
Amazon Rekognition カスタムラベル完全に理解した(と思ってる):環境構築編

いまだに余計なものは体に吸収するのに、新しいことは頭に吸収しにくくなってきた「ぎだじゅん」です。
ライフイズテックという会社でサービス開発部 インフラ/SREグループに所属しています。
年齢的にかなりのおじさんなのですが、それでもまだ伸びしろは十分にあると(自分は)信じているので、時間があればクラウドサービスのミートアップなどに参加したりしています。
ただ、参加といっても、基本は観覧オンリー。
自分も20年前に一度だけ登壇したことがありますが、今のようなコミュニティのイベントではなくビジネスイベントでの登壇で、そのときの質疑応答での失敗のトラウマがあって、それ以来、大勢の前で仕事に関することを話すのが少々苦手です。

それでも、最近のクラウドベンダーなどのコミュニティイベントの登壇者の方が自己紹介で、「自分の好きなサービスは~」みたいな紹介には憧れがあります。
そんな私の好きなAWSサービスは「AWS クーポンコード」です。
本題です。
■イントロダクション
ライフイズテックでは、中学校や高校などに提供しているデジタル学習教材「ライフイズテック レッスン」の中で、画像分析の機能を使ってパン屋さんなどのAIレジの集計部分がどのようにできているかを学習するレッスンがあります。
このような画面でパンの画像をアップすると、パンの種類を判定し合計金額を集計するようなものを、実際のコードに触れながら学習できます。
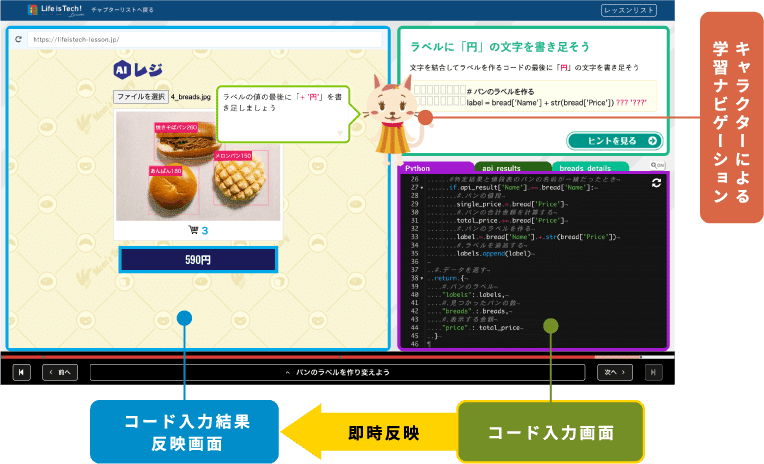
この画像からパンの種類を判別する裏側の機能ではAmazon Rekognition のカスタムラベル を使用して、パン屋さんのパン画像で画像識別するための「学習モデル」によって、APIに画像分析をリクエストして判定した結果(パンの種類)を返すようになっています。
このAmazon Rekognition カスタムラベルによる「学習モデル」は、あらかじめ弊社で用意されたものを使用するため、実際に「ライフイズテック レッスン」で学習する生徒の皆さんでパンの画像判別させるための「学習モデル」のトレーニングを行う必要がありません。
今回、このAmazon Rekognition カスタムラベルの環境を、改めて東京リージョンで作成する機会がありました。
せっかくなのでこの裏側のAmazon Rekognition カスタムラベル側での画像判別の学習モデルの構築方法を今回(環境構築編)と次回(モデルの評価編)の二本立てで紹介したいと思います。
内容がAWSの専門的なものが多く占めてしまったので解りにくい内容になってしまったかもしれませんが、この二本立てで「ライフイズテック レッスン」を使っている中高生の皆さんにも、少しでも画像判別している裏側の仕組みを知っていただけるよう、この投稿を見たみなさんの「いいね」やシェアを通して届くことを願っています!
(もちろんAmazon Rekognition カスタムラベルを初めて使おうと思っている方にも届け!!)

「ライフイズテック レッスン」は楽しく勉強できるよ!!
■Amazon Rekognition カスタムラベルとは
Amazon Rekognition は AWS が提供する画像認識とビデオ分析のサービスで、環境用のサーバや機械学習 (ML) モデルをゼロから構築する必要なく、用意されたAPIに画像や動画を送るだけで分析してくれます。

前述のとおりRekognitionではすでに数千万の画像を用いてトレーニング済みの学習モデルがあるので、利用者はRekognitionのAPIに対して画像を送るだけで、Rekognitionで用意されているラベル(例として車や人物や建物など)の判別ができますが、Amazon Rekognition カスタムラベルでは、企業などのニーズに固有するコンセプトやシーン、オブジェクトを画像から特定するためのトレーニングすることで、カスタムの画像分析の学習モデルを作成し、カスタムしたラベル(例えば自社商品の種類など)に判別することができます。
Amazon Rekognition カスタムラベルで、御社の手間のかかる仕事を当社がお引き受けいたします。Rekognition カスタムラベルは、多くのカテゴリにわたる数千万の画像を用いてトレーニング済みである Rekognition の既存の機能を基に構築されています。数千の画像ではなく、ユースケースに合わせた少量のトレーニング画像セット (通常は数百枚以下) を、使いやすいコンソールにアップロードするだけです。
提供されるコンソールに画像をアップロードしてラベルを紐づけて学習させるだけで、固有の条件にあったラベル判定ができるようになります。

