の課題: 自治体選びの難しさ
ふるさと納税の返礼品には、「イクラ」「カニ」「ブランド和牛」「ブランドフルーツ」など普段身銭を切って購入するには勇気が必要なものがたくさんあります。
これらの高級食材を実質負担2,000円で手に入れられるわけですから、できるだけ色んな食材を味わってみたいと思うのも、自然な流れですよね!
では試しに「楽天ふるさと納税」で「イクラ」を検索してみます。
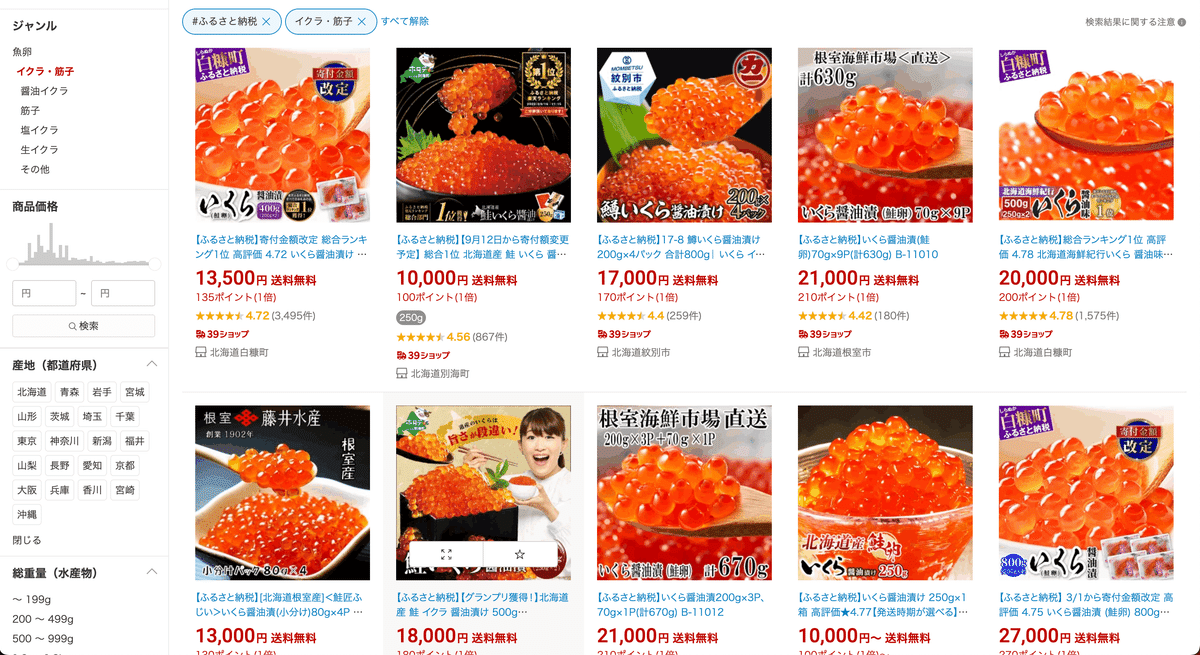
全部で968件がヒットし、北海道の白糠町、別海町、紋別市、根室市など複数の自治体が表示されています。
次に「カニ」を検索してみます。

全部で3,439件がヒットし、福井県の敦賀市、宮城県の気仙沼市、北海道の根室市などが表示されています。
どうやら北海道の根室市は「イクラ」と「カニ」の両方を手に入れることができる自治体のようです。
このようにできるだけ多くのお目当てを、5自治体から手に入れるためには、どの5自治体を選べば良いのかというのが今回考えたテーマです。
しかし、数百〜数千、時には数万件にものぼる検索結果に対し、自治体を一つずつ目視で確認しながら寄付先の組み合わせを考えるというのは非現実的です…
自治体を選ぶフロー
ただこの自治体選びの作業、工程自体はシンプルです。実際に書き出してみると次の
① 返礼品ウィッシュリストの作成
まず、返礼品に期待したいものを具体的に書き出します。
フルーツ:桃、シャインマスカット、ラフランス、デコポン、さがほのか、マンゴー
海産物:タラバガニ、イクラ、アワビ、鱧、サーモン、帆立、牡蠣など
お肉:牛肉、ジビエ(鹿・猪など)など
② ウィッシュリスト中の返礼品を用意している自治体リストを作成する
「さとふる」「楽天ふるさと納税」「ふるさとチョイス」等のポータルサイトで、ウィッシュリストに記載した返礼品を検索し、次のように各返礼品を扱っている自治体を整理した自治体リストを作成します。

