
データベース

〇データベースのモデル
データベースとは業務で扱う関連性のあるデータを管理、蓄積したものです。データベースを構築するには、リアルのデータをどのようにコンピュータ内部で表現するかを考える必要があります。これをデータのモデル化といいます。以下はモデルの一例です。
階層型:ツリー上に構成
ネットワーク型:網上に構成
リレーショナル型:表で構成
データベースの設計は次のような3層スキーマ構造というものがあります。
ちなみにスキーマとは具体的な定義のことです。
・3層スキーマ構造
外部スキーマ:ユーザからの見た目
概念スキーマ:開発者から見た構造
内部スキーマ:概念スキーマを実装しているもの
〇データベース管理システム(DBMS;Data Base Managemnt System)
データベース管理システムとは、利用者との間でデータベースの管理を効率よく行うミドルウェアです。次のような機能を持ちます。
①定義機能
データベースの作成を行う機能で、スキーマを決定します。定義はデータ定義言語(DDL;Data Definition Language)で行います。
②操作機能
データ操作言語(DML;Data Manipulation Language)で検索や抽出などの操作を行う
③管理機能
データベースは複数の利用者が同時にデータ要求を行っても、矛盾が起きないようにデータを保つ必要があります。そのために次の機能を持ちます。
・保全機能
完全性を保持する機能。
例:排他制御(誰かがDBを変更中は、他の人は変更できない)など。
・障害回復機能
障害を回復する機能。
例:ロールバック、ロールフォワードなど。
・機密保持機能
データ改ざんや不正アクセスを防止する機能。
例:ユーザ認証、アクセス制御など。
・再編成
物理的なメモリ上のデータを並び替え、アクセス性能を向上させる機能。
〇データベース設計
データベース設計では、まずはE-R(Entity - Relationship)モデルにより概念設計を行い、実態(Entity)と実態間の関連(Relationship)、さらには属性(Attribute)という概念を用いて表すE-R図を利用します。次のように矢印を用いて簡略化する場合もあります。

E-Rモデルによる概念設計をもとに、具体的なデータベースとして構築していく作業が論理設計です。
・主キー
表中の行を一意に識別するための列です。他と絶対にかぶらない必要があり、Null(ヌル:空値)を認めません。
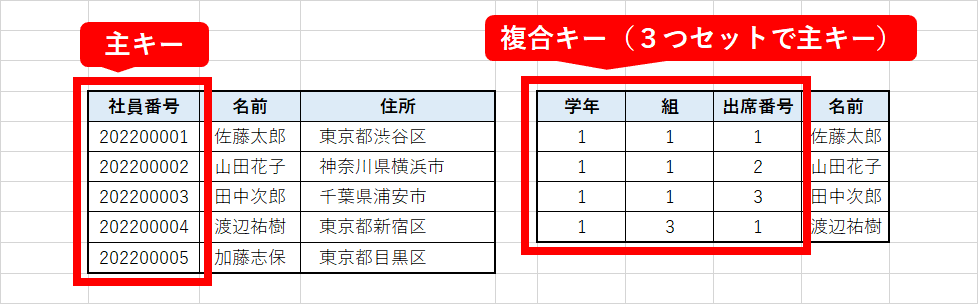
・外部キー
他の表の主キーを参照している列です。

〇正規化
データの重複や矛盾を排除し、一貫性と整合性を保つことでデータを取り扱いやすくすることを正規化といいます。一般的に第三正規化まで行います。次のデータを例として正規化を行っていきます。

・第一正規形
繰り返し部分をなくし、固定部分を補うのが第一正規化です。

・第二正規形
主キー項目に関数従属な属性を別表へまとめます。例でいうと「受注番号」の「S001」だけで「受注日」、「ユーザーID」、「ユーザー名」は決まります。これらを関数従属といいます。