簡単そうに書いてあるけど、初めて利用する機能なので不安・・・。
そんな方には、AWSが提供するチュートリアルビデオとサンプルプロジェクトなどがAWSコンソール上で用意されているので、まずは以下を参考にして試してみるとよいと思います。
Amazon Rekognition カスタムラベルでの学習モデルの作り方
Amazon Rekognition カスタムラベルでは、「プロジェクト」の中に「データセット」を作成してトレーニングに使用する画像をアップロードし、画像の中の「オブジェクト」に「ラベル」割り当ててトレーニングを行うことで学習した「モデル」が作成されます。
って単語だけではわかりにくいので、構成イメージをまとめてみました。
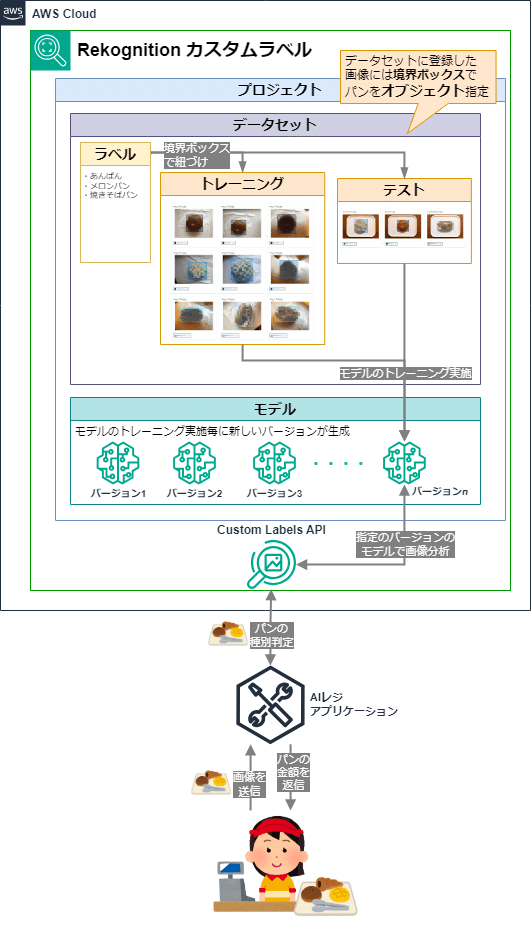
「プロジェクト」とは、判別するためのデータをセットしてトレーニングしたモデルを管理する単位
プロジェクトの中でデータセットの画像とラベルやモデルのモデルバージョンを管理します。
「データセット」とは、モデルをトレーニングするために使用される画像とラベルがセットされています。
データセットにはトレーニングデータセットとテストデータセットがあります。トレーニングデータセット
実際に画像を識別するために画像を登録して識別のラベリングを設定するトレーニング用の画像群テストデータセット
トレーニングされたモデルが正しいラベルをどの程度正確に予測するかを検証するためのテスト用の画像群
「オブジェクト」とは、画像の中に写っている分析対象となる「モノ」の単位を指します。
トレーニング時に画像上で境界ボックス(バウンディングボックス)と呼ばれる四角い枠で囲むことでトレーニング対象の「オブジェクト」として指定されます。
「ラベル」とは、画像認識で識別する情報(種類など)を示します
例えば、動物の種類を識別する場合、「オブジェクト」に指定する「ラベル」は「猫」や「犬」、「馬」などになります。「モデル」とは、ビジネスに固有のオブジェクトを見つけるためにトレーニングした学習モデル。
「プロジェクト」には、モデルの複数のバージョンを含めることができます。
今回、このRekognition カスタムラベルの環境を以下の手順でセットアップしました。
<設定①:カスタムラベル環境の初期セットアップ>
Amazon Rekognition カスタムラベルの利用開始
プロジェクトの作成
データセットの作成
<設定②:トレーニング画像の準備>
トレーニング画像の準備
<設定③:ラベルの紐づけとトレーニングの実施>
トレーニングデータセットのセットアップ
ローカルコンピュータからの画像のアップロード
ラベルの作成
画像にラベルを紐づける
テストデータセットのセットアップ
ローカルコンピュータからの画像のアップロード
ラベルの作成
画像にラベルを紐づける
トレーニングの実施(モデルのトレーニング)
この工程ごとに作業内容を説明していきます。
■カスタムラベルの設定①
(カスタムラベル環境の初期セットアップ)
まずはAmazon Rekognition カスタムラベルを利用開始し、学習モデル用のプロジェクトとトレーニング画像を管理するデータセットを作成します。
1.Amazon Rekognition カスタムラベルの利用開始
Amazon Rekognition カスタムラベルを利用開始するには、AWS Management ConsoleのAmazon Rekognition カスタムラベルのコンソール画面にある「ご利用開始にあたって」ボタンから開始します。
利用する前にコンソールの右上に表示されているリージョンが、今回作成したいリージョンを選択されているか確認ください。
カスタムラベルを作成するために必要なIAMポリシーなどは公式ドキュメントを参考にしてください。
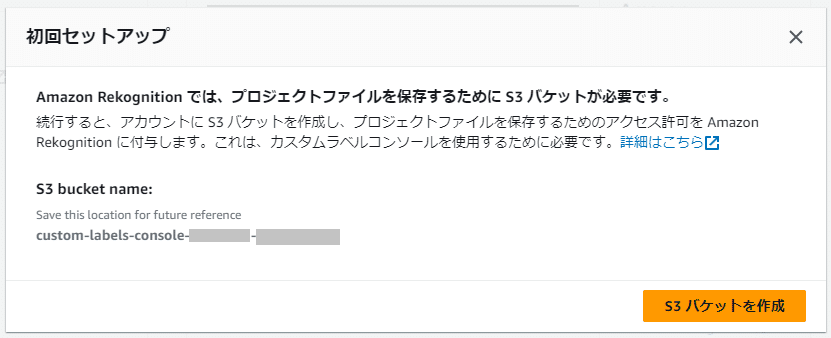
選択しているリージョンで初めてカスタムラベルを使用する場合は「初回セットアップ」として、作成するプロジェクトの関連ファイルが保管されるS3バケットが「custom-labels-console-<region>-<random value>」の形式の名称で自動で作成されます。
(任意の名称でのS3バケットを作成はできないようです)
このS3バケットの中には、カスタムラベルで作成したプロジェクトを構成するファイルやトレーニングでアップロードした画像などが保管されます。
以下がカスタムラベルの画面になります。
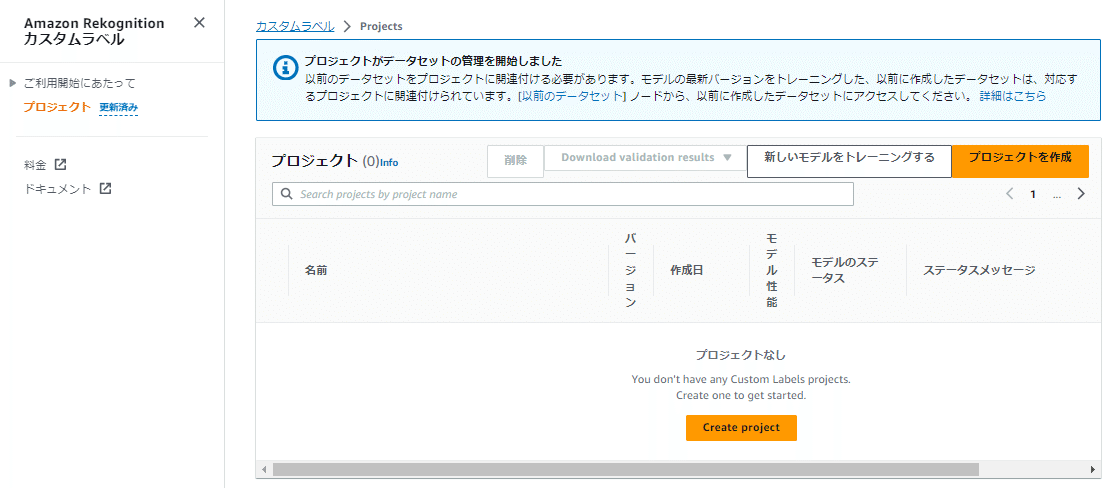
2.プロジェクトの作成
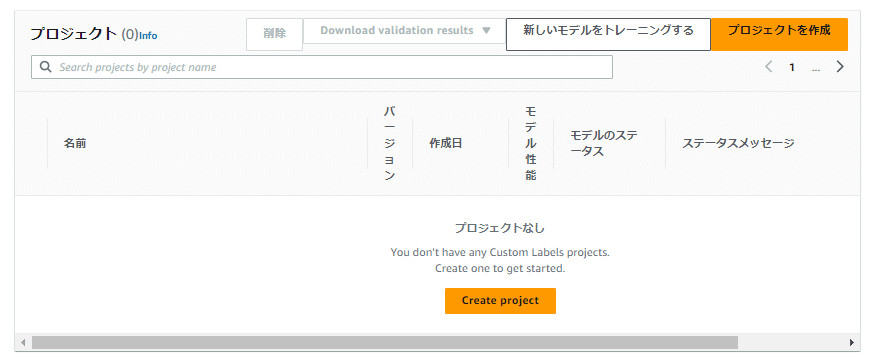
最初に「プロジェクト」を作成します。
右上の「プロジェクトを作成」または「Create project」ボタンから作成を行います。
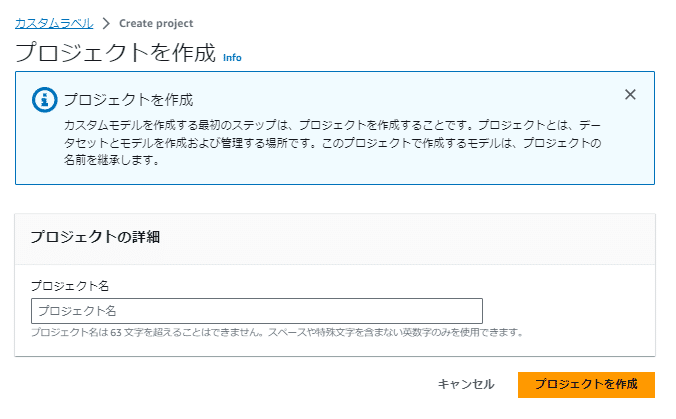
プロジェクトが作成されると、プロジェクトの設定画面が開きます。
(今回の例では「verification001」としました)
各プロジェクトの設定画面は、左メニューの「プロジェクト」画面の一覧からも遷移できます。
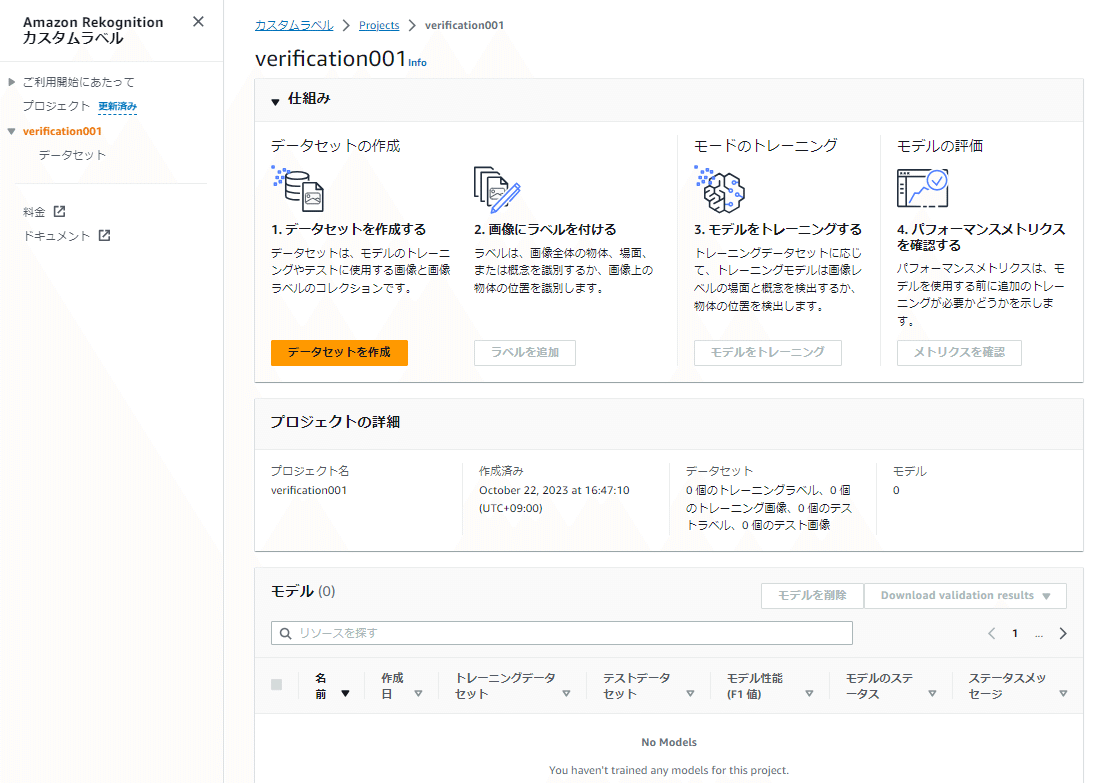
これで今回のプロジェクト用の環境の器となるものが準備できました。
次はこのプロジェクトでトレーニングするためのデータセットを作成します。
3.データセットの作成
データセットの作成は、プロジェクト作成後に表示した「プロジェクト」画面の「▼仕組み」にある「データセットを作成」、または左メニューの該当プロジェクトのデータセットから「データセット」画面にある「データセットを作成」より作成します。
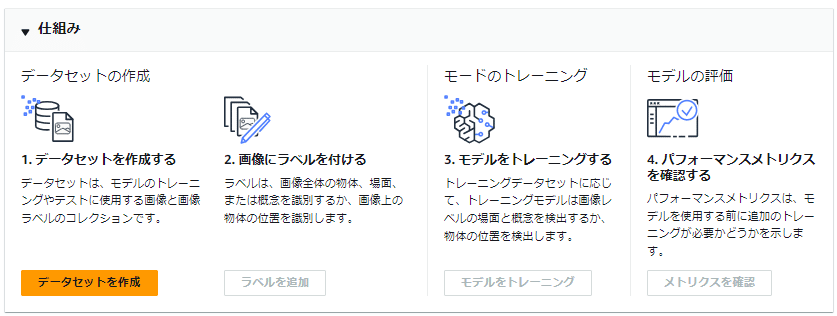
「データセットを作成」画面では以下を選択します
設定オプションは「トレーニングデータセットとテストデータセットを使用して開始」を選択
今回はローカルPC環境にある画像を後ほどアップロードしていくので、それぞれ以下を選択
トレーニングデータセットの詳細では「コンピュータから画像をアップロード」を選択
テストデータセットの詳細でも「コンピュータから画像をアップロード」を選択

