
「無料でできる」"画像"が"しゃべる"を実現できる。テクノロジーを味方に!

1.はじめに
最近のAIの発展には目を見張るものが有りますね。
いまや、当然のこととなりつつあるAIのサービスですが、「D-ID」というサービスを聴いたりしたことはありますでしょうか?
「音声」をもとに「顔画像」をより自然にしゃべらすというWebサービスが大きく盛り上がってます。
ただ、無料で使えるのは初期のみで、それ以降は有料となってます。よくある「フリーミアム商品」ですね。
そうなると、ちょっと抵抗がありますよね。できれば無料で使いたい。
そう思った方にピッタリの方法を、今回ご紹介いたします。
・「SadTalker」を使う

2.SadTalkerとは?
「SadTalker」は2023年3月に発表された、オープンソース技術です。
※技術の超概要
(私は専門家では無いので、参考程度で留めてください)
・顔画像から3Dの顔画像を再構築して、表情をかたちづくるいくつかの係数と表情のポーズの数を検出する。
・次に、音声データから、頭のポーズを学習するプログラムと、顔の表情を学習するプログラムを用いて、これらの関係値がどう変化するのかを求めます。
・最後に、これらの係数をもとに、3D対応の顔のレンダリング画像で合成された動画フレームを生成します。

3.操作手順
・オープンソースのコードはGithubにあります。
・動かす場所は、Google Colabで行います。
※Google Colab無しでもOKな方は、ご自身の環境で行ってください。
・手順
※コードを上から順番に実行していく。
セットアップ(setup(about 5 minutes))
モデルのダウンロード(download model(about 1 minute))
顔画像と音声を指定する(ご自身で準備したもの)
顔の推測(inference for face)を行う
動画を再生(play movie)して確認する

1.セットアップ(setup(about 5 minutes))
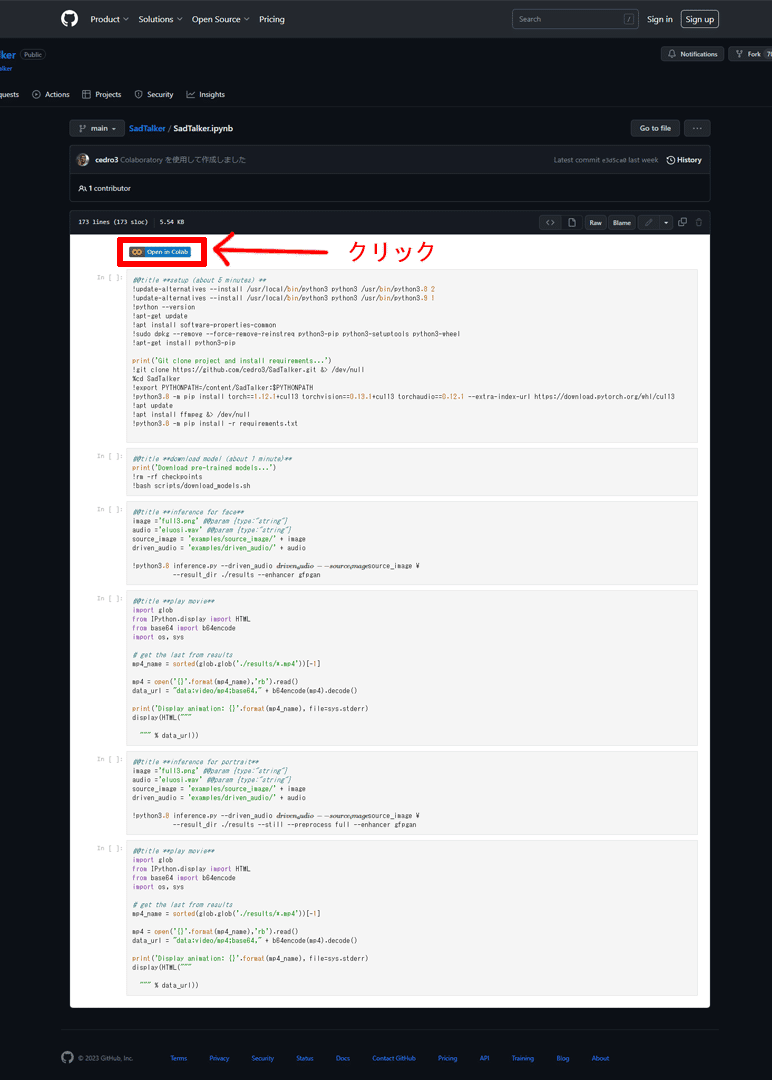
GithubのSadTalkerのページへ行きます。
表示されたノートブックの先頭にある「Open in Colab」ボタンをクリックし、GoogleColabで起動します。
※コードを上から順番に実行していく。
setup(about 5 minutes)
「▶ボタン」を押して、セルを実行する