③自治体リストから自治体を選ぶ
②で作成した自治体リストに基づき、どの自治体を選べば5自治体以内でウィッシュリスト中の項目を最大限カバーできるのか考えます。
自治体選びのフローを自動化する
前述のフローで面倒なのは②と③の工程です。そこで、②と③の工程をPythonでプログラミングして自動化できないか考えました。
③を自動化するためには適当なアルゴリズムを自分で考える必要がありそうですが、②に関してはPythonのスクレイピング用のライブラリBeautifulSoupを活用すれば直ぐに実装可能です。
スクレイピングによる②の自動化
スクレイピングとは、プログラムを利用してWebサイトの情報を自動で取得する技術です。PythonによるWebスクレイピングについては次の記事で詳しく説明しています。
環境構築の手間を鑑み、今回はGoogle Colabでプログラミングします。ただし、先ほど例に挙げた「楽天市場」の利用規約には
当社の事前の許可を得ることなく、自動化された手段(自動購入ツール・ロボットなどこれらに準ずる手段)を用いて商品を購入すること(商品ページ上の情報取得等を含む)
とスクレイピングを禁じる記載があります。
一方の「さとふる」ではそういった記載が見当たらなかったため、今回は「さとふる」を対象にスクレイピングを試みます。
では早速、さとふるのURLを確認してみましょう。

「さとふる」トップページのURLは次のようになっています。
https://www.satofull.jp/試しに「ラフランス」と検索してみます。
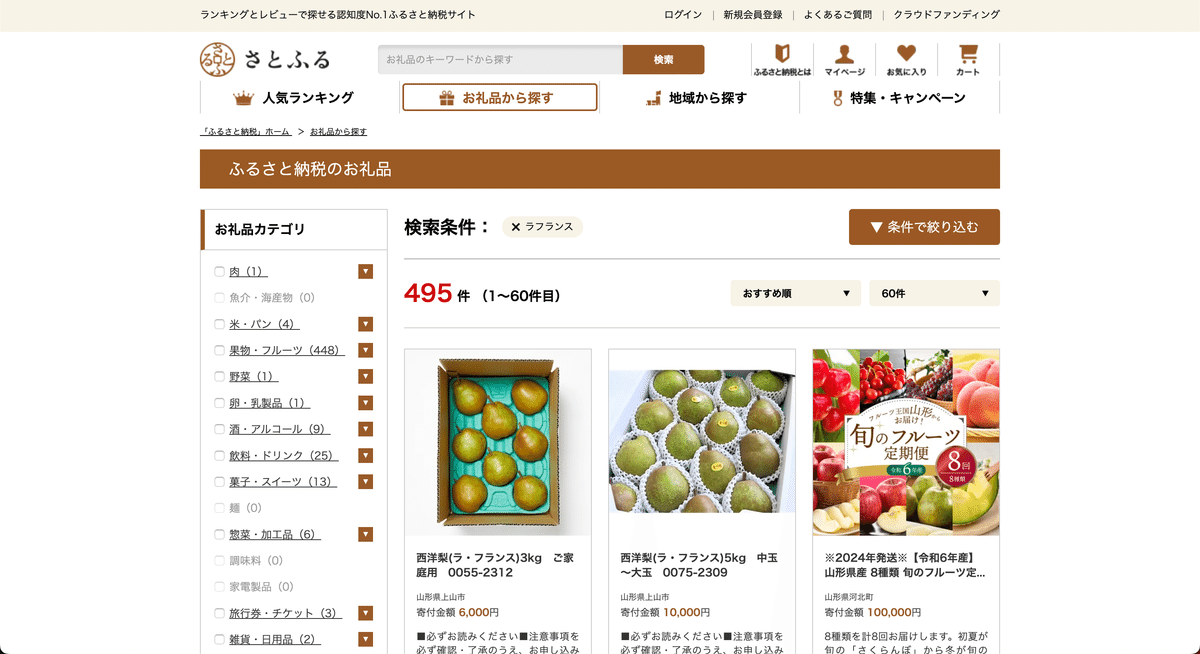
URLは次のとおり。
https://www.satofull.jp/products/list.php?q=%E3%83%A9%E3%83%95%E3%83%A9%E3%83%B3%E3%82%B9&cnt=60&p=1なる、ほど…?凄まじい文字の羅列です。では次に「いくら醤油漬け」で検索してみます。

https://www.satofull.jp/products/list.php?q=%E3%81%84%E3%81%8F%E3%82%89%E9%86%A4%E6%B2%B9%E6%BC%AC%E3%81%91&cnt=60&p=1やはり凄まじい文字の羅列ですが、「ラフランス」の場合と比較すると一定の規則性が見てとれ、どうやら「さとふる」の検索ページのURLは次の3つの要素で構成されていそうだと、推測されます。
https://www.satofull.jp/products/list.php?q=
文字の羅列(%E3%81%84%E3%81%8F%E3%82%89%E9%86%A4%E6%B2%B9%E6%BC%AC%E3%81%91など)
&cnt=60&p=1
調べたところ、この文字の羅列は検索キーワードがURLエンコードされたものだと分かりました。
本来「さとふる」の検索ページのURLは、
https://www.satofull.jp/products/list.php?q=いくらの醤油漬け&cnt=60&p=1となっているところ、一般的にブラウザは半角英数字や一部の半角記号しか扱えない為、URLに日本語が含まれる場合に日本語部分を半角英数字・記号(正確には%で始まる16進2桁)に変換して処理されているようです。
Pythonでは、このURLエンコードをrequestsライブラリのutilsモジュールのquote関数requests.utils.quoteを用いることで行うことができます。
import requests
requests.utils.quote("日本語")これを実行すると、'%E6%97%A5%E6%9C%AC%E8%AA%9E'という文字列が出力されます。
また、逆にこうした文字列を日本語に戻す変換をURLデコードと呼び、Pythonではrequests.utils.unquoteを用いることで行うことができます。
import requests
requests.utils.unquote('%E6%97%A5%E6%9C%AC%E8%AA%9E')これを実行すると、'日本語'と表示されるはずです。
これで文字列の謎が解決しました。あとは「&cnt=60&p=1」という部分について考えますが、検索結果のページを観察するとこれらは「表示件数60件の1ページ目」を表しているように推測できます。
試しに表示件数を60件から120件に変更してみます。