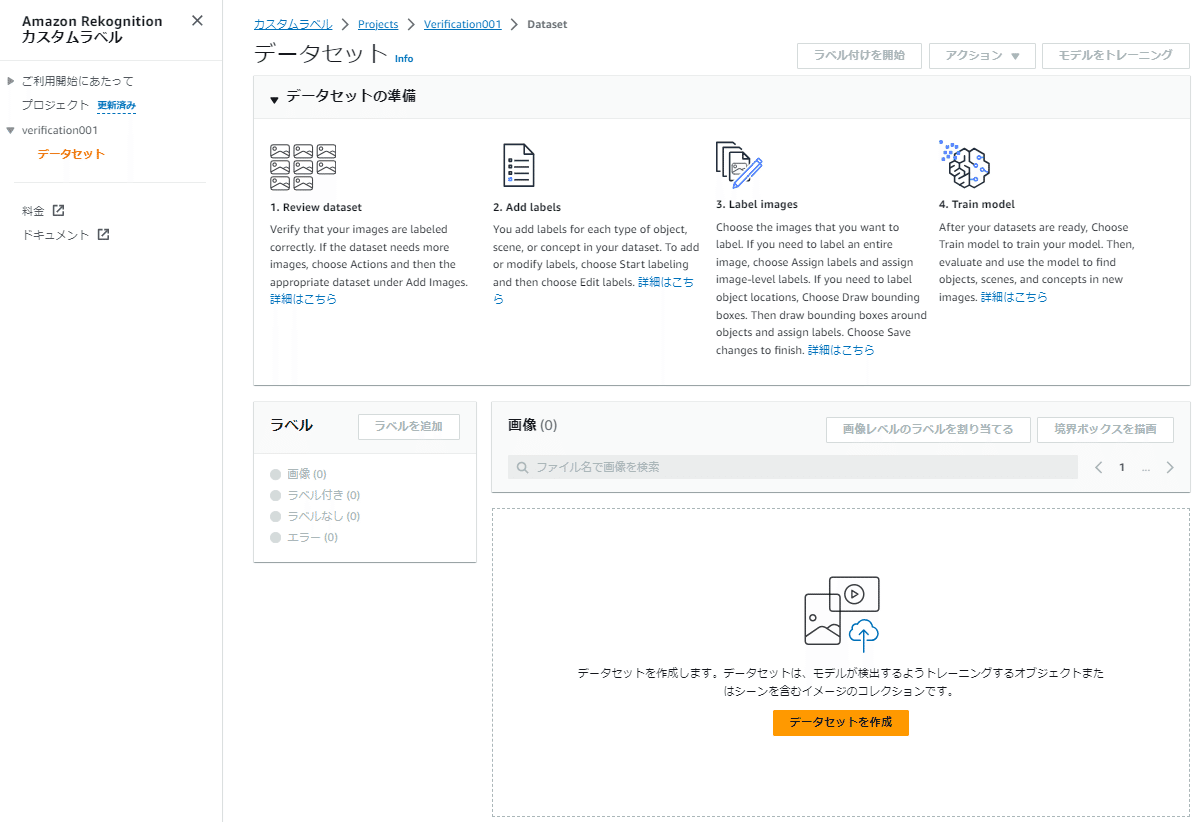
データセットを作成すると、データセットの設定画面が表示されます。
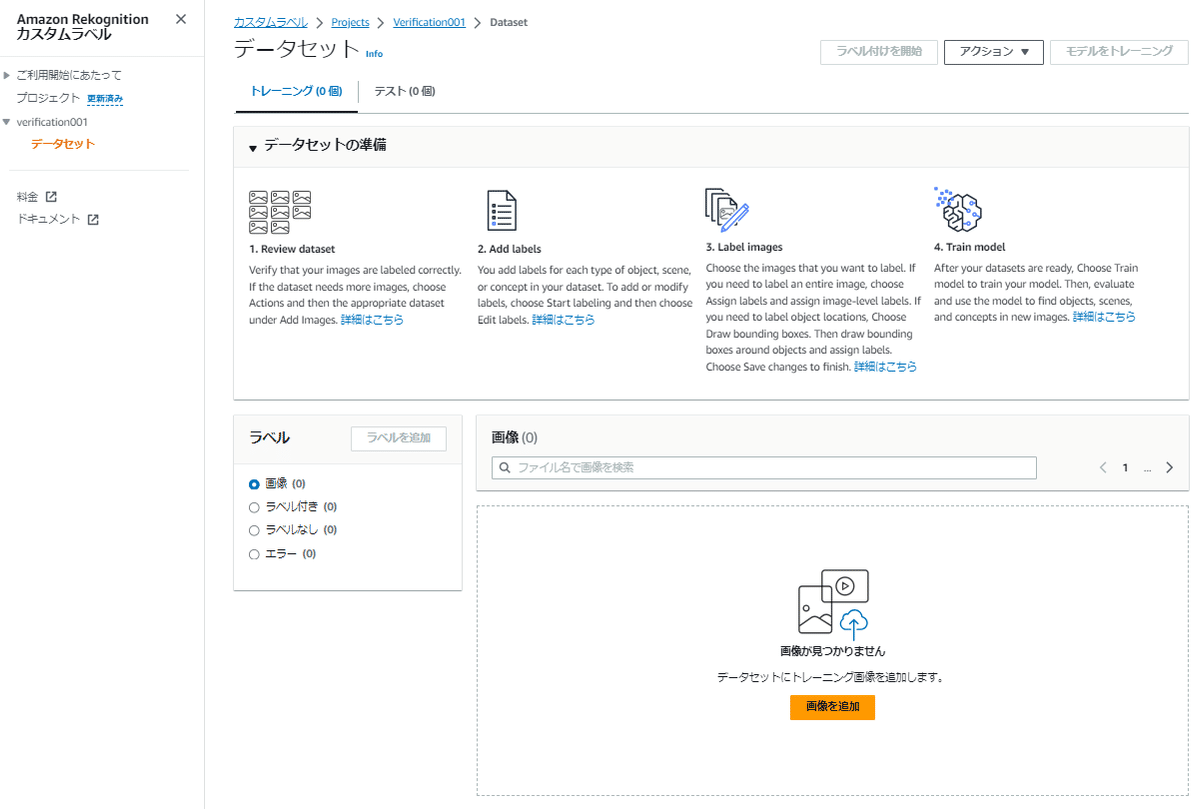
データセットの設定画面の上部には「トレーニング」と「テスト」のタブがあります。
それぞれのタブの画面で「トレーニングデータセット」の画像と「テストデータセット」の画像の追加や確認ができます。
次に、ここへアップロードする画像の用意をしましょう。
■カスタムラベルの設定②
(トレーニング画像の準備)
実際にトレーニングで使用する画像は、前項で用意したデータセットにアップロードして画像の中にあるパンを指定してラベルと紐づけてトレーニングを行っていきます。
データセットでのモデルのトレーニングには、以下の2種類の画像が必要となりますので、この画像をあらかじめ用意しておきます。
<トレーニングデータセット用の画像>
実際に画像を識別するために画像を登録して識別のラベリングを設定するトレーニング用の画像
トレーニングには合計10枚以上の画像を用意することを推奨
質の高い画像を大量に使用することで、学習モデルの品質を向上させることができる
<テストデータセット用の画像>
トレーニングされたモデルが正しいラベルをどの程度正確に予測するかを検証するためのテスト用の画像
トレーニング後にテストデータセットで登録した画像が、指定したラベルにどれくらいの信頼性のパーセンテージで判別されたかを確認できます。
テストデータセットの画像は、トレーニングデータセットにある画像であってはなりません。
Rekognitionカスタムモデルでは、使用する画像には以下ような推奨条件があります。
<推奨画像>
画像の形式はPNG形式かJPEG形式の画像である必要があります。
さまざまな照明、背景、解像度でオブジェクトを表示する画像を使用してください。
オクルージョン(手前にある物体が後ろにある物体を隠す状態)によって、検出したいオブジェクトが見えにくくならないようにしてください。
背景とのコントラストが十分である画像を使用します。
明るくシャープな画像を使用します。
オブジェクトが画像の大部分を占める画像を使用してください。
トレーニングデータセットとテストデータセットの画像に関して
トレーニングデータセットの画像には、少なくとも10枚の画像を使用する必要があります
テストデータセットの画像は、トレーニングデータセットにある画像であってはなりません。
トレーニングデータセットの画像とテストデータセットの画像は、モデルに使用したい画像と似ている必要があります。
テストデータセットの画像は、モデルが分析するようにトレーニングされているオブジェクト、シーン、およびコンセプトを含める必要があります。
今回はパン屋さんでのAIレジでの利用を想定しているので、以下のようなトレーニング用のパン画像を用意してみています。
<想定のシチュエーション>
お店では白いトレーを使うことを想定
トレーニング用のパン画像の背景も白い背景のものを用意レジではトレーにのせたパンを上からスキャン(撮影)することを想定
トレーニング用のパン画像はすべて上から撮影したものを使用お店のパンの形やデザインは日によって大きく変わることない想定
実際にお店で販売しているパンによる画像を用意

これらをふまえて、トレーニングデータセット用のパン画像をパンの種類(ラベル)毎に10画像ずつ(合計30画像)を用意してみました。
(実際にサービスで使用しているカスタムラベル環境ではもう少し多めの数の画像を使ってトレーニングしています)
焼きそばパン:10画像
メロンパン:10画像
あんぱん:10画像