#@title **setup(about 5 minutes)**
!update-alternatives --install /usr/local/bin/python3 python3 /usr/bin/python3.8 2
!update-alternatives --install /usr/local/bin/python3 python3 /usr/bin/python3.9 1
!python --version
!apt-get update
!apt install software-properties-common
!sudo dpkg --remove --force-remove-reinstreq python3-pip python3-setuptools python3-wheel
!apt-get install python3-pip
print('Git clone project and install requirements...')
!git clone https://github.com/cedro3/SadTalker.git &> /dev/null
%cd SadTalker
!export PYTHONPATH=/content/SadTalker:$PYTHONPATH
!python3.8 -m pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
!apt update
!apt install ffmpeg &> /dev/null
!python3.8 -m pip install -r requirements.txt2.モデルのダウンロード(download model(about 1 minute))
download model(about 1 minute)
「▶ボタン」を押して、セルを実行する

#@title **download model(about 1 minute)**
print('Download pre-trained models...')
!rm -rf checkpoints
!bash scripts/download_models.sh3.顔画像と音声を指定する(ご自身で準備したもの)
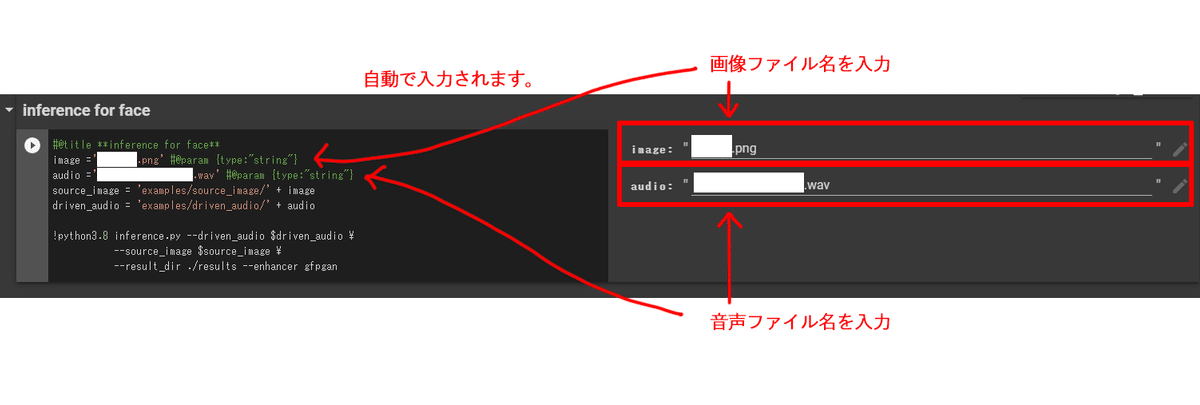
音声、画像ファイルの保存先に、ご自身で準備したファイルをアップロードします。
アップロードしたファイル名を、それぞれ入力すると、コードの方へも自動的に反映される。
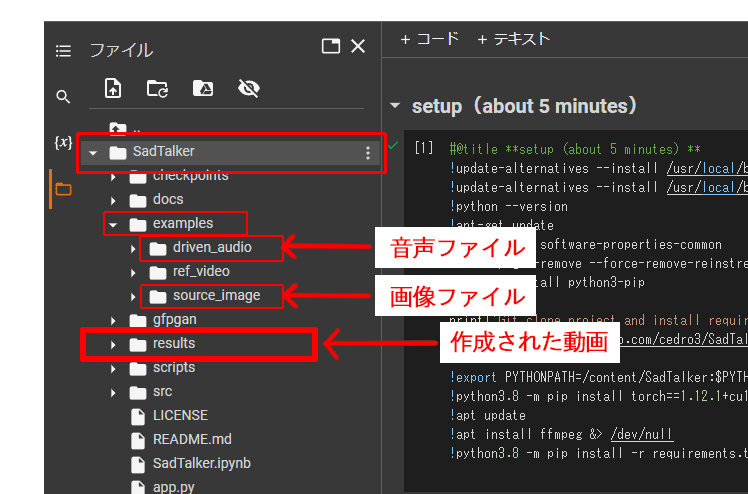
※ファイル構成について
setupを実行すると、「SadTalker」というフォルダが作成されます。
その中に、音声、画像、動画のファイルの保存先があります。
4.顔の推測(inference for face)を行う
inference for face
「▶ボタン」を押して、セルを実行する