https://www.satofull.jp/products/list.php?q=%E3%81%84%E3%81%8F%E3%82%89%E9%86%A4%E6%B2%B9%E6%BC%AC%E3%81%91&cnt=120&p=1cntの値が60から120に変化しましたね。

今度は2ページ目に移動してみます。
https://www.satofull.jp/products/list.php?q=%E3%81%84%E3%81%8F%E3%82%89%E9%86%A4%E6%B2%B9%E6%BC%AC%E3%81%91&cnt=60&p=2やはりpの値が1から2に変化しました。
以上のことから、「さとふる」の検索結果のURLは次のような構造をとっていることが分かります。
https://www.satofull.jp/products/list.php?q={検索キーワードをURLエンコードした文字列}&cnt={1ページあたりの表示件数}&p={ページ数}
やっと「さとふる」のURLの構造が把握できたところで、次は検索結果ページから市町村を抜き出す方法を考えます。さとふるの検索結果のhtmlを覗いてみましょう。
<ul id="ItemList" class="ItemList">
<li>
<a href="/products/detail.php?product_id=1094283" class="ItemList__link">
<div class="ItemList__picture">
<img src="/upload/save_image/156/015600027/1094283_00_1644297129.jpg" alt="鱒いくら醤油漬け 600g(150g×4P入)小分けタイプ | ふるさと納税のお礼品" width="228" height="228" decoding="async">
</div>
<div class="ItemList__body">
<p class="ItemList__name">鱒いくら醤油漬け 600g(150g×4P入)小分けタイプ</p>
<p class="ItemList__city">北海道留萌市</p>
<p class="ItemList__price">
寄付金額 <span>15,000</span>円
</p>
<p class="ItemList__description2">大人気!濃厚な旨味とプチプチ食感の鱒いくら醤油漬。便利な小分けタイプでお届けします</p>
<div class="ItemList__review">
<img src="/static/master/packages/default/images/pic_star45.png" alt="" width="82" height="13" decoding="async">(635件)
</div>
<div class="ItemList__Icon">
<div class="ItemList__icon__temp--3">冷凍</div>
</div>
</div>
</a>
</li>上記は検索結果の1つ目の商品に関する情報が記載されている箇所です。「<p class="ItemList__city">北海道留萌市</p>」と記述されており、露骨に"ItemList__city"なるクラス名が付いていることが分かります。
以上の検討を踏まえ、フロー②をプログラムに落とし込んだのが次コードになります。
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 検索キーワードリスト
keywords = ["鱧", "猪肉", "ラフランス"]
# 最終結果格納用DataFrame
final_df = pd.DataFrame()
for keyword in keywords:
while True:
print(f"Processing keyword: {keyword}, page: {page}")
# URLエンコーディング
keyword_encoded = requests.utils.quote(keyword)
# HTMLを取得
url = f"https://www.satofull.jp/products/list.php?q={keyword_encoded}&cnt=120&p={page}"
response = requests.get(url, headers=headers)
html = response.text
# BeautifulSoupで解析して、itemsに自治体名を格納
soup = BeautifulSoup(html, 'html.parser')
items = soup.select('.ItemList__city')
# 自治体名をセットに追加
for item in items:
data.add(item)
# 次のページが存在するかチェック
next_page_links = soup.select('.Pager__num__link')
if not any(f"p={page + 1}" in link['href'] for link in next_page_links):
print(f"All pages processed for keyword: {keyword}")
break
# 次のページが存在する場合はページを遷移
page += 1
# データをDataFrameに変換
df = pd.DataFrame(list(data), columns=[f'{keyword}_自治体名'])
# 最終結果格納用DataFrameに追加
final_df = pd.concat([final_df, df.reset_index(drop=True)], axis=1)
# Excelファイルとして出力
final_df.to_excel("result.xlsx", index=False)自治体名を格納するオブジェクトであるdataをset型とすることで、格納される自治体名が重複しないように工夫しました。
最後は、返礼品毎に自治体名を整理してエクセルファイルとして出力することでフロー②の自治体リストを完成させています。
Part.2へ
続けてフロー③の自動化について検討していきたいところですが、記事が長くなりすぎてしまったため、本稿は一旦ここで区切ります。
次回「【Python】ふるさと納税をハックする Part.2」もよろしくお願いします!
毎度お読みいただきありがとうございます!
ご意見・ご質問などございましたらお気軽にコメント欄に投稿してください。いただいたコメントは全て拝見し真剣に回答させていただきます。