なお、テストデータセット用で用意する画像は、トレーニングされたモデルが正しいラベルをどの程度正確に予測するかを検証するための画像になるので、トレーニングデータセットでは使用していない別の画像をぞれぞれの種類で最低でも1画像ずつ(合計3画像)を用意します。

次に、これらの用意した画像をデータセットにアップロードしていきます。
■カスタムラベルの設定③
(ラベルの紐づけとトレーニングの実施)
ここから、データセット画面よりトレーニング用の画像やテスト画像をアップロードして、分類のラベリングをしてトレーニングを行います。
1.トレーニングデータセットのセットアップ
まず、トレーニングデータセットにトレーニング画像をアップロードしていきます。
右上の「アクション」メニューから「トレーニングデータセットに画像を追加」を選択します。
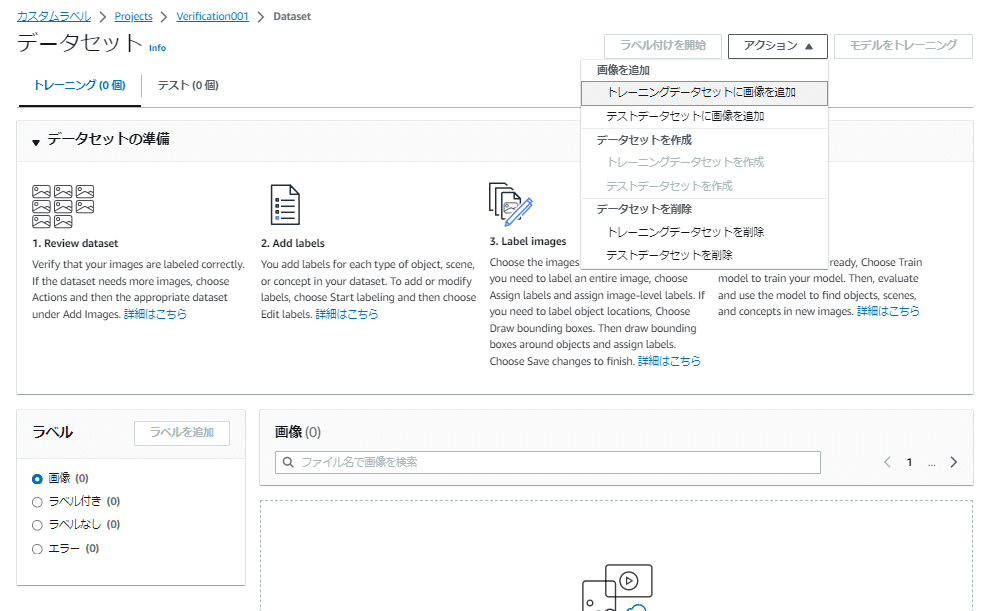
<データセットへの画像のアップロード>
「トレーニングデータセットに画像を追加」画面よりとトレーニングの画像をデータセットに追加していきます。
この画面から一度に登録できる画像は最大30個までなので、30個以上の場合は数回に分けて画像追加を行います。
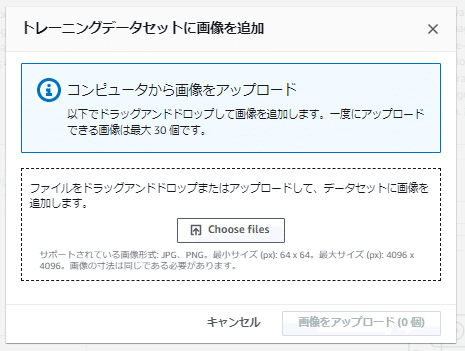
「トレーニングデータセットに画像を追加」画面の「Choose file」ボタンからアップロードする画像を選択するか、「Choose file」ボタンあたりにアップロードする画像をドッグアンドドロップすると、以下のような形でアップロードする画像が選択された状態になります。
「画像をアップロード」ボタンを押すとアップロードが開始されます。
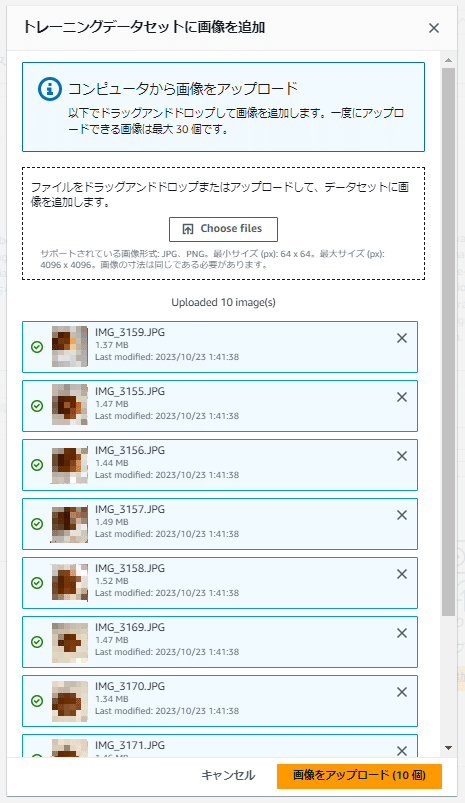
アップロードした画像は以下のように「データセット」の「トレーニング」タブ画面上に表示され、「トレーニング」タブ部分には登録された画像の個数が表示されます。
まずは、トレーニングに使用する画像をこの流れですべてアップロードしていきます。
今回は3種類のパンの画像をそれぞれ10枚づつ(合計30枚)の画像をトレーニング用としてアップロードしました。
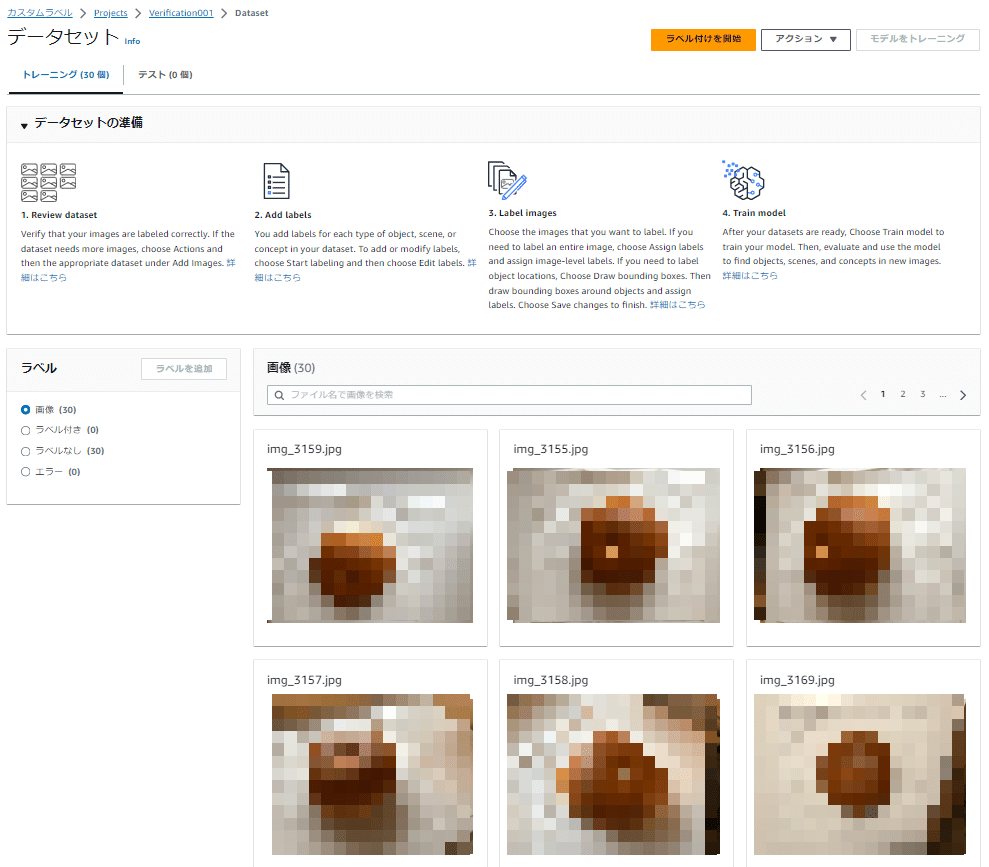
すべての画像のアップデートが完了したら、今回判定するラベルの種類をデータセットに追加します。
<ラベルの追加>
右上の「ラベル付けを開始」ボタンを押すと、「ラベル」欄にある「ラベルを追加」のボタンがアクティブになります。
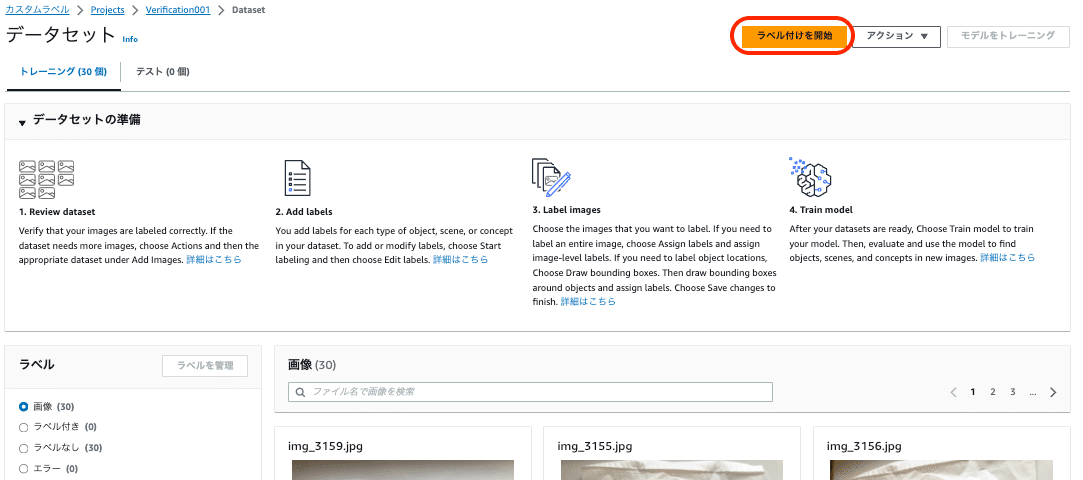
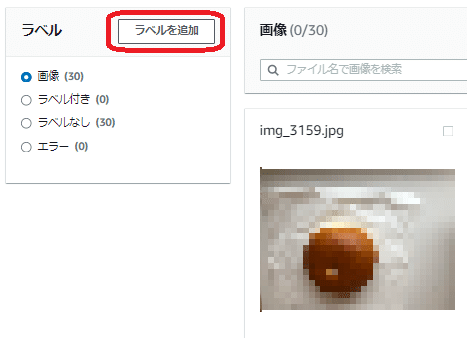
アクティブになった「ラベルを追加」のボタンを押すと「ラベルを管理」ウィンドウが表示されます。
「ラベルを追加」のチェックボックスを選択して、「新しいラベル名」欄にラベルとして登録する名称を入れて「ラベルを追加」ボタンを押し、必要なラベルを追加していきます。
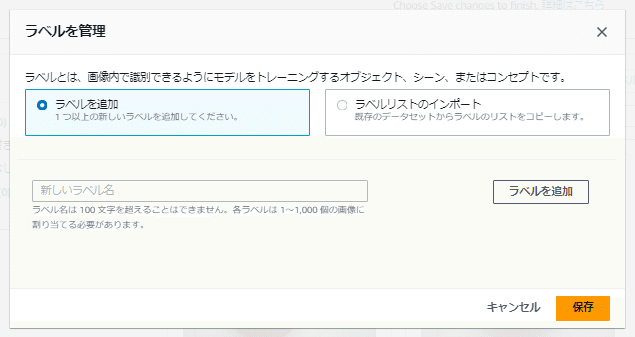
今回は3種類のパンをラベル判定するため、3種類のパンのラベルを追加作成します。
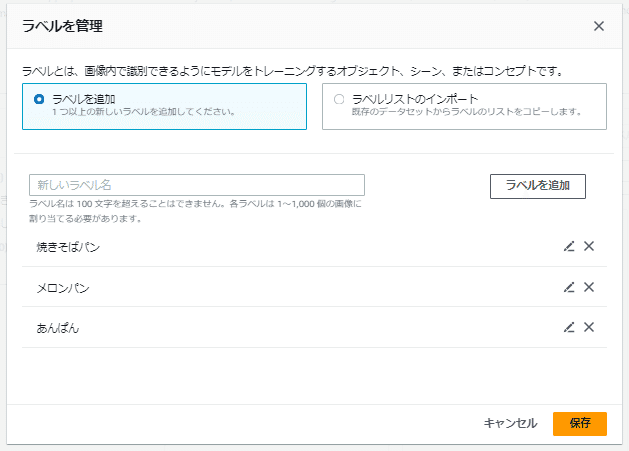
「保存」ボタンを押すと以下のように「ラベル」欄に追加したラベル名が表示されます。
ラベルの追加ができたら、アップロードした画像に境界ボックスをセットしてラベルを紐づけていきます。
<画像のオブジェクトに境界ボックスとラベルを紐づけ>
画像内のオブジェクト(パン)にラベルを紐づけるには、バウンディングボックスエディタ(画像に境界ボックスの描画をするエディタ)にて画像の中のオブジェクトに境界ボックス(バウンディングボックス)を描画してラベルを割り当てていきます。
モデルに画像内のオブジェクトの位置を検出させたい場合は、オブジェクトが何で、画像内のどこにあるかを特定する必要があります。バウンディングボックスは、画像内のオブジェクトを分離するボックスです。バウンディングボックスを使用して、同じ画像内のさまざまなオブジェクトを検出するようにモデルをトレーニングします。オブジェクトを識別するには、バウンディングボックスにラベルを割り当てます。
今回、パンの種類を検出するモデルをトレーニングするので、アップロードした画像に写っているオブジェクト(パン)を囲うように境界ボックスを描画し、その境界ボックスにパンの種類(この画像だと「あんぱん」)のラベルを紐づけてていきます。

