
【業務効率化】ExcelをCloud FunctionでCSV形式に変換してBigQueryに連携する

今回は、Excelのxlsx形式のファイルをCloud Storageにアップロード後、Cloud Functionでcsv形式に変換して、Bigqueryに連携する方法をまとめていきます。
この投稿は、Google Cloudのアカウント設定はすでに完了している前提で進めていきます。
全体の流れは以下です。
①ExcelファイルをCloud Storageにアップロードする
②Cloud Functionでcsv形式に変換
③Cloud StorageからBigqueryに連携
Cloud Storageでバケットをつくる
Excelファイルをアップロードするバケットを作成する
Google CloudでCloud Storageを表示して「バケット」を選択します。

上部にある「+作成」をクリックする。

バケットに名前を付けて「続行」をクリックする

「Region」「asia-northest1(東京)」を選択して
「続行」をクリックする。
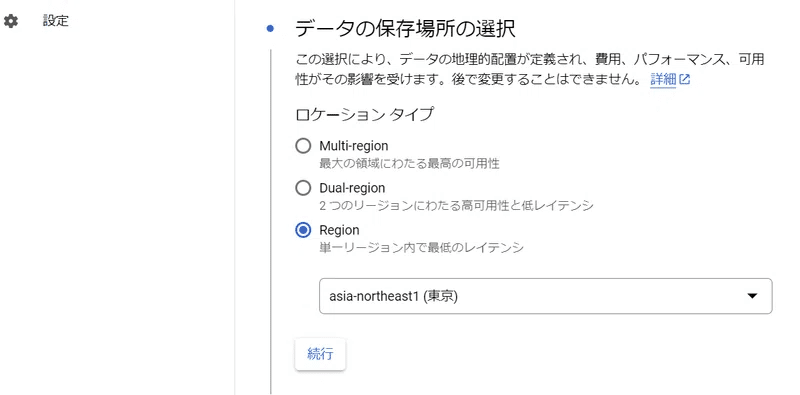
その他の項目はそのままで[続行]を選択して、最後[作成]を選択します。バケットが作成されました。

もうひとつ、CSVファイルをアップロードするバケットを作成する
上記Excel用バケットと同じ要領でもうひとつバケットを作成しておきます。
アップロードするExcelファイルの準備
Excelでxlsx形式のファイルを生成します。
ファイルをマージするため、2ファイル生成します。

Cloud Functionsで関数をデプロイする
イベントを作成する
+ファンクションを作成をクリックします

環境:第1世代
関数名:ここではcsv_test
トリガーのタイプ:Cloud Storage
バケット:ここではxslx_upload_test
「保存」して「次へ」をクリック

コードをかいていく
requirements.txtに
openpyxlとgoogle-cloud-storageライブラリを記載する
openpyxl==3.*
google-cloud-storage
次にmain.pyに以下のコードを記入して「デプロイ」をクリック
import io
import openpyxl
import re
import csv
from google.cloud import storage
def download_blob_to_buffer(blob):
"""Download a blob to an in-memory buffer."""
buffer = io.BytesIO()
blob.download_to_file(buffer)
buffer.seek(0)
return buffer
def read_excel_and_extract_data(buffer, sheet_name, start_row):
"""Read an Excel file from a buffer and extract data from a specified sheet."""
wb = openpyxl.load_workbook(buffer)
if sheet_name not in wb.sheetnames:
return []
sheet = wb[sheet_name]
max_row, max_column = sheet.max_row, sheet.max_column
data = []
for row in range(start_row, max_row + 1):
row_data = [sheet.cell(row=row, column=col).value for col in range(1, max_column + 1)]
data.append(row_data)
wb.close()
return data
def upload_csv_to_bucket(client, bucket_name, data, output_name):
"""Upload CSV data to a specified Google Cloud Storage bucket."""
bucket = client.get_bucket(bucket_name)
blob = bucket.blob(output_name)
si = io.StringIO()
writer = csv.writer(si, quoting=csv.QUOTE_ALL)
writer.writerows(data)
blob.upload_from_string(si.getvalue(), content_type='text/csv')
si.close()
def conv_csv_2(event, context):
"""Google Cloud Function to convert Excel files in a GCS bucket to a single CSV file."""
BUCKET_NAME = event['bucket']
TARGET_BUCKET_NAME = "csv_output_1"
TARGET_SHEET_NAME = "ローデータ"
OUT_NAME = 'merge.csv'
START_ROW = 2
client = storage.Client()
bucket = client.get_bucket(BUCKET_NAME)
blobs = client.list_blobs(BUCKET_NAME)
data = []
pattern = r".*\.(xlsx|xls)$"
for blob in blobs:
if re.match(pattern, blob.name, re.IGNORECASE):
buffer = download_blob_to_buffer(blob)
data.extend(read_excel_and_extract_data(buffer, TARGET_SHEET_NAME, START_ROW))
upload_csv_to_bucket(client, TARGET_BUCKET_NAME, data, OUT_NAME)
return "OK"
デプロイが終わると、緑のチェックがつきます
動作テスト
Excelファイルが、csvに変換されるかテストします。
Excelファイルをバケットにアップロードする