・第三正規形
主キー項目以外で関数従属な属性を別表へまとめます。例でいうと「ユーザーID」と「ユーザー名」です。

これで正規化が完了しました。正規化前と後を比較するとより違いが判ると思います。

〇トランザクション
トランザクションとは、データベースに対するひとまとまりの要求単位を指します。大規模なデータベースになると多くのトランザクションが集中し、多大な負荷がかかることでエラーが発生する場合もあります。このような事態に備えてデータベースには次の4つの特性を備えていることが求められます。これをACID特性といいます。
①Atomicity(原子性):トランザクション処理は必ず「全ての処理が完了
する」か、「どの処理も行われていない」のどちらかで終了します。
②Consistency(一貫性):トランザクション後もデータベース内のデータに矛盾が生じません。
③Isolation(独立性):複数のトランザクションを「同時に実行した結果」と「順番に実行した結果」が等しいという性質です。
④Durability(耐久性):トランザクションが正常に終了したデータはデータベースの障害が発生したとしてもデータベースから消えません。
〇コミットメント制御
データベースの更新は常にトランザクション単位で管理され、取引が正常に完了した場合は更新を確定(コミット;commit)し、途中で異常終了した場合は元に戻す(ロールバック;rollback)処理が行われます。これらをその都度更新する場合、例えば「A」と「B」2つのデータベースを更新しAは正常に終了、Bは障害が発生した場合、更新内容に矛盾が起きて整合性がとれなくなってしまいます。
そこでコミットメントもロールバックもできる中間状態(セキュア状態)を設定し、全てが正常であれば更新を確定するという2段階の処理を行うことで、不整合を防ぐ方法が2相コミットメントです。

〇排他制御(同時実行制御)
例えば、映画館での座席予約システムでは、Aさんが予約処理をしている席をほかの人は予約できなくなっています。同じ座席に対して同時に予約処理を許してしまえば、予約が重複してしまうからです。このような事態が発生するのを防ぎ、データの一貫性を保つ機能が排他制御(同時実行制御)機能です。
具体的には、あるプログラムがデータ更新のためにアクセスしている間は、他のプログラムからの同一データに対するアクセスを禁止(ロック;lock)しておき、先のプログラムの処理が完了してから、ロックを解除する制御(アンロック;unlock)を行います。
ロックには、更新処理中のプログラム以外の読み書きを一切許可しない専有ロックと、複数のプログラムが同時に読むことのみ許可する共有ロックがあります。共有ロックがかかっているデータには、さらに共有ロックをかけることができますが、専有ロックをかけることはできません。専有ロックがかかっているデータには専有ロックも共有ロックもできません。
・デッドロック
お互いがアンロックを待っており、どちらも処理がストップしたまま永久に抜け出せなくなる状態をデッドロックといいます。
〇障害回復
障害からの回復(リカバリ;recovery)には以下のような方法があります。
・バックアップ
業務終了後などに全てのバックアップを別の記憶媒体にとっておき、障害が発生した際は全て復元できるようにします。
・ログファイル(ジャーナルファイル;journal file)
データベースの更新記録を保存したファイルを作成します。
・ロールフォワード
バックアップとログファイルを利用して、障害前の状態を作り出す方法です。
・ロールバック
ログファイルを利用して、トランザクション開始前の状態に戻す方法です。
〇データ操作(関係演算)
業務に必要なデータをデータベースから抽出するときの基本的な操作として、関係演算があります。以下の表をもとに説明します。