実際に画像のオブジェクトへラベルを紐づける手順を説明します。
前述の「ラベルの追加」の続きで「ラベル付けを開始」の画面の状態であれば、各画像の右上のチェックボックスが表示されています。
画像のチェックボックスにチェックをいれて、データセット画面の右上にある「境界ボックスを描画」ボタンを押してください。
(チェックボックスが表示されていな場合は、データセット画面の右上に表示されている「ラベル付けを開始」ボタンを押してください)
画像のチェックボックスにチェックを入れれるのは「画像」欄に表示されている画像のみのため、一度に最大で9枚の画像までしかチェックができません。
画像が9枚以上ある場合は数回に分けてチェックを入れてバウンディングボックスエディタで設定してください。
「境界ボックスを描画」ボタンをクリックすると、以下のように「バウンディングボックスエディタ」画面に切り替わります。
バウンディングボックスエディタ上には一枚ずつ画像が表示するので、1枚ずつ紐づけをしていきます。
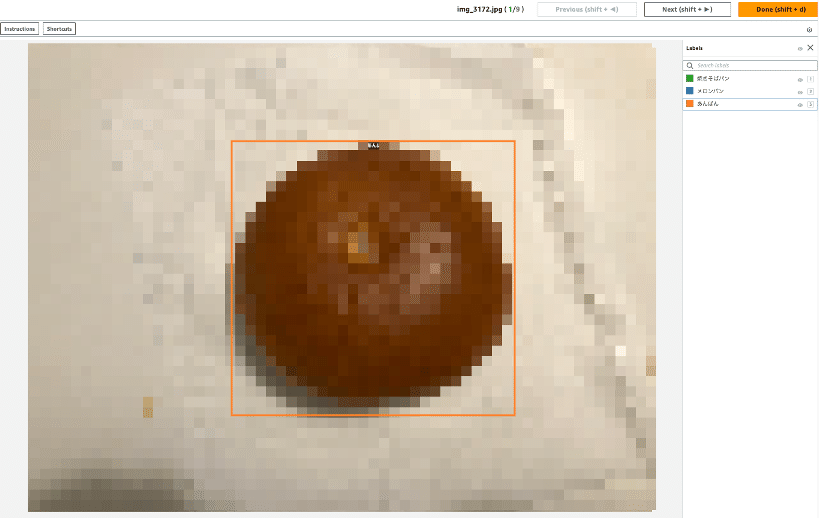
まず、下部にある描画ボックスを描画するアイコンを選択し、左側のLabelsから紐づけるラベル(パンの種類)を選択します。

あんぱんの画像なのでラベルは「あんぱん」を選択し、
下の描画ボックスを描画するアイコンを選択
該当のラベルを選択して画像上にカーソルのポインタを持っていくと、ポインタの位置を中心に縦と横の点線が十字で表示されます。
この縦と横の線を目安にオブジェクト(あんぱん)の近くを四角(境界ボックス)で囲むように描画していきます。

四角で囲む画像の左上の角の位置にポインタを置き、マウスの左ボタンを押して右下の角の位置へ移動させていく
ラベルの色の線による境界ボックスが現れるので、オブジェクトの周りを境界ボックスが囲むように描き、囲めたら左ボタンを離します。
境界ボックスの枠はできるだけオブジェクト(パン)に近づけて囲うようにしてください
これで該当のラベルでの境界ボックスをオブジェクトに紐づけされた状態になります。
境界ボックスは描画後も線をクリックして移動させたり大きさを変更することが可能です。
境界ボックスを削除したい場合は、線をクリックしてキーボードでdeleteを押せば削除できます。
以下のように一つ目の画像のオブジェクトに境界ボックスを描画できたら右上に並ぶボタンのうち「Next」ボタンを押して、同じように次の画像の境界ボックスを描画していきます。
(「Next」ボタンなどはコンソールのヘッダに隠れて見えていない場合があるので、画面をスクロールすると表示します)
すべての画像(最大9画像)の境界ボックスの設定が完了したら、右上の「Done」ボタンを押すことでバウンディングボックスエディタが終了します。
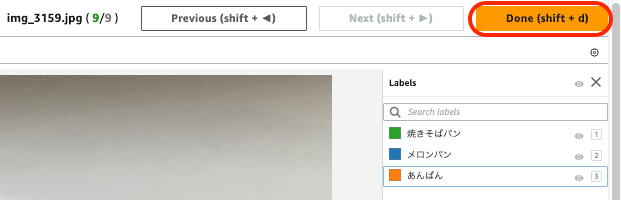
データセット画面に戻るとチェックボックスで選択した画像のオブジェクトに境界ボックスが描かれ、画像キャプションの下に紐づけたラベルが表示されます。

今回の例ではトレーニング用の画像が30枚あるので、残り21枚の画像も同様の手順でチェックボックスで選択して画像のオブジェクトに境界ボックスとラベルと紐づけていきました。
<データセットへの反映>
すべての画像のオブジェクトに境界ボックスとラベルの紐付けが完了したら、データセット画面の右上の「ラベル付けを完了」を押してデータセットへ反映します。
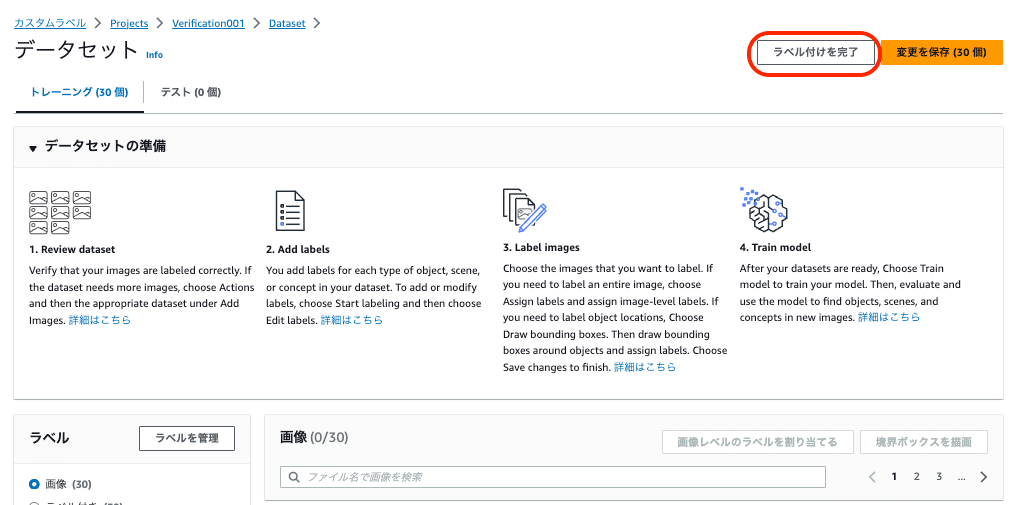
カスタムラベルのデータセットの更新が開始すると以下のようにヘッダーバーが表示します。