csvのバケット csv_output_1 に無事csv形式に変換されたファイルが格納されました。

BigQueryで外部テーブルとして登録する
次にファイルをBigqueryに連携します。
BigQuery → BigQuery Studioを選択する
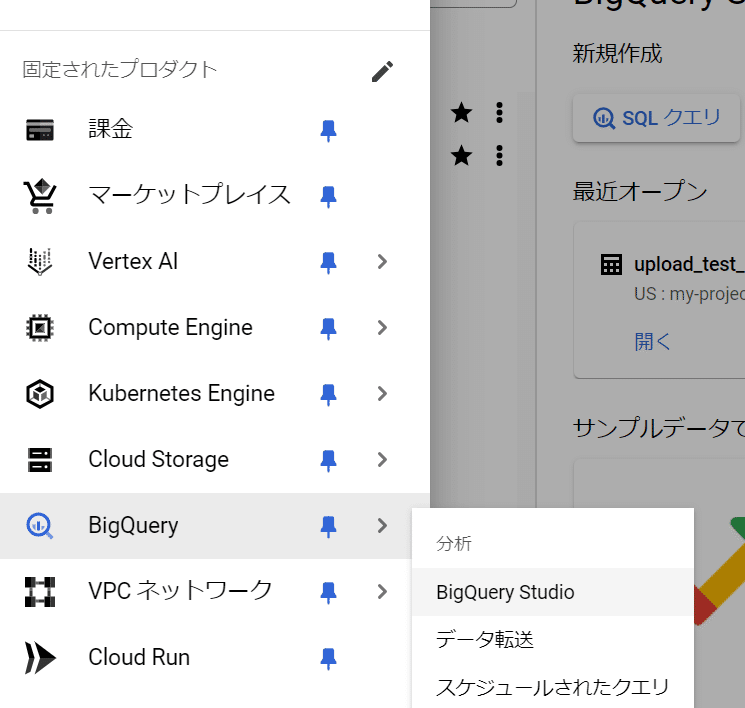
データセットを作成

データセットID
リージョンを選択
データのロケーション:asia-northeast1(東京)
「データセットを作成」をクリック

データセットにテーブルを作成する

テーブルの作成元:Google Cloud Storage
参照をクリックしてバケット csvを選択「merge.scv」を選び「選択」をクリック



テーブル名を入力
テーブルタイプ:外部テーブル
スキーマ「テキストとして編集」をクリックして

以下コードを入力します。
[
{
"mode": "NULLABLE",
"name": "ID",
"type": "INTEGER",
"description": "Identifier"
},
{
"mode": "NULLABLE",
"name": "imp",
"type": "INTEGER",
"description": "Impressions"
},
{
"mode": "NULLABLE",
"name": "CLICK",
"type": "INTEGER",
"description": "Clicks"
},
{
"mode": "NULLABLE",
"name": "CV",
"type": "INTEGER",
"description": "Conversions"
}
]
テーブルが作成されました。
クエリでデータを参照する
作成したテーブルをクリックして、クエリを選択します。

SQLを入力する
SELECT * FROM 'プロジェクトID' LIMIT 1000
データを確認することができました。
まとめ
業務でExcelファイルをBigQueryにアップロードする可能性がでてきたため、csvに変換して、BigQueryで参照できるようにしてみました。
最後まで読んでいただきありがとうございます。