・選択
行を取り出す操作です。注文詳細テーブルから数量2以上の行を選択する場合、次のようになります。

・射影
列を取り出す操作です。ユーザーテーブルからユーザー名の列を射影する場合、次のようになります。

・結合
複数の表を、列の値の関連で結合して新しい表を作る操作です。注文テーブルとユーザーテーブルをユーザーIDで結合する場合、次のようになります。

〇SQL(Structured Query Language)
SQLは関係データベースの定義や操作を行うための最も一般的な言語です。利用するデータベースによって型が異なる場合もあるので注意してください。こちらで紹介しているのはあくまで一例です。
・DDL(Data Definition Language:データ定義言語)
データベースの作成は、DMBSに用意されたDDL(Data Definition Language:データ定義言語)を使って行います。「商品テーブル、注文詳細テーブル」を作成する場合の一例は次のようになります。
CREATE TABLE 商品テーブル(
商品ID CHAR(4) PRIMARY KEY,
商品名 VARCHAR(20),
単価 NUMERIC NOTNULL
)
CREATE TABLE 注文詳細テーブル(
受注番号 CHAR(4)
商品ID CHAR(4),
数量 INT,
商品名 VARCHAR(20),
FOREIGN KEY(商品ID) REFERENCES (商品テーブル(商品ID),
PRIMARY KEY(注文番号,商品ID)
)
CREATE TABLE 表名 (列名 データ型 …):表を作成します。その下に列名が続きます。
CHAR(),VARCHAR():どちらも文字列を指定します。()の中は最大の文字列です。
・CHAR
固定長の文字列データを扱うデータ型で、CHAR(4)と指定された列の場合、格納される列は常に4バイトになります。4バイトに満たない場合は文字列の右側に空白が追加され、4バイトぴったりに調整されます。郵便番号や社員番号など、データの桁数が決まっているもの向けです。
・VARCHAR
可変長の文字列データを扱うデータ型で、VARCHAR(4)と指定された列の場合、格納される列は4バイトに満たない場合、それに合わせた領域が確保されるのでそのままの長さで格納することが可能です。氏名や書籍名など、データ桁数が変動する可能性のあるもの向けです。
INT,NUMERIC:どちらも数値を指定します。
・INT
整数のみ格納する整数型です。-2147483648~2147483647までの数値を入力できます。
・NUMERIC
少数を格納でき、浮動小数点データ型です。最大 131,072桁の整数部と16,383桁の小数部を取り扱うことができます。
PRIMARY KEY:主キーを定義します。
FOREIGN KEY REFERENCES:FOREIGN KEYで外部キーを定義し、REFERENCESで対象の表を当てます。
NOT NULL:非NULLを定義します。空値を認めません。
他「にも「CREATE VEIW」で利用者から見た表を定義することができます。
※その他の定義は次の項目で説明します。

・DML(Data Manipulation Language:データ定義言語)
①SELECT FROM:射影
FROMで「商品テーブル」の表から、SELECTで「商品名、単価」を取り出しています。
②WHERE:選択
WHEREで条件式を定義して単価が2000未満のものを抽出しています。
③AS:列に別名つける
ASで新しい列名を定義します。「商品名」を「売り物」に、「単価」を「金額」に変えてます。
④ORDER BY:並び替え
「ORDER BY 列名 ASCまたはDESC」で並び替えをすることができます。ASCは昇順、DESCは降順です。
⑤GROUP BY:グループ化
指定した列の内容が一致する行をグループ化します。

上のSUMを集合関数といい、GROUP BYと一緒に使うことが多いです。他にも次のようなものがあります。

⑥HAVING:グループ化後の条件抽出
グループ化の結果から条件に当てはまるデータのみを抽出します。

⑦LIKE:文字列の一部分が一致する行を抽出(曖昧検索)

⑧IN,NOT IN:副問い合わせ
WHEREにSELECT文を組み込む方法です。いったん抽出した結果を条件として再度抽出します。


NOT IN は副問い合わせに含まれないデータを対象とします。

⑨EXISTS,NOT EXIST:副問い合わせ
表を1行ずつ副問い合わせに渡し、判定結果のみを受け取りながら順次処理を行う方法です。

NOTは先ほどのINの時と同じように逆を返します。
〇データベースの応用
・NoSQL
SQLを利用せずに操作するデータベース全般のことです。ビックデータやクラウドなど大容量データを扱う場合、RDBMSでは処理速度の低下が課題となります。
RDBMS:データの一貫性やSQLにより更新処理や複雑な検索処理が可能です。
NoSQL:データの整合性を犠牲に拡張性と分散処理に優れ、大容量データの高速処理が可能です。
・データの利用
企業はデータベースに大量のデータを蓄積し、様々な形で有効活用します。
データレイク:未処理の状態でリアルタイムに蓄積
データウェアハウス(DWH):整理された大量のデータ
データマート:DWHから目的別に抽出したデータベース
BI(Business Intelligence)ツール:ビッグデータ等を統計的・数学的手法で分析し新たな法則や因果関係を探す、データマイニングなどで分析をし経営判断などに利用します。

・リポジトリ
多数のデータや情報を整理して保存しておく場所です。システム開発の設計情報やプログラム情報を一元的に管理したり、論文などの学術研究結果を収集、保存、管理するのに活用します。
・データディクショナリ
情報システムが扱うデータの定義をまとめた一覧です。すべての人で共有をして、ヒューマンエラーを防ぐことが可能です。