画像量や変更量によるものと思いますが、今回は画像点数が少ないからか数十秒で完了しました。
データセットの更新が完了して「ラベル」欄を確認すると、ラベル付きが「30」となり、各ラベルも「10」ずつカウントされた状態になります。
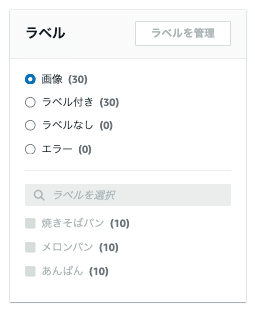
続いて、テスト用の画像でテストデータセットをしていきます。
2.テストデータセットのセットアップ
トレーニングされたモデルが正しいラベルをどの程度正確に予測するかを検証するため、今回設定したラベルのオブジェクトが写っている画像(ただし、トレーニングデータセットで使用した画像とは別のもの)をラベルの種類ごとに最低1点ずつ(合計3種類)用意し、ほぼトレーニングデータセットのセットアップと同じ手順で境界ボックスをセットしていきます。
(テストデータセットのセットアップでは、ラベルの種類は登録されているので「<ラベルの追加>」の工程は不要です)
データセットへの画像のアップロード
データセット画面の右上の「アクション」メニューから「テストデータセットに画像を追加」を選択してテスト用画像をアップロード
画像に境界ボックスとラベルを紐づけ
「テスト」タブの「画像」表示画面で「ラベル付けを開始」ボタンを押し、境界ボックスを設定するテスト画像のチェックボックスを選択
データセット画面の右上にある「境界ボックスを描画」ボタンを押して、バウンディングボックスエディタ画面に切り替え
バウンディングボックスエディタですべての画像で境界ボックスを指定してラベルと紐づけ
テストデータセットへの反映
データセット画面で右上の「ラベル付けを完了」ボタンを押して、テストデータセットへの反映が完了
データセットの「テスト」タブ画面を選択してテストデータセット画面に切り替え、右上の「アクション」メニューから「テストデータセットに画像を追加」を選択することで、トレーニングデータセットのセットアップと同じ流れでテストデータセットの画像アップロードが開始されます。
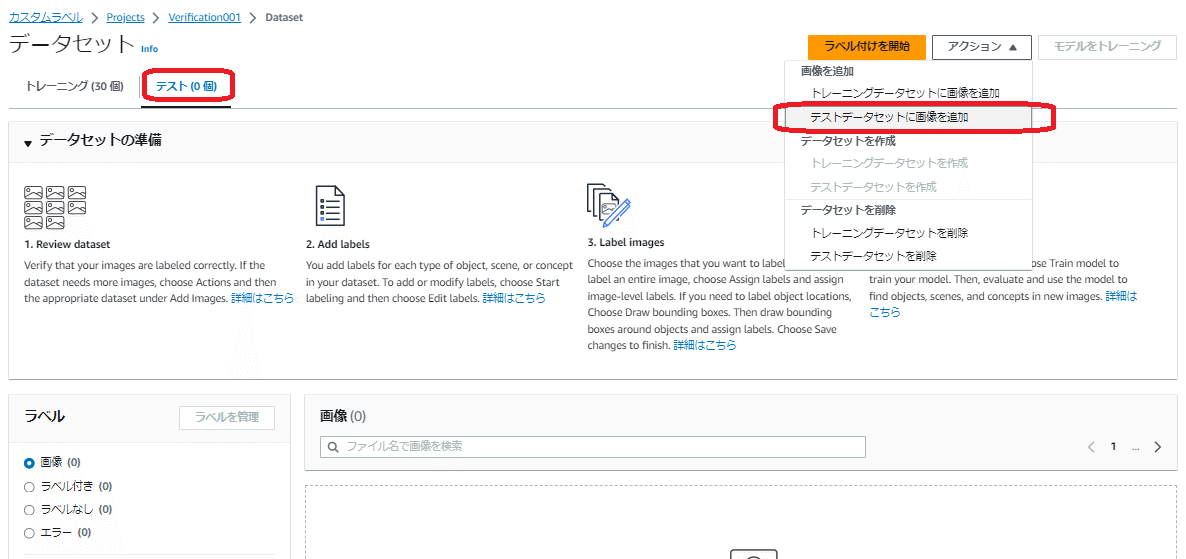
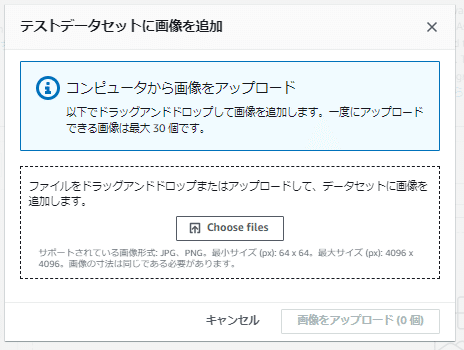
「テストデータセットに画像を追加」画面が表示
ついては「1.トレーニングデータセットのセットアップ」の工程と同じように画像をアップロードして、境界ボックスとラベルの紐づけを行ってテストデータセットへの反映を完了させてください。
テストデータセットのセットアップでは、使用するラベルはトレーニングデータセット時に追加設定済みなので、「<ラベルの追加>」の作業は不要です。
テストデータセットへのセットアップが完了すると、「ラベル」欄にテストデータセットでアップロードした画像3つでラベル付きが「3」となり、各ラベルも「1」ずつカウントされた状態になります。
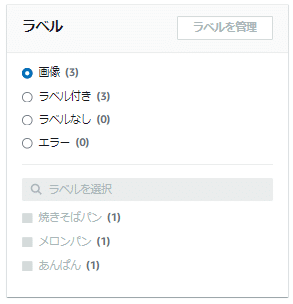
これでテストデータセットのセットアップが完了しました。
3.トレーニングの実施(モデルのトレーニング)
トレーニングデータセットとテストデータセットのセットアップが完了すると、「データセット」画面の右上の「モデルをトレーニング」ボタンがアクティブになります。
このボタンを押すことで、モデルのトレーニングが実施できます。
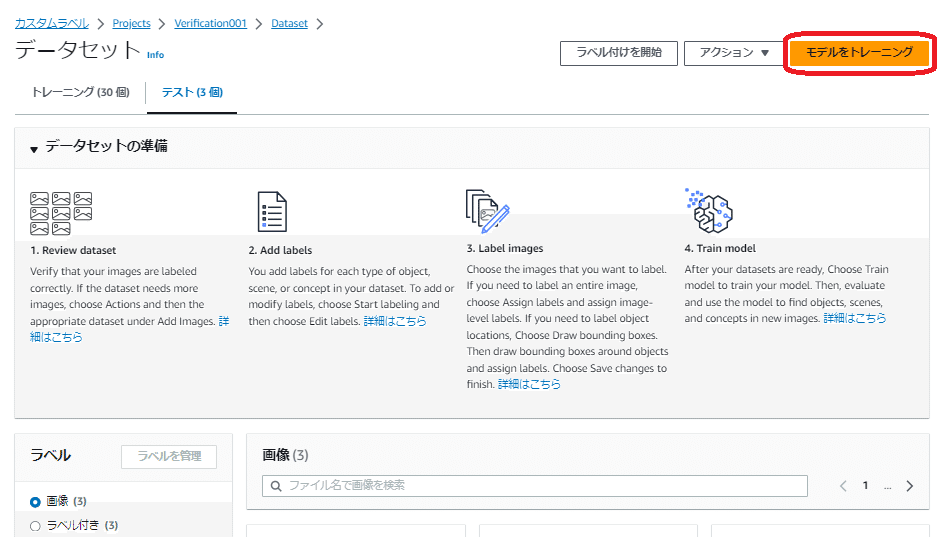
「モデルをトレーニング」ボタンを押すと、「モデルをトレーニング」画面が表示されます。
以下の設定をして右下の「モデルをトレーニング」ボタンを押します。