#@title **inference for face**
image ='XXXXXX.png' #@param {type:"string"}
audio ='YYYYYY.wav' #@param {type:"string"}
source_image = 'examples/source_image/' + image
driven_audio = 'examples/driven_audio/' + audio
!python3.8 inference.py --driven_audio $driven_audio \
--source_image $source_image \
--result_dir ./results --enhancer gfpgan※'XXXXXX.png'、'YYYYYY.wav'には、それぞれご自身がアップロードして、指定したファイル名が入ります。
5.動画を再生(play movie)して確認する
play movie
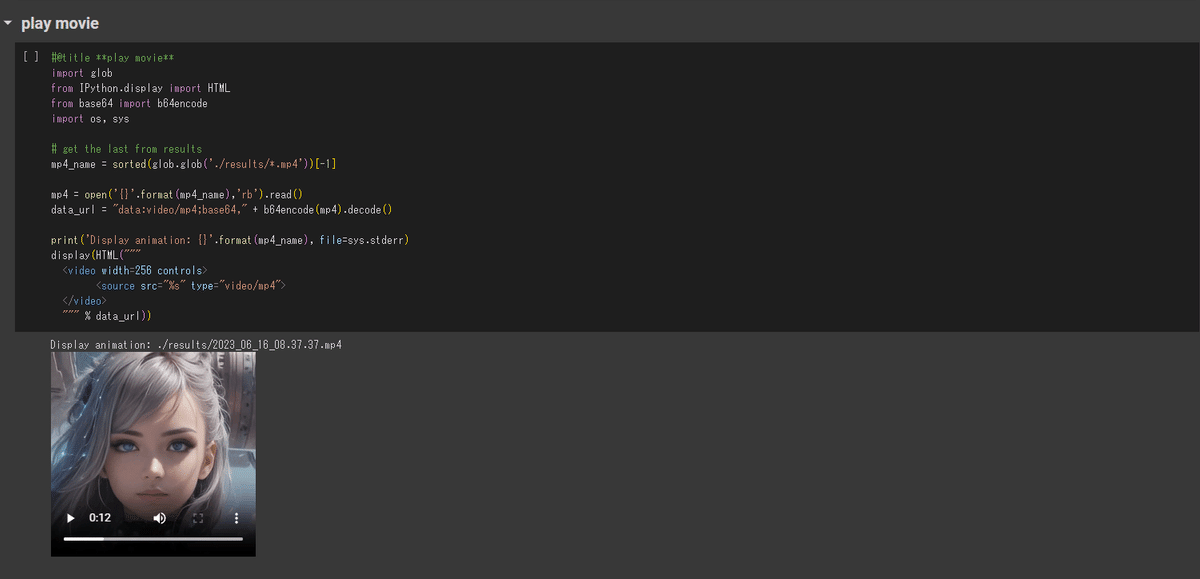
「▶ボタン」を押して、セルを実行する
完成した動画が表示されます。
#@title **play movie**
import glob
from IPython.display import HTML
from base64 import b64encode
import os, sys
# get the last from results
mp4_name = sorted(glob.glob('./results/*.mp4'))[-1]
mp4 = open('{}'.format(mp4_name),'rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
print('Display animation: {}'.format(mp4_name), file=sys.stderr)
display(HTML("""
<video width=256 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url))<video width=256 controls>
の”256”の部分の値で、動画の横幅のサイズを指定できます。
▶完成動画(参考)

・参考の完成動画です。
・音声ファイル内に「無音」の個所がある場合は、動きが少しぎこちなくなるように思います。
・画像は生成AIげ作成したものですが、人物の顔なら、写真でもOKです。
・背景は無地で頭の周囲は、何も無い方が上手くいくかと思います。
<追加/補足内容>
inference for portrait
ポートレイトのような画像の場合は、こちらを選択して実行してください。
こちらも機能は同じですが、inference for faceよりかは、表情の動きが小さくなるように思います。
必要に応じて、使い分けてください。
基本の使用方法は同じです。
※動画が再生されない場合など
データが大きくてなのか?最後のセル実行で、動画が再生されない場合があります。その場合は、resultフォルダ内に保存されていますので、直接ダウンロードしてください。
※ご相談やご不明点などは、以下よりご連絡をお願いします。
連絡先 メール:info@ginnesh-pm.com
最後に
ここまで、お読みくださりありがとうございます。
これらの情報は、あくまで執筆時点での情報などを基に書いております。
活用しているサービスやツール、アプリが今後、仕様変更などを行った場合、同様の動きをしないことも十分に予測されます。
また、サービス提供者による変更などで、現時点では無料(もしくは安価)なサービスも、有料(高価)になる場合もございます。
これらの点を踏まえた上で、ご利用していただければと思います。
最近は特に、AI技術の発達が活発となってきており、これからは、テクノロジーの分野の発展が、今まで以上にかなり面白くなってくると思われます。今後もそういった記事を書いていければと考えておりますので、良かったらまた見てください。
それでは、テクノロジーがみなさんの希望となりますように。
#プログラミング #コピペ #ツール #ノーコード #ローコード #自動化 #プログラミング初心者 #テクノロジー #IT #IOT #AI #technology #SadTalker #GoogleColab #wab #画像生成AI #音声AI #AI自動合成 #AI音声合成