「トレーニングの詳細」の「プロジェクトを選択」では今回作成したプロジェクト名を選択します
(選択するとプロジェクトのARNが表示された状態になります)「タグ」は任意で必要に応じて指定してください
デフォルトでは画像データはAWS が所有し管理するキーで暗号化されますが、AWSアカウント側(AWS利用者側)の個別のキー(KMSのCMK)で暗号化させたい場合は「イメージデータの暗号化」の「暗号化設定をカスタマイズする (高度)」をチェックして用意してあるAWS KMSキーを選択してください
個別のキー(KMSのCMK)を利用する場合は、対象のCMKのキーポリシー設定や実行するユーザやロールのIAMポリシーで対象のCMKへの許可ポリシーを設定しておく必要があります
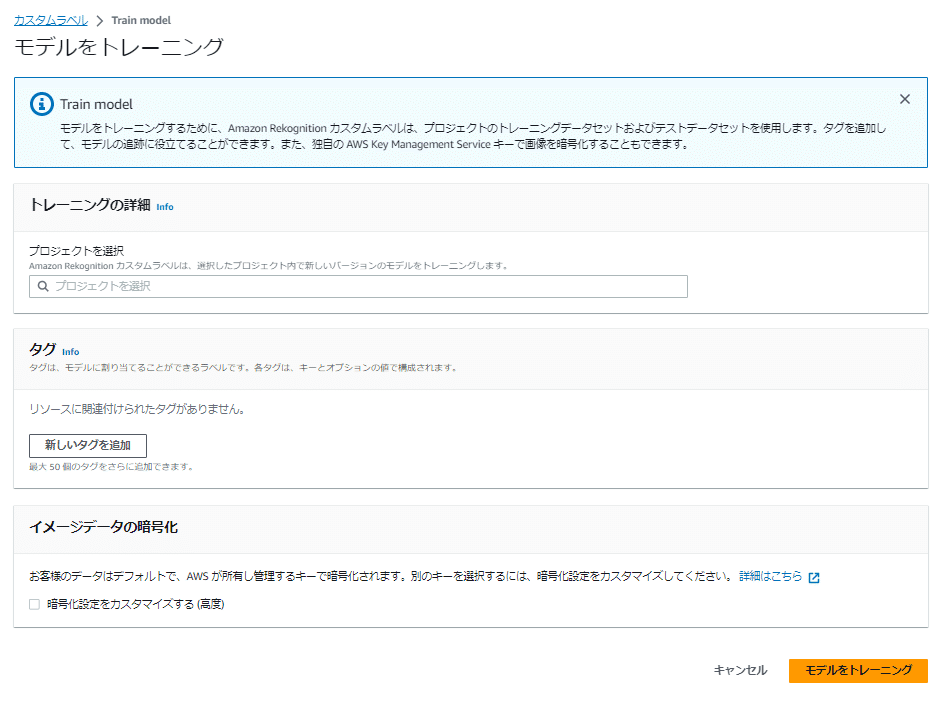
「モデルをトレーニング」ボタンを押すと以下の内容の確認ウィンドウが表示されます。
通常、トレーニングの完了までに 30 分から 24 時間かかります。
モデルを正常にトレーニングするのに要した時間と、モデルの実行時間に対して課金されます。
モデルのトレーニングが失敗した場合、料金は発生しません。
トレーニングにかかる料金についてはこちらを参考にしてください。
ちなみに今回の画像数やラベル内容でトレーニング開始から完了までの時間はおおよそ30分ほどでした。
問題がなければ「モデルをトレーニング」ボタンを押してください。
トレーニングが開始します。
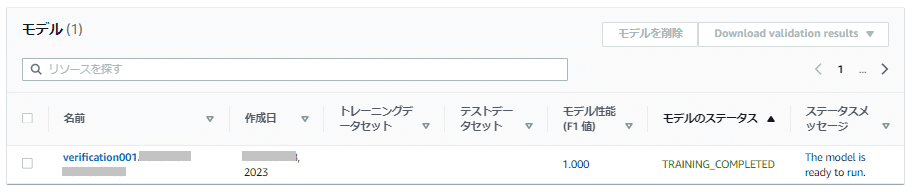
トレーニングが開始されると、作成したプロジェクトの画面で「モデル」欄に実施したトレーニングの「モデル」の情報が表示されます。
モデル欄には「<プロジェクト名>-<トレーニング実施日>T<トレーニング実施時刻>」のようなフォーマットの名称でモデルが作成されています。
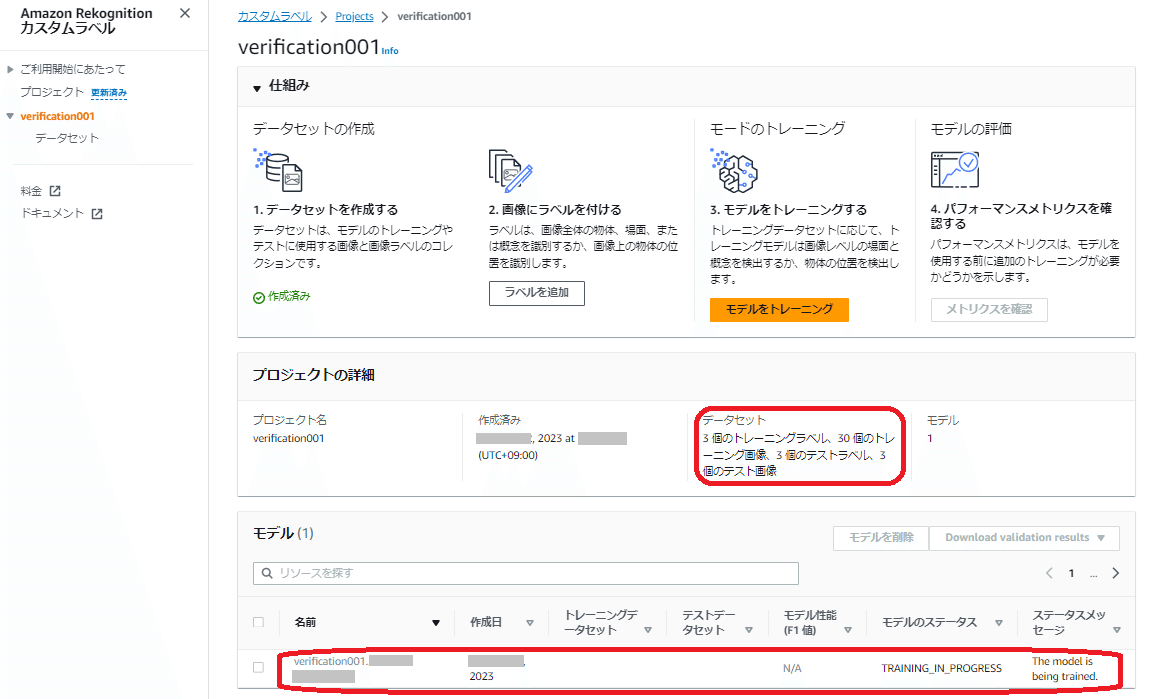
「モデル」にはトレーニング開始したモデル名やトレーニングの状況を表示
トレーニング完了までは「モデルのステータス」は「TRAINING_IN_PROGRESS(トレーニング中)」の状態ですが、正常にトレーニングが完了すると「TRAINING_COMPLETED(トレーニング完了)」になります。
「モデルのステータス」が「TRAINING_FAILED(トレーニング失敗)」となった場合は、「失敗したモデルトレーニングのデバッグ」を参考に内容を確認してください。
「TRAINING_COMPLETED(トレーニング完了)」になるとモデル名がリンク表記となるので、このモデル名をクリックするとモデルの詳細や評価結果などを確認できます。
ちなみに今回の画像数やラベル内容でトレーニングの時間はおおよそ30分ほどでした
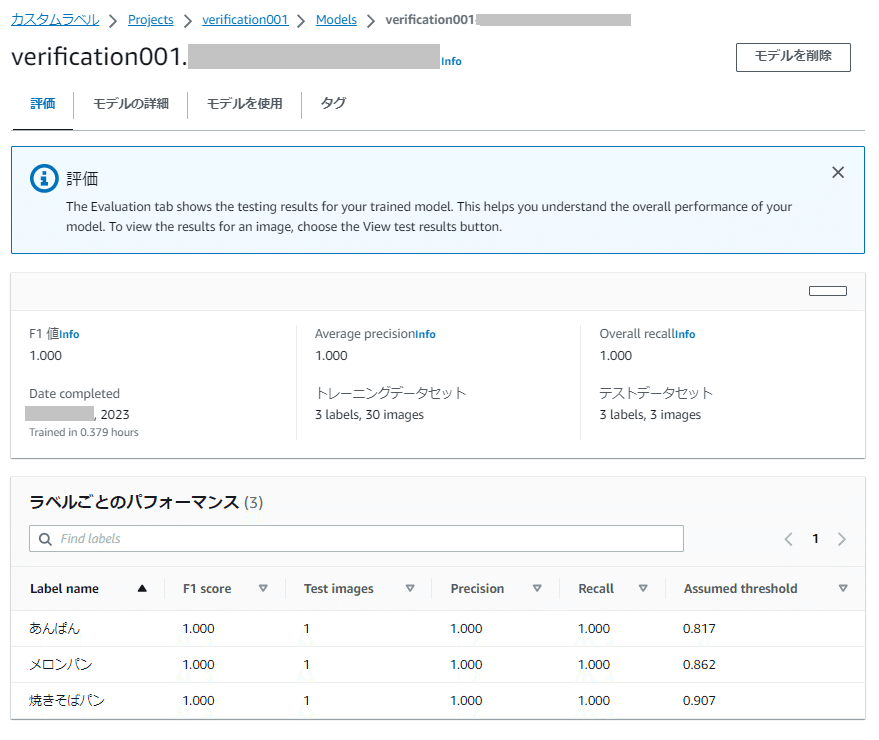
「ラベルごとのパフォーマンス」欄では、各ラベルごとの評価のメトリクスが確認できます。
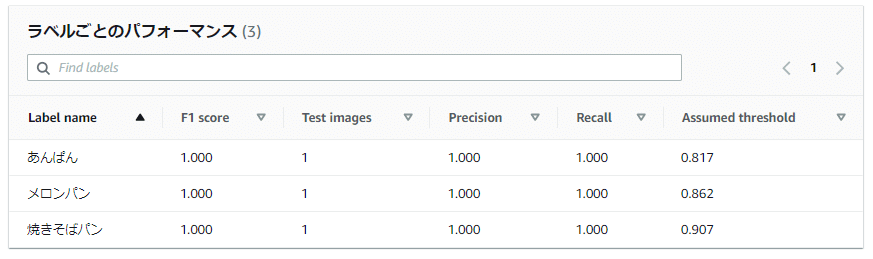
それぞれのメトリクス(F1 score、Precision、Recall、Assumed threshold)の意味については、以下を参考にしてください。
このメトリクスのうち「Assumed threshold(想定しきい値)」については、この後テストセットによる評価結果とあわせて説明します。
これにてAmazon Rekognition カスタムラベルでの学習モデルが完成しました。

できあがった時はうれしかったよ!
■テストデータセットの評価結果を見てみよう
テストデータセットでトレーニングで評価した結果(テスト結果)は「モデル」画面の「評価」タブ画面にある隠しボタンのような四角いボタンを押すと表示されます(コンソールの言語が「日本語」の場合)。
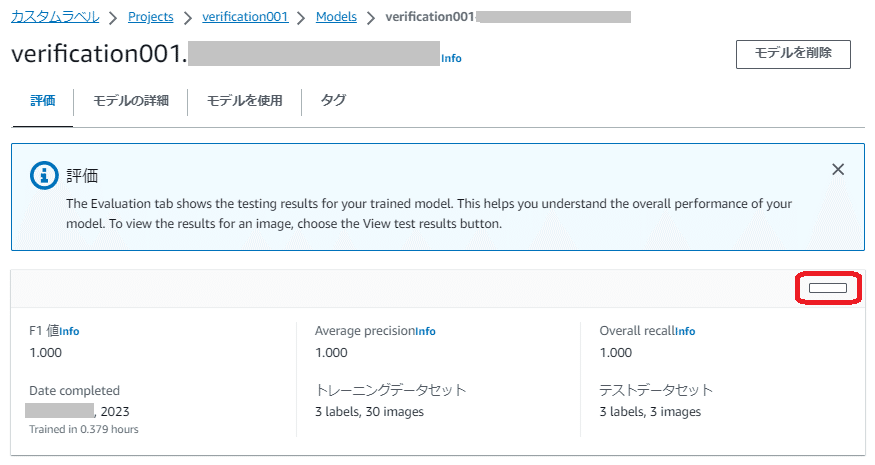
コンソールの言語を「English(US)」にするとボタン名が「View test results」と表示されます。
ここではトレーニングされた学習モデルをテストデータセットの画像で分析した結果を確認できます。
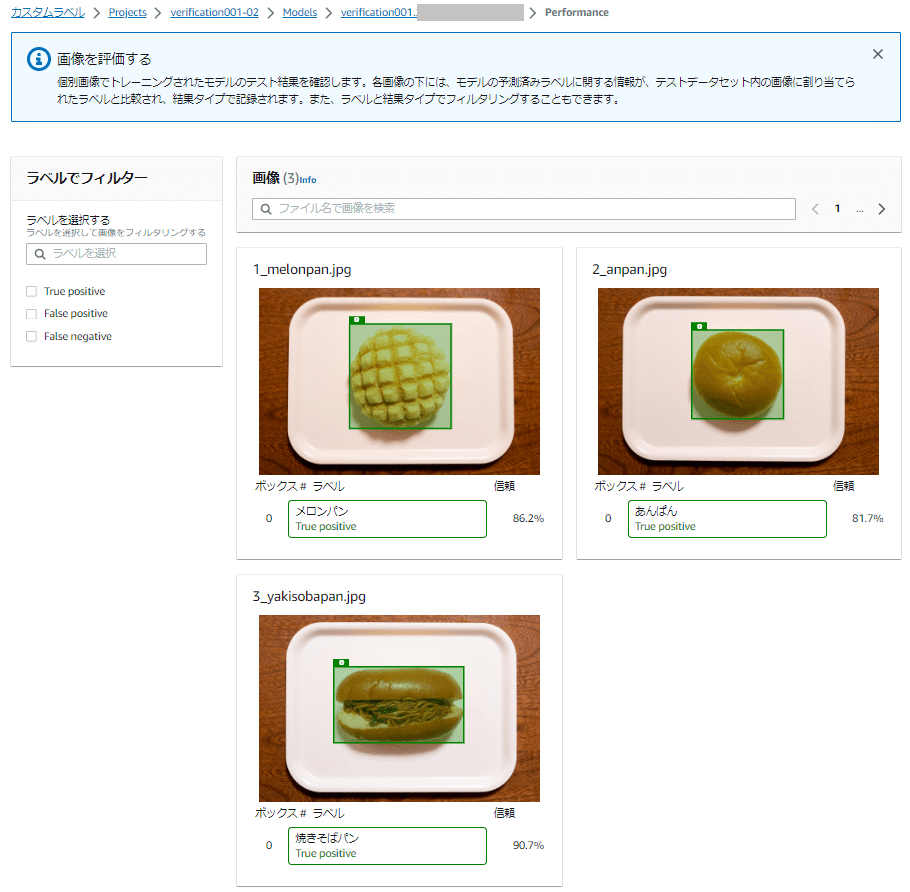
テスト画像の下には、テストデータセットのセットアップで指定した境界ボックスのラベルによる分析結果が表示されます。
テストデータセットの画像のオブジェクトでは、境界ボックスとラベル(ボックス# ラベル)で以下のような評価結果を返します。
True Positive(真陽性)
テストデータセットで割り当てられたラベルがモデルによって正しく識別されたことを示します
Palse Positive(偽陽性)
テスト画像にラベル付けしていないラベルがモデルで予測されたことを示します
False Negative(偽陰性)
テスト画像に存在するとマークしたラベルがモデルで予測されなかったことを示します。
「信頼」列で表示されている「Confidence(信頼度)」のスコアは、テスト画像のオブジェクトで検出されたラベルによる、モデルの予測の確実性を定量化する値です。
それぞれの画像のオブジェクトで検出されたラベルの「信頼度」のスコアは以下のようになりました。
あんぱん: 81.7% (0.817)
メロンパン: 86.2% (0.862)
焼きそばパン: 90.7% (0.907)
今回の結果だと、例えば「焼きそばパン」のテスト画像で検出されたオブジェクト(パン)は「焼きそばパン」である可能性が90.7%であるということになります。
先ほどのモデルの「評価」タブで表示されていた「ラベルごとのパフォーマンス」欄の「Assumed threshold(想定しきい値)」の値を見てみると、テスト結果の「Confidence(信頼度)」スコアと同じ数値(パーセンテージを数値で表記)になっていることがわかります。
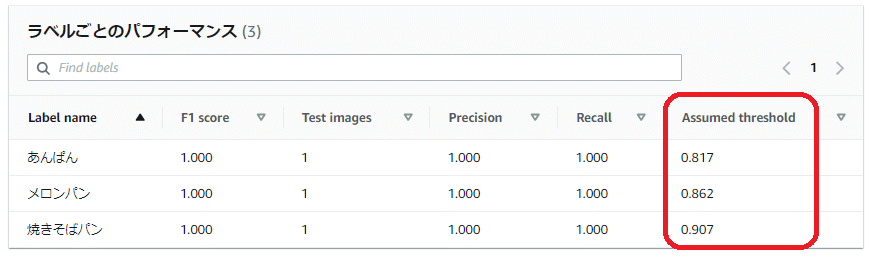
この「Assumed threshold(想定しきい値)」は、モデルトレーニング中にテストデータセットで達成された最高の F1 スコア(いずれも1.000)に基づいて自動で計算されます。
想定しきい値
Amazon Rekognition カスタムラベルは、各カスタムラベルの想定しきい値 (0-1) を自動的に計算します。カスタムラベルの想定しきい値を設定することはできません。各ラベルの想定しきい値は、この値を超えると予測が真陽性または偽陽性とカウントされます。テストデータセットに基づいて設定されます。想定される閾値は、モデルトレーニング中にテストデータセットで達成された最高の F1 スコアに基づいて計算されます。
次回、この「Assumed threshold(想定しきい値)」によるパンの判定についてと、学習モデルの判定精度の改善について紹介します。
■Amazon Rekognition カスタムラベルの料金について
最後にAmazon Rekognition カスタムラベルの料金についてまとめておきます。
Amazon Rekognition カスタムラベルでは以下の2種類の料金が発生します。
トレーニング時間の料金
カスタムモデルを構築する際に、データセットで実施したモデルのトレーニングを開始してから完了するまでの時間で料金が発生します。
トレーニング: 1.37USD/時間(1リソースあたり)
1 分単位での課金で最低 1 分から課金されます
今回はトレーニングはセットアップ時に実施したモデルのトレーニングのみで、そのトレーニング時間がおおよそ30分だったので単純計算で 0.685USD となりますが、AWSのサイトには「モデルをもっと高速にトレーニングするために複数のコンピューティングリソースを並行して実行する」場合があるそうで、そのリソース分が乗算される場合もあるようでした(どのようにリソース数が決まるのかはよくわかりませんでした・・・)。
なお、初回のモデルのトレーニング以外にも、トレーニング画像を追加したりなどで再トレーニングする場合など「モデルのトレーニング」を実施する都度、この費用が発生します。
推論時間の料金
カスタムラベルの使って画像処理するためには、作成した学習モデルを開始させる必要があります(次回、学習モデルを開始する方法について紹介します)。
この学習モデルの開始~停止までの時間(学習モデルが稼働している時間)で費用が発生します。
また、学習モデルのスループットは、推論ユニット(inference unit/コンピューティングリソースの数)の数を増やすことでスループットも増えますが、この数によって料金が積算されます。
推論:4.00USD/時間(1推論ユニットあたり)
1 分単位での課金で最低 1 分から課金されます
推論ユニットについてはこちらを参照ください。
料金に関する詳しいことはこちらを参考にしてください。
■最後に
かなりボリューミーな内容になってしまった・・・。
簡単に利用できると書いたけど、(ほぼ)はじめてAmazon Rekognition カスタムラベルに直接ふれたのでいろいろ手こずってしまいました。
しかし、今回の経験でAmazon Rekognition カスタムラベルはかなり理解できたと思います(判定や精度を上げるための計算など難しいことはもうちょっと学習する必要はありそうですが・・・)。
これで自分が好きなAWSサービスは「AWS クーポンコード」と「Amazon Rekognition カスタムラベル」になりました。

ただ、この環境で実際にパンの写真を画像分析しましたが、まさかの結果が・・・
この続きは、次回の投稿で!!!
こんないろんな経験ができる今の会社はとてもいい会社なので、興味のある方はこちらも是非見てみてください。